 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISTA-Bench: Do Vision-Language Models Really Understand Visualized Text as Well as Pure Text?
Feb 04, 2026Vision-Language Models (VLMs) have achieved impressive performance in cross-modal understanding across textual and visual inputs, yet existing benchmarks predominantly focus on pure-text queries. In real-world scenarios, language also frequently appears as visualized text embedded in images, raising the question of whether current VLMs handle such input requests comparably. We introduce VISTA-Bench, a systematic benchmark from multimodal perception, reasoning, to unimodal understanding domains. It evaluates visualized text understanding by contrasting pure-text and visualized-text questions under controlled rendering conditions. Extensive evaluation of over 20 representative VLMs reveals a pronounced modality gap: models that perform well on pure-text queries often degrade substantially when equivalent semantic content is presented as visualized text. This gap is further amplified by increased perceptual difficulty, highlighting sensitivity to rendering variations despite unchanged semantics. Overall, VISTA-Bench provides a principled evaluation framework to diagnose this limitation and to guide progress toward more unified language representations across tokenized text and pixels. The source dataset is available at https://github.com/QingAnLiu/VISTA-Bench.
IIB-LPO: Latent Policy Optimization via Iterative Information Bottleneck
Jan 09, 2026Recent advances in Reinforcement Learning with Verifiable Rewards (RLVR) for Large Language Model (LLM) reasoning have been hindered by a persistent challenge: exploration collapse. The semantic homogeneity of random rollouts often traps models in narrow, over-optimized behaviors. While existing methods leverage policy entropy to encourage exploration, they face inherent limitations. Global entropy regularization is susceptible to reward hacking, which can induce meaningless verbosity, whereas local token-selective updates struggle with the strong inductive bias of pre-trained models. To address this, we propose Latent Policy Optimization via Iterative Information Bottleneck (IIB-LPO), a novel approach that shifts exploration from statistical perturbation of token distributions to topological branching of reasoning trajectories. IIB-LPO triggers latent branching at high-entropy states to diversify reasoning paths and employs the Information Bottleneck principle both as a trajectory filter and a self-reward mechanism, ensuring concise and informative exploration. Empirical results across four mathematical reasoning benchmarks demonstrate that IIB-LPO achieves state-of-the-art performance, surpassing prior methods by margins of up to 5.3% in accuracy and 7.4% in diversity metrics.
Regularizing Subspace Redundancy of Low-Rank Adaptation
Jul 28, 2025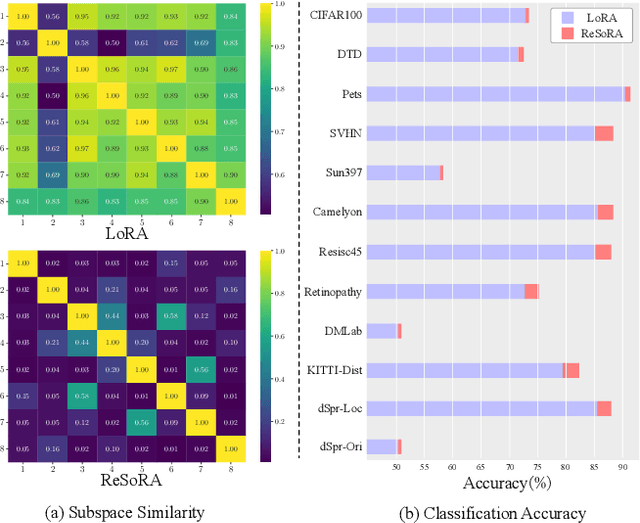
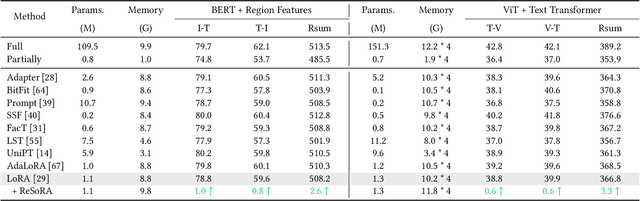
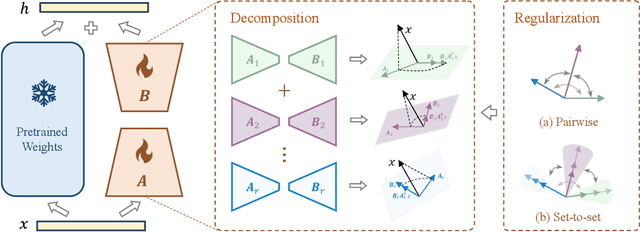
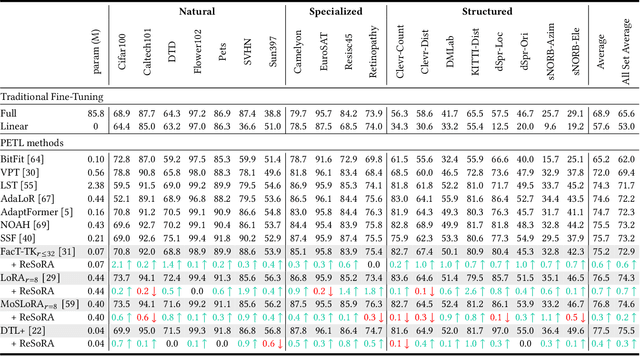
Low-Rank Adaptation (LoRA) and its variants have delivered strong capability in Parameter-Efficient Transfer Learning (PETL) by minimizing trainable parameters and benefiting from reparameterization. However, their projection matrices remain unrestricted during training, causing high representation redundancy and diminishing the effectiveness of feature adaptation in the resulting subspaces. While existing methods mitigate this by manually adjusting the rank or implicitly applying channel-wise masks, they lack flexibility and generalize poorly across various datasets and architectures. Hence, we propose ReSoRA, a method that explicitly models redundancy between mapping subspaces and adaptively Regularizes Subspace redundancy of Low-Rank Adaptation. Specifically, it theoretically decomposes the low-rank submatrices into multiple equivalent subspaces and systematically applies de-redundancy constraints to the feature distributions across different projections. Extensive experiments validate that our proposed method consistently facilitates existing state-of-the-art PETL methods across various backbones and datasets in vision-language retrieval and standard visual classification benchmarks. Besides, as a training supervision, ReSoRA can be seamlessly integrated into existing approaches in a plug-and-play manner, with no additional inference costs. Code is publicly available at: https://github.com/Lucenova/ReSoRA.
Expectation Confirmation Preference Optimization for Multi-Turn Conversational Recommendation Agent
Jun 17, 2025Recent advancements in Large Language Models (LLMs) have significantly propelled the development of Conversational Recommendation Agents (CRAs). However, these agents often generate short-sighted responses that fail to sustain user guidance and meet expectations. Although preference optimization has proven effective in aligning LLMs with user expectations, it remains costly and performs poorly in multi-turn dialogue. To address this challenge, we introduce a novel multi-turn preference optimization (MTPO) paradigm ECPO, which leverages Expectation Confirmation Theory to explicitly model the evolution of user satisfaction throughout multi-turn dialogues, uncovering the underlying causes of dissatisfaction. These causes can be utilized to support targeted optimization of unsatisfactory responses, thereby achieving turn-level preference optimization. ECPO ingeniously eliminates the significant sampling overhead of existing MTPO methods while ensuring the optimization process drives meaningful improvements. To support ECPO, we introduce an LLM-based user simulator, AILO, to simulate user feedback and perform expectation confirmation during conversational recommendations. Experimental results show that ECPO significantly enhances CRA's interaction capabilities, delivering notable improvements in both efficiency and effectiveness over existing MTPO methods.
Towards Efficient Key-Value Cache Management for Prefix Prefilling in LLM Inference
May 28, 2025The increasing adoption of large language models (LLMs) with extended context windows necessitates efficient Key-Value Cache (KVC) management to optimize inference performance. Inference workloads like Retrieval-Augmented Generation (RAG) and agents exhibit high cache reusability, making efficient caching critical to reducing redundancy and improving speed. We analyze real-world KVC access patterns using publicly available traces and evaluate commercial key-value stores like Redis and state-of-the-art RDMA-based systems (CHIME [1] and Sherman [2]) for KVC metadata management. Our work demonstrates the lack of tailored storage solution for KVC prefilling, underscores the need for an efficient distributed caching system with optimized metadata management for LLM workloads, and provides insights into designing improved KVC management systems for scalable, low-latency inference.
AdaptCLIP: Adapting CLIP for Universal Visual Anomaly Detection
May 15, 2025Universal visual anomaly detection aims to identify anomalies from novel or unseen vision domains without additional fine-tuning, which is critical in open scenarios. Recent studies have demonstrated that pre-trained vision-language models like CLIP exhibit strong generalization with just zero or a few normal images. However, existing methods struggle with designing prompt templates, complex token interactions, or requiring additional fine-tuning, resulting in limited flexibility. In this work, we present a simple yet effective method called AdaptCLIP based on two key insights. First, adaptive visual and textual representations should be learned alternately rather than jointly. Second, comparative learning between query and normal image prompt should incorporate both contextual and aligned residual features, rather than relying solely on residual features. AdaptCLIP treats CLIP models as a foundational service, adding only three simple adapters, visual adapter, textual adapter, and prompt-query adapter, at its input or output ends. AdaptCLIP supports zero-/few-shot generalization across domains and possesses a training-free manner on target domains once trained on a base dataset. AdaptCLIP achieves state-of-the-art performance on 12 anomaly detection benchmarks from industrial and medical domains, significantly outperforming existing competitive methods. We will make the code and model of AdaptCLIP available at https://github.com/gaobb/AdaptCLIP.
FT-Transformer: Resilient and Reliable Transformer with End-to-End Fault Tolerant Attention
Apr 03, 2025Transformer models leverage self-attention mechanisms to capture complex dependencies, demonstrating exceptional performance in various applications. However, the long-duration high-load computations required for model inference impose stringent reliability demands on the computing platform, as soft errors that occur during execution can significantly degrade model performance. Existing fault tolerance methods protect each operation separately using decoupled kernels, incurring substantial computational and memory overhead. In this paper, we propose a novel error-resilient framework for Transformer models, integrating end-to-end fault tolerant attention (EFTA) to improve inference reliability against soft errors. Our approach enables error detection and correction within a fully fused attention kernel, reducing redundant data access and thereby mitigating memory faults. To further enhance error coverage and reduce overhead, we design a hybrid fault tolerance scheme tailored for the EFTA, introducing for the first time: 1) architecture-aware algorithm-based fault tolerance (ABFT) using tensor checksum, which minimizes inter-thread communication overhead on tensor cores during error detection; 2) selective neuron value restriction, which selectively applies adaptive fault tolerance constraints to neuron values, balancing error coverage and overhead; 3) unified verification, reusing checksums to streamline multiple computation steps into a single verification process. Experimental results show that EFTA achieves up to 7.56x speedup over traditional methods with an average fault tolerance overhead of 13.9%.
Mind the Memory Gap: Unveiling GPU Bottlenecks in Large-Batch LLM Inference
Mar 11, 2025Large language models have been widely adopted across different tasks, but their auto-regressive generation nature often leads to inefficient resource utilization during inference. While batching is commonly used to increase throughput, performance gains plateau beyond a certain batch size, especially with smaller models, a phenomenon that existing literature typically explains as a shift to the compute-bound regime. In this paper, through an in-depth GPU-level analysis, we reveal that large-batch inference remains memory-bound, with most GPU compute capabilities underutilized due to DRAM bandwidth saturation as the primary bottleneck. To address this, we propose a Batching Configuration Advisor (BCA) that optimizes memory allocation, reducing GPU memory requirements with minimal impact on throughput. The freed memory and underutilized GPU compute capabilities can then be leveraged by concurrent workloads. Specifically, we use model replication to improve serving throughput and GPU utilization. Our findings challenge conventional assumptions about LLM inference, offering new insights and practical strategies for improving resource utilization, particularly for smaller language models.
KARST: Multi-Kernel Kronecker Adaptation with Re-Scaling Transmission for Visual Classification
Feb 10, 2025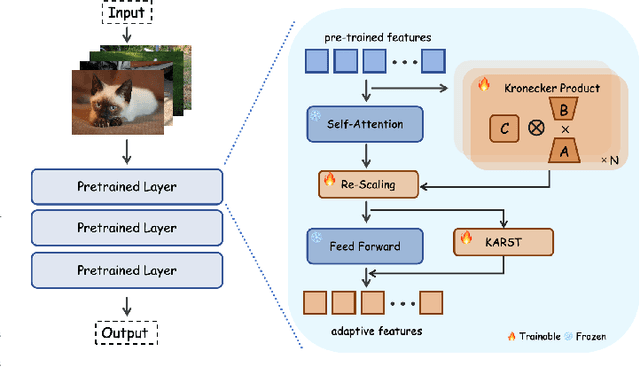
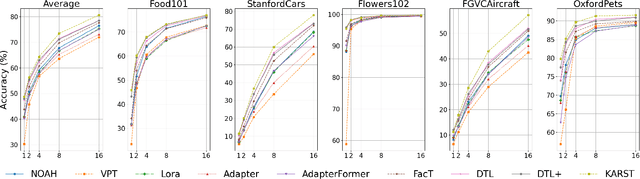
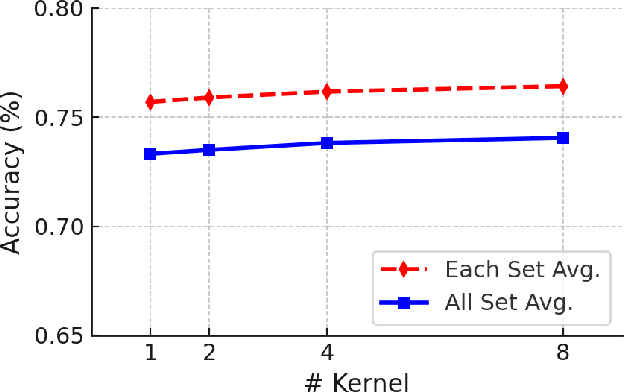
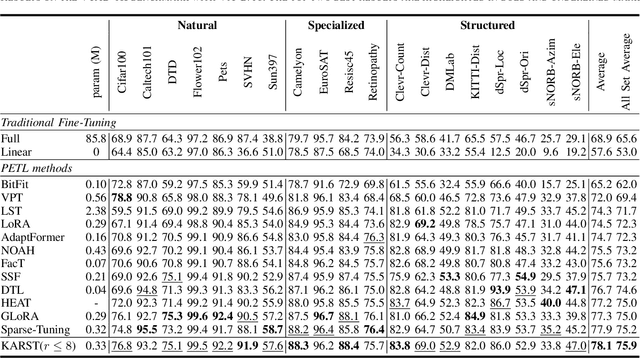
Fine-tuning pre-trained vision models for specific tasks is a common practice in computer vision. However, this process becomes more expensive as models grow larger. Recently, parameter-efficient fine-tuning (PEFT) methods have emerged as a popular solution to improve training efficiency and reduce storage needs by tuning additional low-rank modules within pre-trained backbones. Despite their advantages, they struggle with limited representation capabilities and misalignment with pre-trained intermediate features. To address these issues, we introduce an innovative Multi-Kernel Kronecker Adaptation with Re-Scaling Transmission (KARST) for various recognition tasks. Specifically, its multi-kernel design extends Kronecker projections horizontally and separates adaptation matrices into multiple complementary spaces, reducing parameter dependency and creating more compact subspaces. Besides, it incorporates extra learnable re-scaling factors to better align with pre-trained feature distributions, allowing for more flexible and balanced feature aggregation. Extensive experiments validate that our KARST outperforms other PEFT counterparts with a negligible inference cost due to its re-parameterization characteristics. Code is publicly available at: https://github.com/Lucenova/KARST.
Towards Pareto Optimal Throughput in Small Language Model Serving
Apr 04, 2024Large language models (LLMs) have revolutionized the state-of-the-art of many different natural language processing tasks. Although serving LLMs is computationally and memory demanding, the rise of Small Language Models (SLMs) offers new opportunities for resource-constrained users, who now are able to serve small models with cutting-edge performance. In this paper, we present a set of experiments designed to benchmark SLM inference at performance and energy levels. Our analysis provides a new perspective in serving, highlighting that the small memory footprint of SLMs allows for reaching the Pareto-optimal throughput within the resource capacity of a single accelerator. In this regard, we present an initial set of findings demonstrating how model replication can effectively improve resource utilization for serving SLMs.