 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Maritime Traffic Emission Estimations on Missing Data with CRBMs
Sep 10, 2020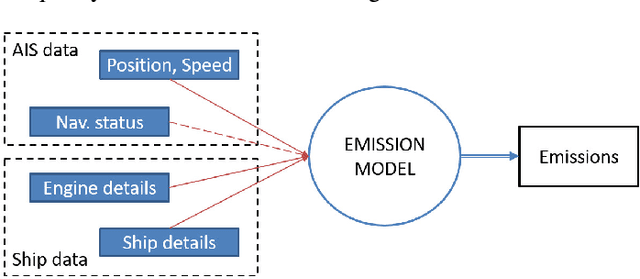
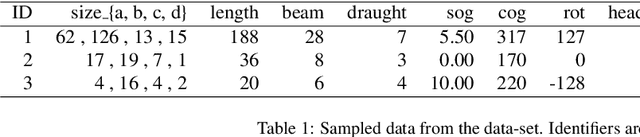
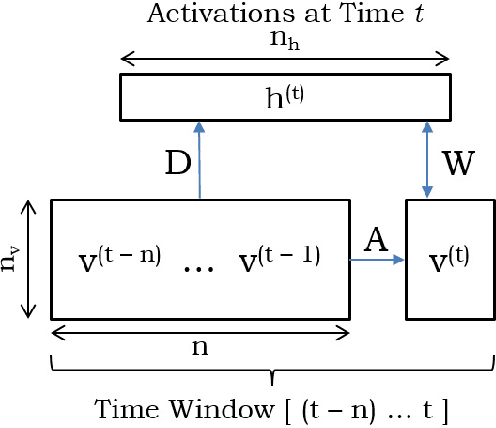
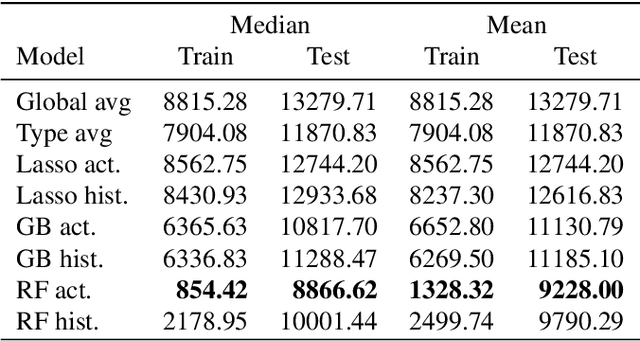
Maritime traffic emissions are a major concern to governments as they heavily impact the Air Quality in coastal cities. Ships use the Automatic Identification System (AIS) to continuously report position and speed among other features, and therefore this data is suitable to be used to estimate emissions, if it is combined with engine data. However, important ship features are often inaccurate or missing. State-of-the-art complex systems, like CALIOPE at the Barcelona Supercomputing Center, are used to model Air Quality. These systems can benefit from AIS based emission models as they are very precise in positioning the pollution. Unfortunately, these models are sensitive to missing or corrupted data, and therefore they need data curation techniques to significantly improve the estimation accuracy. In this work, we propose a methodology for treating ship data using Conditional Restricted Boltzmann Machines (CRBMs) plus machine learning methods to improve the quality of data passed to emission models. Results show that we can improve the default methods proposed to cover missing data. In our results, we observed that using our method the models boosted their accuracy to detect otherwise undetectable emissions. In particular, we used a real data-set of AIS data, provided by the Spanish Port Authority, to estimate that thanks to our method, the model was able to detect 45% of additional emissions, of additional emissions, representing 152 tonnes of pollutants per week in Barcelona and propose new features that may enhance emission modeling.
* 12 pages, 7 figures. Postprint accepted manuscript, find the full version at Engineering Applications of Artificial Intelligence (https://doi.org/10.1016/j.engappai.2020.103793)
Stopping Criteria in Contrastive Divergence: Alternatives to the Reconstruction Error
Apr 09, 2014


Restricted Boltzmann Machines (RBMs) are general unsupervised learning devices to ascertain generative models of data distributions. RBMs are often trained using the Contrastive Divergence learning algorithm (CD), an approximation to the gradient of the data log-likelihood. A simple reconstruction error is often used to decide whether the approximation provided by the CD algorithm is good enough, though several authors (Schulz et al., 2010; Fischer & Igel, 2010) have raised doubts concerning the feasibility of this procedure. However, not many alternatives to the reconstruction error have been used in the literature. In this manuscript we investigate simple alternatives to the reconstruction error in order to detect as soon as possible the decrease in the log-likelihood during learning.