 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Non-decoupling of Supervised Fine-tuning and Reinforcement Learning in Post-training
Jan 12, 2026Post-training of large language models routinely interleaves supervised fine-tuning (SFT) with reinforcement learning (RL). These two methods have different objectives: SFT minimizes the cross-entropy loss between model outputs and expert responses, while RL maximizes reward signals derived from human preferences or rule-based verifiers. Modern reasoning models have widely adopted the practice of alternating SFT and RL training. However, there is no theoretical account of whether they can be decoupled. We prove that decoupling is impossible in either order: (1) SFT-then-RL coupling: RL increases SFT loss under SFT optimality and (2) RL-then-SFT coupling: SFT lowers the reward achieved by RL. Experiments on Qwen3-0.6B confirm the predicted degradation, verifying that SFT and RL cannot be separated without loss of prior performance in the post-training
AdaptCLIP: Adapting CLIP for Universal Visual Anomaly Detection
May 15, 2025



Universal visual anomaly detection aims to identify anomalies from novel or unseen vision domains without additional fine-tuning, which is critical in open scenarios. Recent studies have demonstrated that pre-trained vision-language models like CLIP exhibit strong generalization with just zero or a few normal images. However, existing methods struggle with designing prompt templates, complex token interactions, or requiring additional fine-tuning, resulting in limited flexibility. In this work, we present a simple yet effective method called AdaptCLIP based on two key insights. First, adaptive visual and textual representations should be learned alternately rather than jointly. Second, comparative learning between query and normal image prompt should incorporate both contextual and aligned residual features, rather than relying solely on residual features. AdaptCLIP treats CLIP models as a foundational service, adding only three simple adapters, visual adapter, textual adapter, and prompt-query adapter, at its input or output ends. AdaptCLIP supports zero-/few-shot generalization across domains and possesses a training-free manner on target domains once trained on a base dataset. AdaptCLIP achieves state-of-the-art performance on 12 anomaly detection benchmarks from industrial and medical domains, significantly outperforming existing competitive methods. We will make the code and model of AdaptCLIP available at https://github.com/gaobb/AdaptCLIP.
Towards Faster Graph Partitioning via Pre-training and Inductive Inference
Sep 01, 2024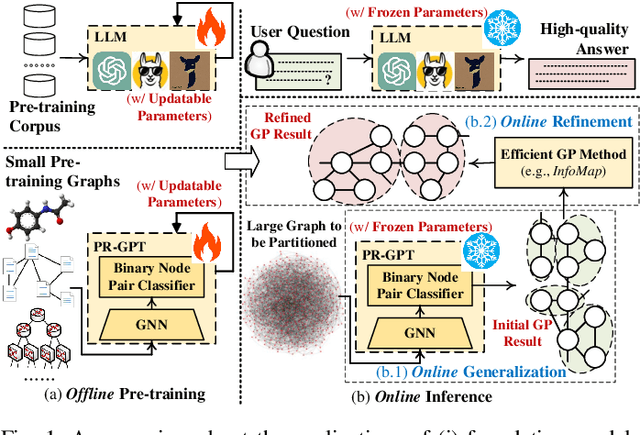
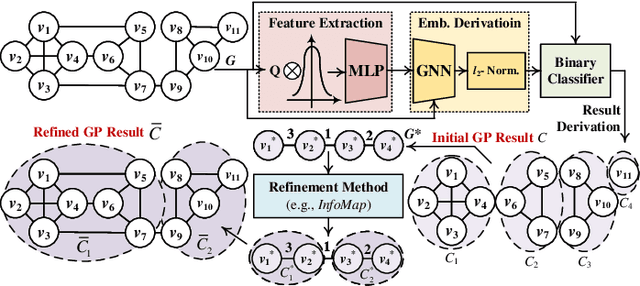
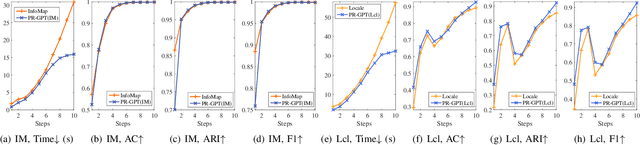
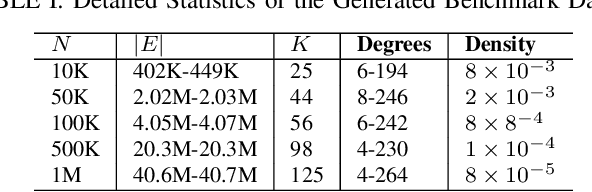
Graph partitioning (GP) is a classic problem that divides the node set of a graph into densely-connected blocks. Following the IEEE HPEC Graph Challenge and recent advances in pre-training techniques (e.g., large-language models), we propose PR-GPT (Pre-trained & Refined Graph ParTitioning) based on a novel pre-training & refinement paradigm. We first conduct the offline pre-training of a deep graph learning (DGL) model on small synthetic graphs with various topology properties. By using the inductive inference of DGL, one can directly generalize the pre-trained model (with frozen model parameters) to large graphs and derive feasible GP results. We also use the derived partition as a good initialization of an efficient GP method (e.g., InfoMap) to further refine the quality of partitioning. In this setting, the online generalization and refinement of PR-GPT can not only benefit from the transfer ability regarding quality but also ensure high inference efficiency without re-training. Based on a mechanism of reducing the scale of a graph to be processed by the refinement method, PR-GPT also has the potential to support streaming GP. Experiments on the Graph Challenge benchmark demonstrate that PR-GPT can ensure faster GP on large-scale graphs without significant quality degradation, compared with running a refinement method from scratch. We will make our code public at https://github.com/KuroginQin/PRGPT.
Fine-grained Identity Preserving Landmark Synthesis for Face Reenactment
Oct 12, 2021
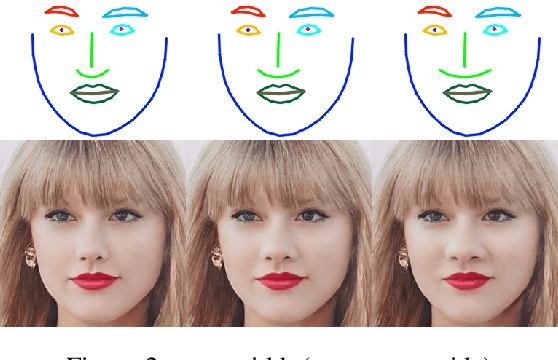
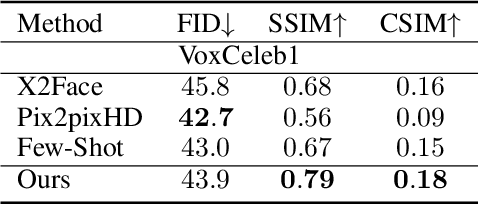
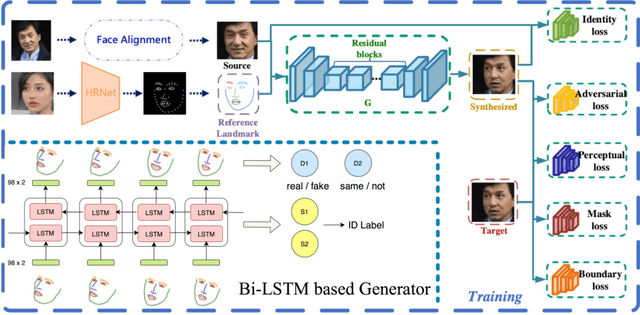
Recent face reenactment works are limited by the coarse reference landmarks, leading to unsatisfactory identity preserving performance due to the distribution gap between the manipulated landmarks and those sampled from a real person. To address this issue, we propose a fine-grained identity-preserving landmark-guided face reenactment approach. The proposed method has two novelties. First, a landmark synthesis network which is designed to generate fine-grained landmark faces with more details. The network refines the manipulated landmarks and generates a smooth and gradually changing face landmark sequence with good identity preserving ability. Second, several novel loss functions including synthesized face identity preserving loss, foreground/background mask loss as well as boundary loss are designed, which aims at synthesizing clear and sharp high-quality faces. Experiments are conducted on our self-collected BeautySelfie and the public VoxCeleb1 datasets. The presented qualitative and quantitative results show that our method can reenact fine-grained higher quality faces with good ID-preserved appearance details, fewer artifacts and clearer boundaries than state-of-the-art works. Code will be released for reproduction.
Object-aware Long-short-range Spatial Alignment for Few-Shot Fine-Grained Image Classification
Aug 30, 2021The goal of few-shot fine-grained image classification is to recognize rarely seen fine-grained objects in the query set, given only a few samples of this class in the support set. Previous works focus on learning discriminative image features from a limited number of training samples for distinguishing various fine-grained classes, but ignore one important fact that spatial alignment of the discriminative semantic features between the query image with arbitrary changes and the support image, is also critical for computing the semantic similarity between each support-query pair. In this work, we propose an object-aware long-short-range spatial alignment approach, which is composed of a foreground object feature enhancement (FOE) module, a long-range semantic correspondence (LSC) module and a short-range spatial manipulation (SSM) module. The FOE is developed to weaken background disturbance and encourage higher foreground object response. To address the problem of long-range object feature misalignment between support-query image pairs, the LSC is proposed to learn the transferable long-range semantic correspondence by a designed feature similarity metric. Further, the SSM module is developed to refine the transformed support feature after the long-range step to align short-range misaligned features (or local details) with the query features. Extensive experiments have been conducted on four benchmark datasets, and the results show superior performance over most state-of-the-art methods under both 1-shot and 5-shot classification scenarios.
Very Long Term Field of View Prediction for 360-degree Video Streaming
Feb 04, 2019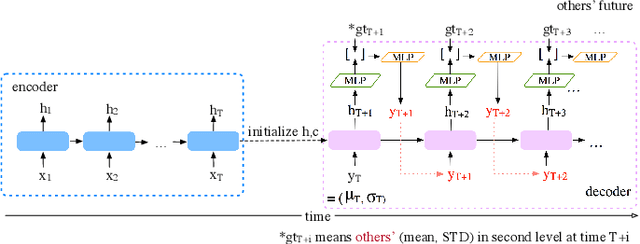
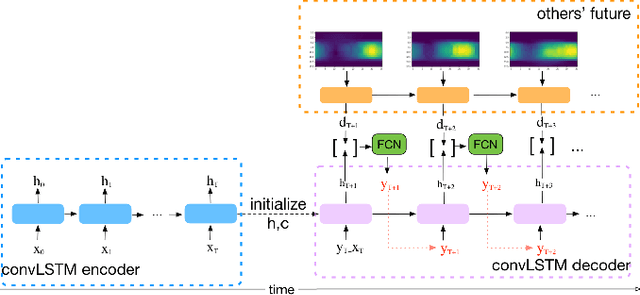
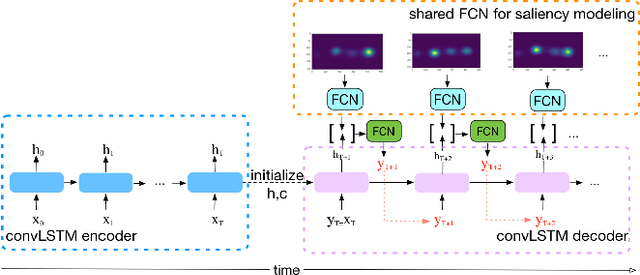
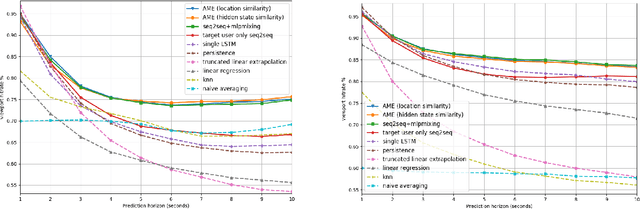
360-degree videos have gained increasing popularity in recent years with the developments and advances in Virtual Reality (VR) and Augmented Reality (AR) technologies. In such applications, a user only watches a video scene within a field of view (FoV) centered in a certain direction. Predicting the future FoV in a long time horizon (more than seconds ahead) can help save bandwidth resources in on-demand video streaming while minimizing video freezing in networks with significant bandwidth variations. In this work, we treat the FoV prediction as a sequence learning problem, and propose to predict the target user's future FoV not only based on the user's own past FoV center trajectory but also other users' future FoV locations. We propose multiple prediction models based on two different FoV representations: one using FoV center trajectories and another using equirectangular heatmaps that represent the FoV center distributions. Extensive evaluations with two public datasets demonstrate that the proposed models can significantly outperform benchmark models, and other users' FoVs are very helpful for improving long-term predictions.