 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximizing GPU Efficiency via Optimal Adapter Caching: An Analytical Approach for Multi-Tenant LLM Serving
Aug 11, 2025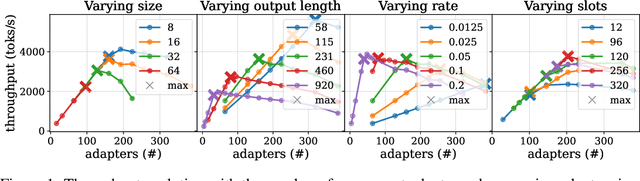
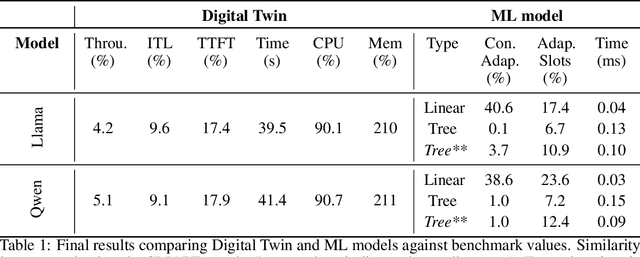
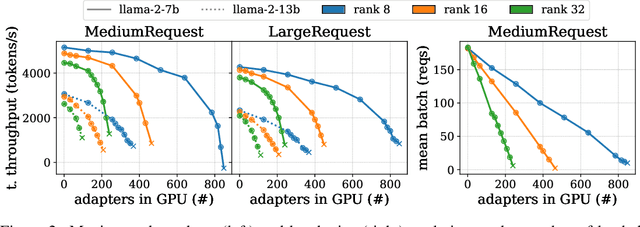
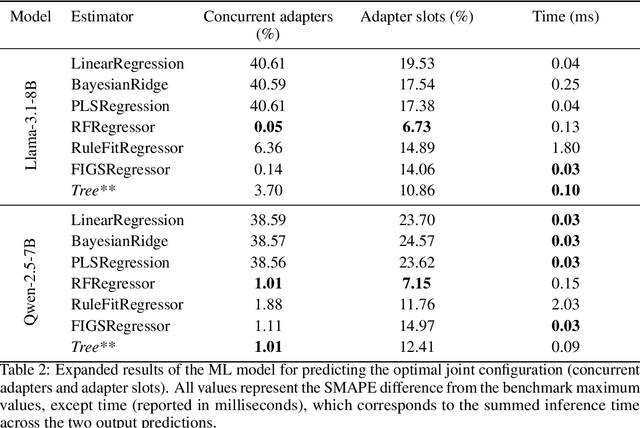
Serving LLM adapters has gained significant attention as an effective approach to adapt general-purpose language models to diverse, task-specific use cases. However, serving a wide range of adapters introduces several and substantial overheads, leading to performance degradation and challenges in optimal placement. To address these challenges, we present an analytical, AI-driven pipeline that accurately determines the optimal allocation of adapters in single-node setups. This allocation maximizes performance, effectively using GPU resources, while preventing request starvation. Crucially, the proposed allocation is given based on current workload patterns. These insights in single-node setups can be leveraged in multi-replica deployments for overall placement, load balancing and server configuration, ultimately enhancing overall performance and improving resource efficiency. Our approach builds on an in-depth analysis of LLM adapter serving, accounting for overheads and performance variability, and includes the development of the first Digital Twin capable of replicating online LLM-adapter serving systems with matching key performance metrics. The experimental results demonstrate that the Digital Twin achieves a SMAPE difference of no more than 5.5% in throughput compared to real results, and the proposed pipeline accurately predicts the optimal placement with minimal latency.
Mind the Memory Gap: Unveiling GPU Bottlenecks in Large-Batch LLM Inference
Mar 11, 2025Large language models have been widely adopted across different tasks, but their auto-regressive generation nature often leads to inefficient resource utilization during inference. While batching is commonly used to increase throughput, performance gains plateau beyond a certain batch size, especially with smaller models, a phenomenon that existing literature typically explains as a shift to the compute-bound regime. In this paper, through an in-depth GPU-level analysis, we reveal that large-batch inference remains memory-bound, with most GPU compute capabilities underutilized due to DRAM bandwidth saturation as the primary bottleneck. To address this, we propose a Batching Configuration Advisor (BCA) that optimizes memory allocation, reducing GPU memory requirements with minimal impact on throughput. The freed memory and underutilized GPU compute capabilities can then be leveraged by concurrent workloads. Specifically, we use model replication to improve serving throughput and GPU utilization. Our findings challenge conventional assumptions about LLM inference, offering new insights and practical strategies for improving resource utilization, particularly for smaller language models.
FRIDA: Free-Rider Detection using Privacy Attacks
Oct 07, 2024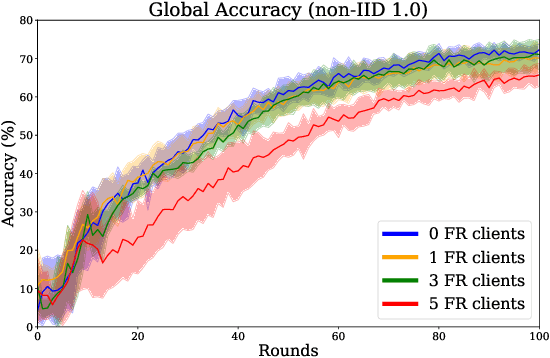
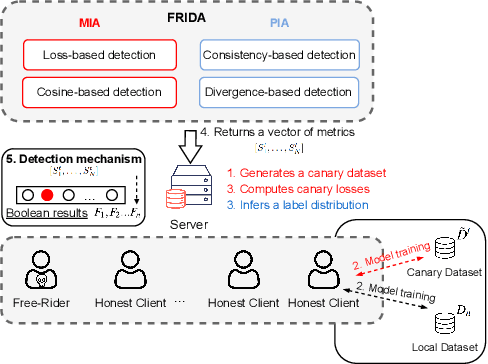
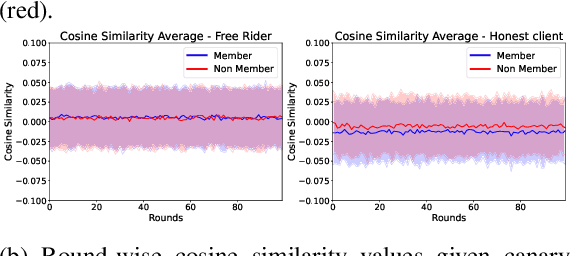
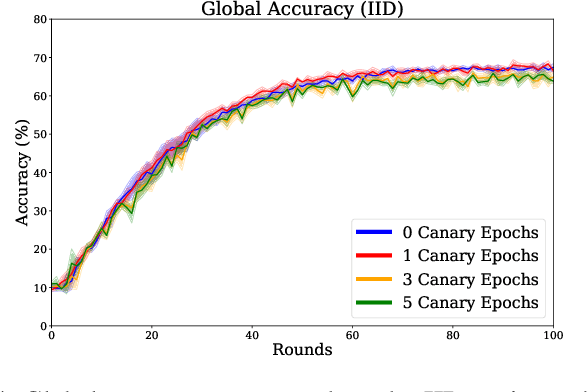
Federated learning is increasingly popular as it enables multiple parties with limited datasets and resources to train a high-performing machine learning model collaboratively. However, similarly to other collaborative systems, federated learning is vulnerable to free-riders -- participants who do not contribute to the training but still benefit from the shared model. Free-riders not only compromise the integrity of the learning process but also slow down the convergence of the global model, resulting in increased costs for the honest participants. To address this challenge, we propose FRIDA: free-rider detection using privacy attacks, a framework that leverages inference attacks to detect free-riders. Unlike traditional methods that only capture the implicit effects of free-riding, FRIDA directly infers details of the underlying training datasets, revealing characteristics that indicate free-rider behaviour. Through extensive experiments, we demonstrate that membership and property inference attacks are effective for this purpose. Our evaluation shows that FRIDA outperforms state-of-the-art methods, especially in non-IID settings.
Towards Pareto Optimal Throughput in Small Language Model Serving
Apr 04, 2024Large language models (LLMs) have revolutionized the state-of-the-art of many different natural language processing tasks. Although serving LLMs is computationally and memory demanding, the rise of Small Language Models (SLMs) offers new opportunities for resource-constrained users, who now are able to serve small models with cutting-edge performance. In this paper, we present a set of experiments designed to benchmark SLM inference at performance and energy levels. Our analysis provides a new perspective in serving, highlighting that the small memory footprint of SLMs allows for reaching the Pareto-optimal throughput within the resource capacity of a single accelerator. In this regard, we present an initial set of findings demonstrating how model replication can effectively improve resource utilization for serving SLMs.
Towards Unsupervised Fine-Tuning for Edge Video Analytics
Apr 14, 2021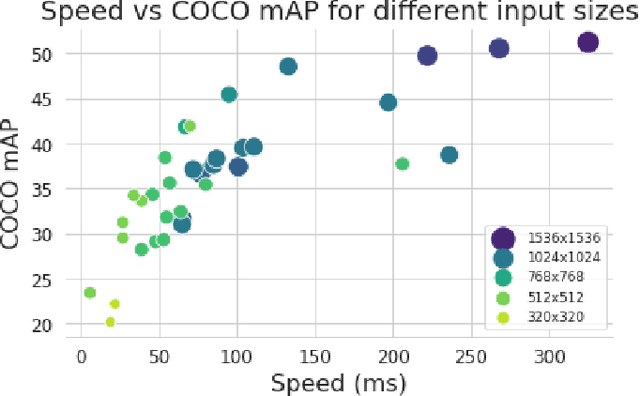
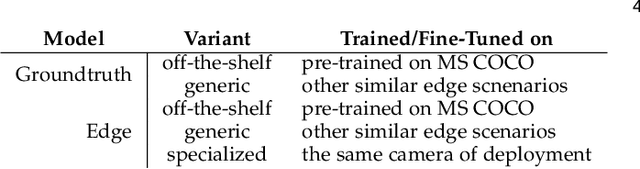
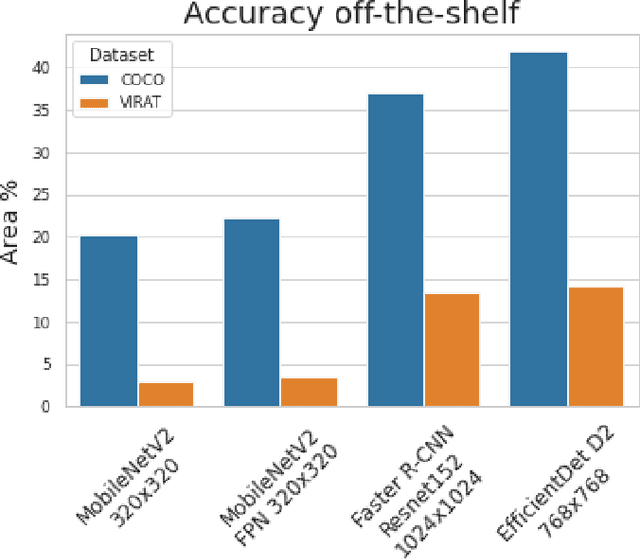
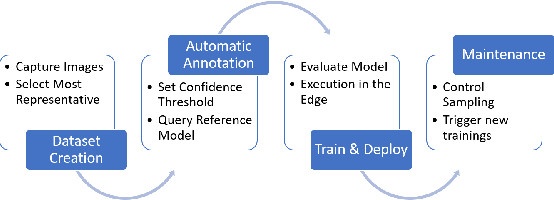
Judging by popular and generic computer vision challenges, such as the ImageNet or PASCAL VOC, neural networks have proven to be exceptionally accurate in recognition tasks. However, state-of-the-art accuracy often comes at a high computational price, requiring equally state-of-the-art and high-end hardware acceleration to achieve anything near real-time performance. At the same time, use cases such as smart cities or autonomous vehicles require an automated analysis of images from fixed cameras in real-time. Due to the huge and constant amount of network bandwidth these streams would generate, we cannot rely on offloading compute to the omnipresent and omnipotent cloud. Therefore, a distributed Edge Cloud must be in charge to process images locally. However, the Edge Cloud is, by nature, resource-constrained, which puts a limit on the computational complexity of the models executed in the edge. Nonetheless, there is a need for a meeting point between the Edge Cloud and accurate real-time video analytics. In this paper, we propose a method for improving accuracy of edge models without any extra compute cost by means of automatic model specialization. First, we show how the sole assumption of static cameras allows us to make a series of considerations that greatly simplify the scope of the problem. Then, we present Edge AutoTuner, a framework that implements and brings these considerations together to automate the end-to-end fine-tuning of models. Finally, we show that complex neural networks - able to generalize better - can be effectively used as teachers to annotate datasets for the fine-tuning of lightweight neural networks and tailor them to the specific edge context, which boosts accuracy at constant computational cost, and do so without any human interaction. Results show that our method can automatically improve accuracy of pre-trained models by an average of 21%.
Improving Maritime Traffic Emission Estimations on Missing Data with CRBMs
Sep 10, 2020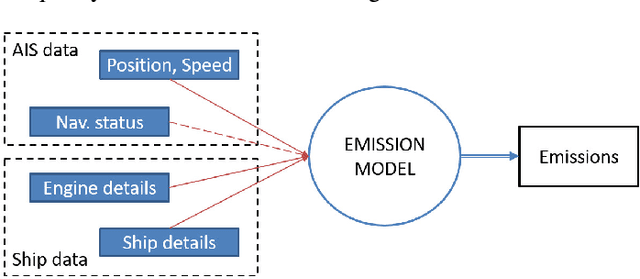
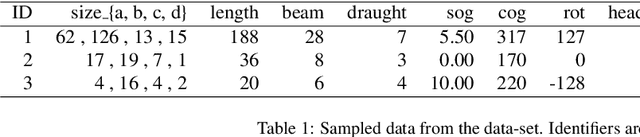
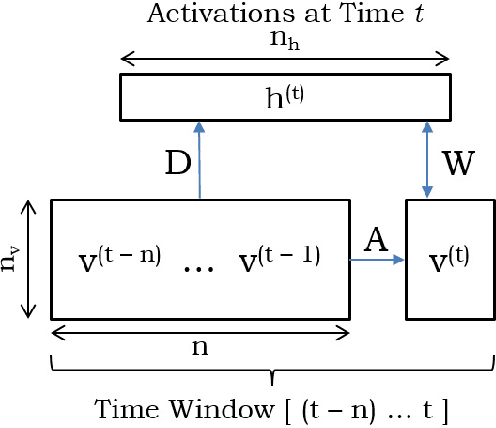
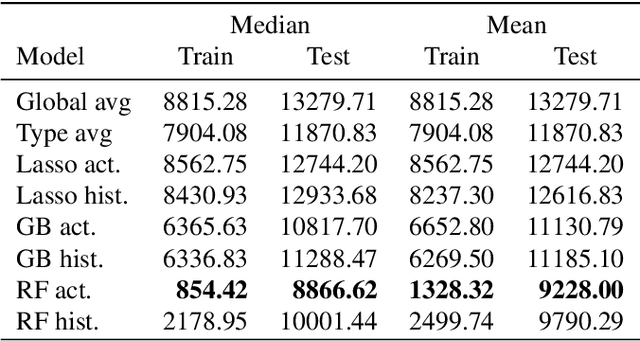
Maritime traffic emissions are a major concern to governments as they heavily impact the Air Quality in coastal cities. Ships use the Automatic Identification System (AIS) to continuously report position and speed among other features, and therefore this data is suitable to be used to estimate emissions, if it is combined with engine data. However, important ship features are often inaccurate or missing. State-of-the-art complex systems, like CALIOPE at the Barcelona Supercomputing Center, are used to model Air Quality. These systems can benefit from AIS based emission models as they are very precise in positioning the pollution. Unfortunately, these models are sensitive to missing or corrupted data, and therefore they need data curation techniques to significantly improve the estimation accuracy. In this work, we propose a methodology for treating ship data using Conditional Restricted Boltzmann Machines (CRBMs) plus machine learning methods to improve the quality of data passed to emission models. Results show that we can improve the default methods proposed to cover missing data. In our results, we observed that using our method the models boosted their accuracy to detect otherwise undetectable emissions. In particular, we used a real data-set of AIS data, provided by the Spanish Port Authority, to estimate that thanks to our method, the model was able to detect 45% of additional emissions, of additional emissions, representing 152 tonnes of pollutants per week in Barcelona and propose new features that may enhance emission modeling.
* 12 pages, 7 figures. Postprint accepted manuscript, find the full version at Engineering Applications of Artificial Intelligence (https://doi.org/10.1016/j.engappai.2020.103793)
ALOJA: A Framework for Benchmarking and Predictive Analytics in Big Data Deployments
Nov 06, 2015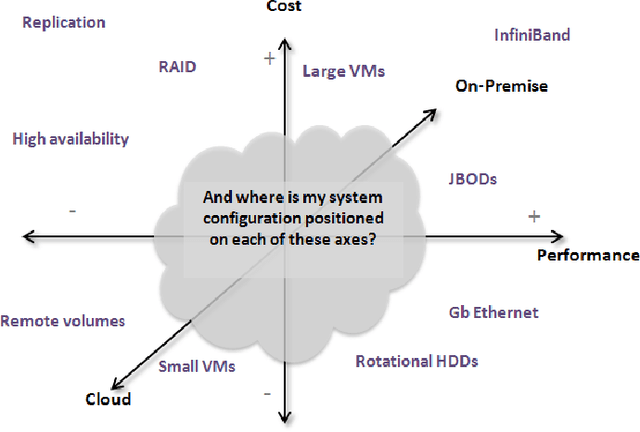
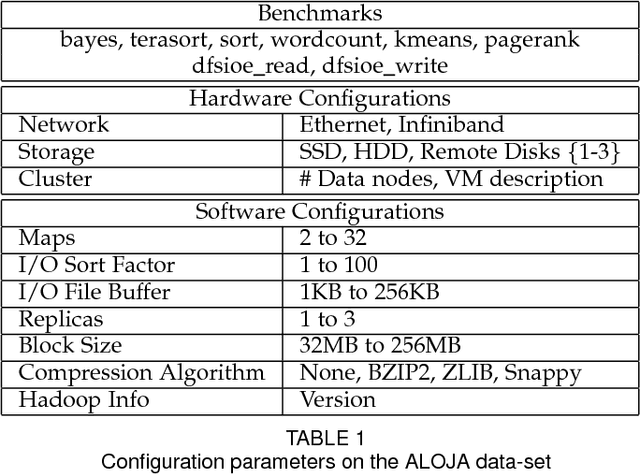

This article presents the ALOJA project and its analytics tools, which leverages machine learning to interpret Big Data benchmark performance data and tuning. ALOJA is part of a long-term collaboration between BSC and Microsoft to automate the characterization of cost-effectiveness on Big Data deployments, currently focusing on Hadoop. Hadoop presents a complex run-time environment, where costs and performance depend on a large number of configuration choices. The ALOJA project has created an open, vendor-neutral repository, featuring over 40,000 Hadoop job executions and their performance details. The repository is accompanied by a test-bed and tools to deploy and evaluate the cost-effectiveness of different hardware configurations, parameters and Cloud services. Despite early success within ALOJA, a comprehensive study requires automation of modeling procedures to allow an analysis of large and resource-constrained search spaces. The predictive analytics extension, ALOJA-ML, provides an automated system allowing knowledge discovery by modeling environments from observed executions. The resulting models can forecast execution behaviors, predicting execution times for new configurations and hardware choices. That also enables model-based anomaly detection or efficient benchmark guidance by prioritizing executions. In addition, the community can benefit from ALOJA data-sets and framework to improve the design and deployment of Big Data applications.
ALOJA-ML: A Framework for Automating Characterization and Knowledge Discovery in Hadoop Deployments
Nov 06, 2015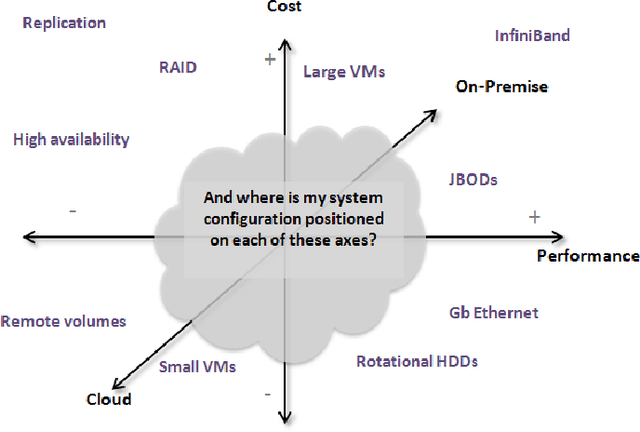
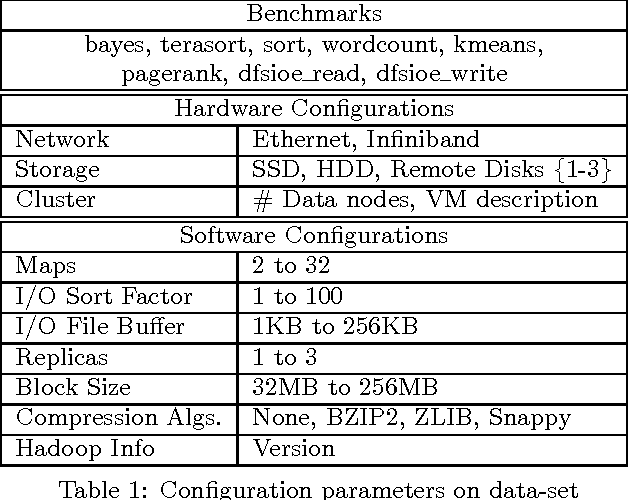

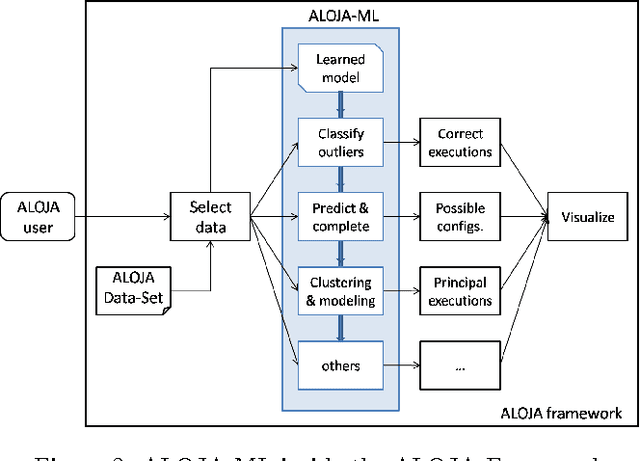
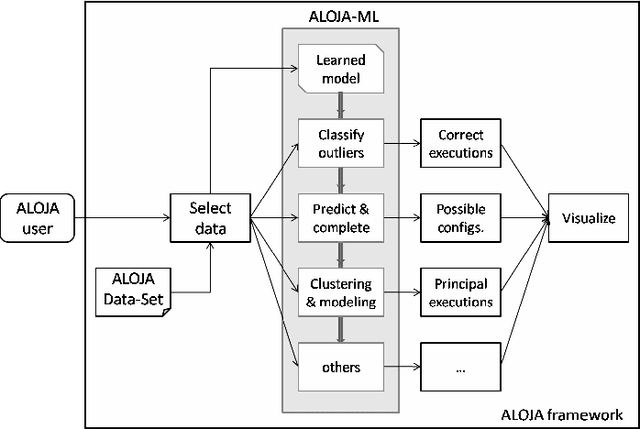
This article presents ALOJA-Machine Learning (ALOJA-ML) an extension to the ALOJA project that uses machine learning techniques to interpret Hadoop benchmark performance data and performance tuning; here we detail the approach, efficacy of the model and initial results. Hadoop presents a complex execution environment, where costs and performance depends on a large number of software (SW) configurations and on multiple hardware (HW) deployment choices. These results are accompanied by a test bed and tools to deploy and evaluate the cost-effectiveness of the different hardware configurations, parameter tunings, and Cloud services. Despite early success within ALOJA from expert-guided benchmarking, it became clear that a genuinely comprehensive study requires automation of modeling procedures to allow a systematic analysis of large and resource-constrained search spaces. ALOJA-ML provides such an automated system allowing knowledge discovery by modeling Hadoop executions from observed benchmarks across a broad set of configuration parameters. The resulting performance models can be used to forecast execution behavior of various workloads; they allow 'a-priori' prediction of the execution times for new configurations and HW choices and they offer a route to model-based anomaly detection. In addition, these models can guide the benchmarking exploration efficiently, by automatically prioritizing candidate future benchmark tests. Insights from ALOJA-ML's models can be used to reduce the operational time on clusters, speed-up the data acquisition and knowledge discovery process, and importantly, reduce running costs. In addition to learning from the methodology presented in this work, the community can benefit in general from ALOJA data-sets, framework, and derived insights to improve the design and deployment of Big Data applications.
* Submitted to KDD'2015. Part of the Aloja Project. Partially funded by European Research Council (ERC) under the European Union's Horizon 2020 research and innovation programme (grant agreement No 639595) - HiEST Project