 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Driven Optimization of GPU efficiency for Distributed LLM Adapter Serving
Feb 27, 2026Large Language Model (LLM) adapters enable low-cost model specialization, but introduce complex caching and scheduling challenges in distributed serving systems where hundreds of adapters must be hosted concurrently. While prior work has largely focused on latency minimization, resource efficiency through throughput maximization remains underexplored. This paper presents a data-driven pipeline that, for a given workload, computes an adapter placement that serves the workload with the minimum number of GPUs while avoiding request starvation and GPU memory errors. To that end, the approach identifies the maximum feasible throughput attainable on each GPU by leveraging accurate performance predictions learned from real serving behavior. The proposed pipeline integrates three components: (i) a Digital Twin (DT) tailored to LLM-adapter serving, (ii) a distilled machine learning (ML) model trained on DT-generated data, and (iii) a greedy placement algorithm that exploits ML-based performance estimates to maximize GPU efficiency. The DT emulates real system dynamics with high fidelity, achieving below 5% throughput estimation error while executing up to 90 times faster than full LLM benchmarking across both predictable and unpredictable workloads. The learned ML models further accelerate performance estimation with marginal accuracy degradation, enabling scalable optimization. Experimental results demonstrate that the pipeline substantially improves GPU efficiency by reducing the number of GPUs required to sustain target workloads. Beyond GPU efficiency, the pipeline can be adapted to alternative objectives, such as latency minimization, highlighting its versatility for future large-scale LLM serving infrastructures.
Maximizing GPU Efficiency via Optimal Adapter Caching: An Analytical Approach for Multi-Tenant LLM Serving
Aug 11, 2025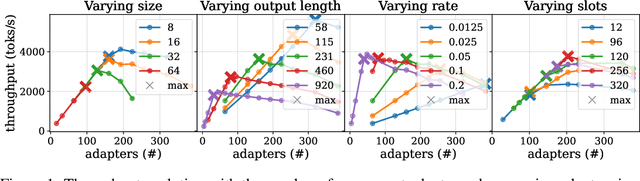
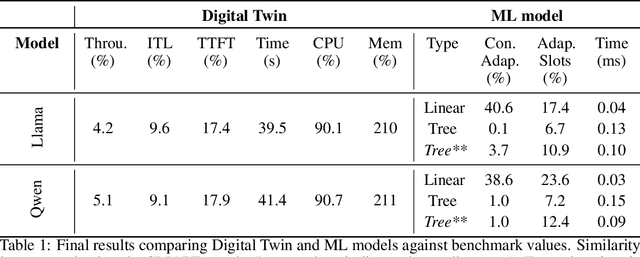
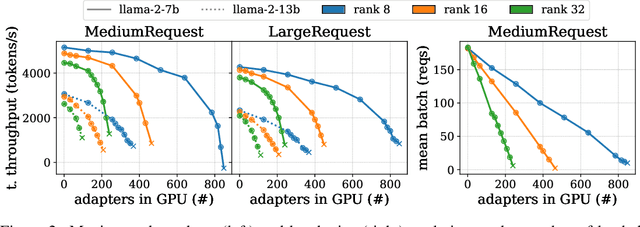
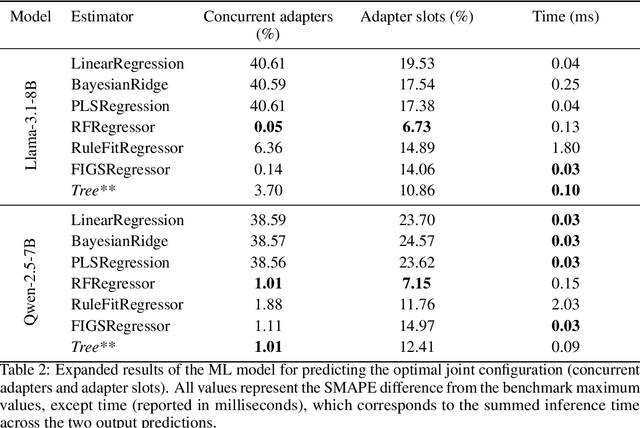
Serving LLM adapters has gained significant attention as an effective approach to adapt general-purpose language models to diverse, task-specific use cases. However, serving a wide range of adapters introduces several and substantial overheads, leading to performance degradation and challenges in optimal placement. To address these challenges, we present an analytical, AI-driven pipeline that accurately determines the optimal allocation of adapters in single-node setups. This allocation maximizes performance, effectively using GPU resources, while preventing request starvation. Crucially, the proposed allocation is given based on current workload patterns. These insights in single-node setups can be leveraged in multi-replica deployments for overall placement, load balancing and server configuration, ultimately enhancing overall performance and improving resource efficiency. Our approach builds on an in-depth analysis of LLM adapter serving, accounting for overheads and performance variability, and includes the development of the first Digital Twin capable of replicating online LLM-adapter serving systems with matching key performance metrics. The experimental results demonstrate that the Digital Twin achieves a SMAPE difference of no more than 5.5% in throughput compared to real results, and the proposed pipeline accurately predicts the optimal placement with minimal latency.
FRIDA: Free-Rider Detection using Privacy Attacks
Oct 07, 2024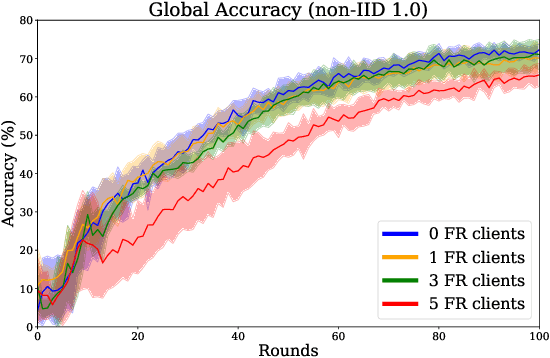
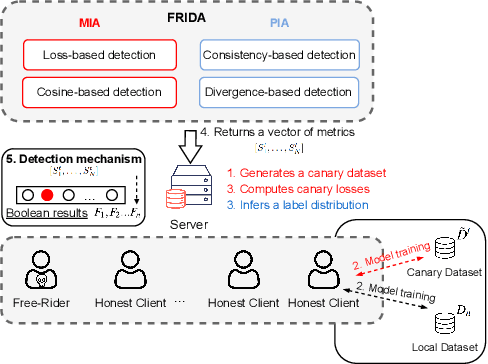
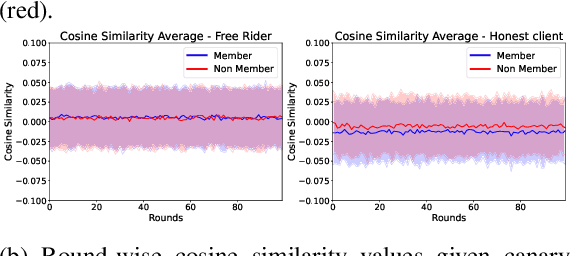
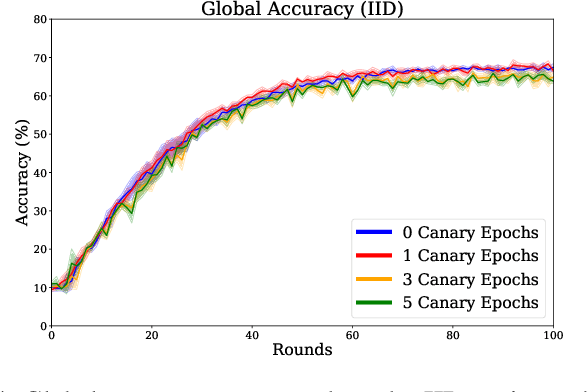
Federated learning is increasingly popular as it enables multiple parties with limited datasets and resources to train a high-performing machine learning model collaboratively. However, similarly to other collaborative systems, federated learning is vulnerable to free-riders -- participants who do not contribute to the training but still benefit from the shared model. Free-riders not only compromise the integrity of the learning process but also slow down the convergence of the global model, resulting in increased costs for the honest participants. To address this challenge, we propose FRIDA: free-rider detection using privacy attacks, a framework that leverages inference attacks to detect free-riders. Unlike traditional methods that only capture the implicit effects of free-riding, FRIDA directly infers details of the underlying training datasets, revealing characteristics that indicate free-rider behaviour. Through extensive experiments, we demonstrate that membership and property inference attacks are effective for this purpose. Our evaluation shows that FRIDA outperforms state-of-the-art methods, especially in non-IID settings.
Improving Maritime Traffic Emission Estimations on Missing Data with CRBMs
Sep 10, 2020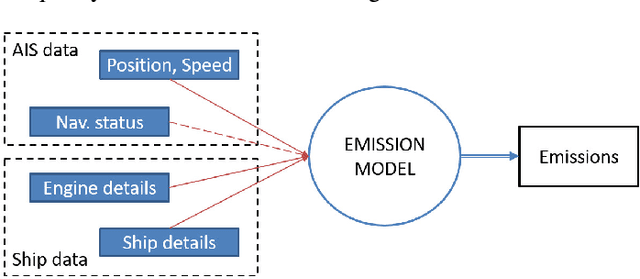
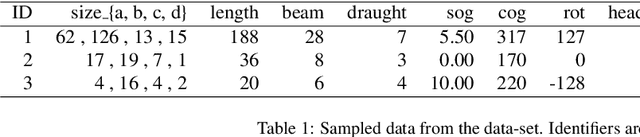
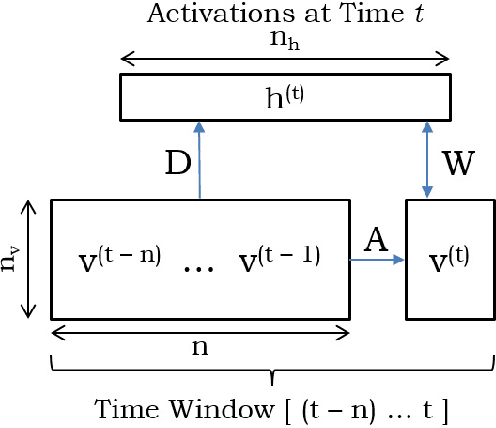
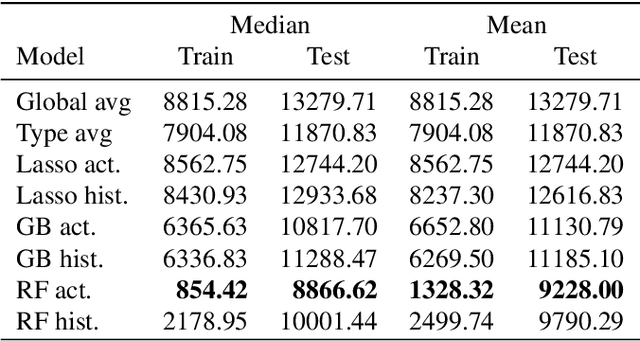
Maritime traffic emissions are a major concern to governments as they heavily impact the Air Quality in coastal cities. Ships use the Automatic Identification System (AIS) to continuously report position and speed among other features, and therefore this data is suitable to be used to estimate emissions, if it is combined with engine data. However, important ship features are often inaccurate or missing. State-of-the-art complex systems, like CALIOPE at the Barcelona Supercomputing Center, are used to model Air Quality. These systems can benefit from AIS based emission models as they are very precise in positioning the pollution. Unfortunately, these models are sensitive to missing or corrupted data, and therefore they need data curation techniques to significantly improve the estimation accuracy. In this work, we propose a methodology for treating ship data using Conditional Restricted Boltzmann Machines (CRBMs) plus machine learning methods to improve the quality of data passed to emission models. Results show that we can improve the default methods proposed to cover missing data. In our results, we observed that using our method the models boosted their accuracy to detect otherwise undetectable emissions. In particular, we used a real data-set of AIS data, provided by the Spanish Port Authority, to estimate that thanks to our method, the model was able to detect 45% of additional emissions, of additional emissions, representing 152 tonnes of pollutants per week in Barcelona and propose new features that may enhance emission modeling.
* 12 pages, 7 figures. Postprint accepted manuscript, find the full version at Engineering Applications of Artificial Intelligence (https://doi.org/10.1016/j.engappai.2020.103793)