 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022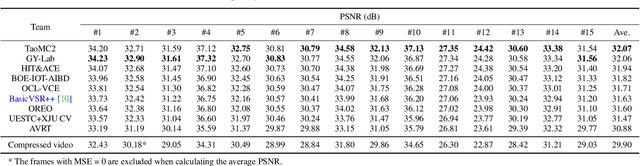
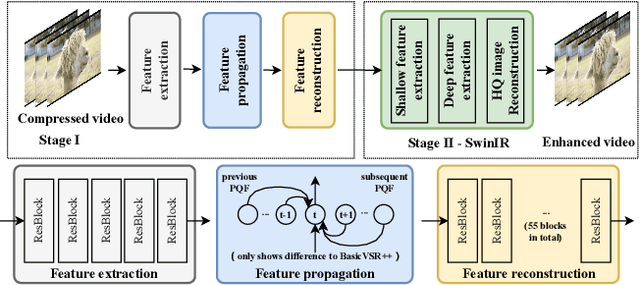
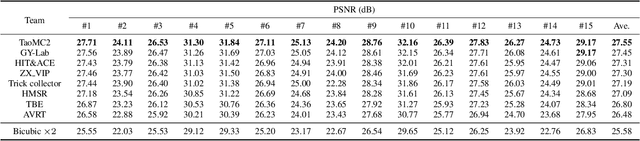

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.
Fine-grained Identity Preserving Landmark Synthesis for Face Reenactment
Oct 12, 2021
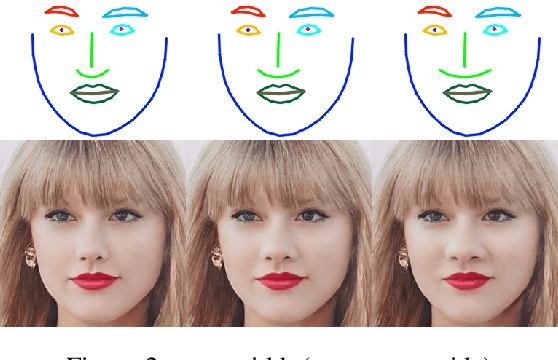
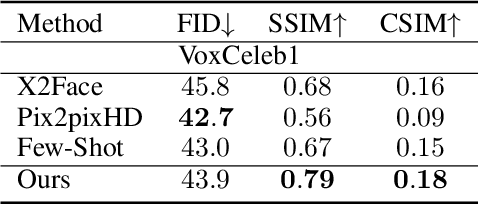
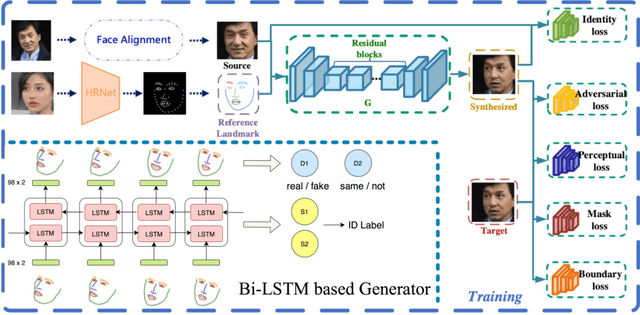
Recent face reenactment works are limited by the coarse reference landmarks, leading to unsatisfactory identity preserving performance due to the distribution gap between the manipulated landmarks and those sampled from a real person. To address this issue, we propose a fine-grained identity-preserving landmark-guided face reenactment approach. The proposed method has two novelties. First, a landmark synthesis network which is designed to generate fine-grained landmark faces with more details. The network refines the manipulated landmarks and generates a smooth and gradually changing face landmark sequence with good identity preserving ability. Second, several novel loss functions including synthesized face identity preserving loss, foreground/background mask loss as well as boundary loss are designed, which aims at synthesizing clear and sharp high-quality faces. Experiments are conducted on our self-collected BeautySelfie and the public VoxCeleb1 datasets. The presented qualitative and quantitative results show that our method can reenact fine-grained higher quality faces with good ID-preserved appearance details, fewer artifacts and clearer boundaries than state-of-the-art works. Code will be released for reproduction.
Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer
Jun 07, 2021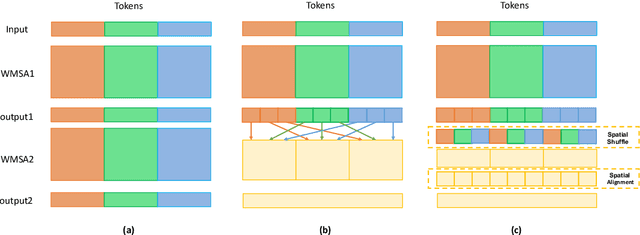
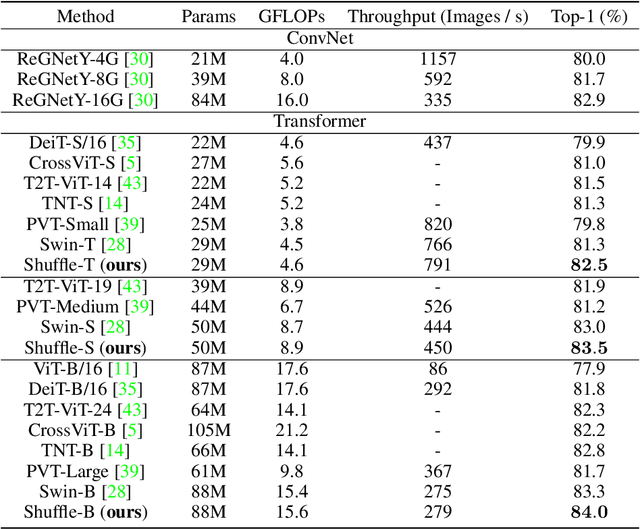

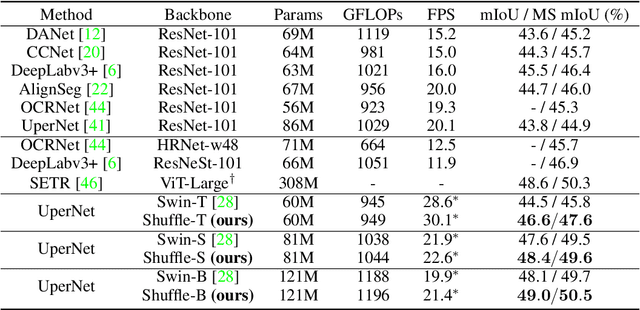
Very recently, Window-based Transformers, which computed self-attention within non-overlapping local windows, demonstrated promising results on image classification, semantic segmentation, and object detection. However, less study has been devoted to the cross-window connection which is the key element to improve the representation ability. In this work, we revisit the spatial shuffle as an efficient way to build connections among windows. As a result, we propose a new vision transformer, named Shuffle Transformer, which is highly efficient and easy to implement by modifying two lines of code. Furthermore, the depth-wise convolution is introduced to complement the spatial shuffle for enhancing neighbor-window connections. The proposed architectures achieve excellent performance on a wide range of visual tasks including image-level classification, object detection, and semantic segmentation. Code will be released for reproduction.