 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Video Analytics through Object-Level Consolidation
Nov 30, 2021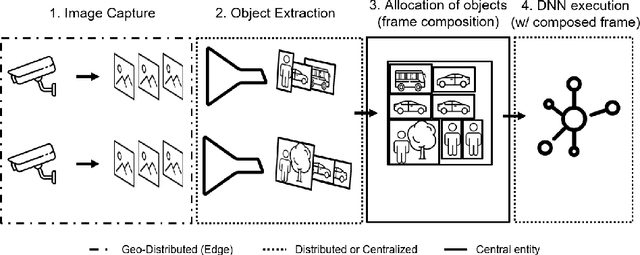

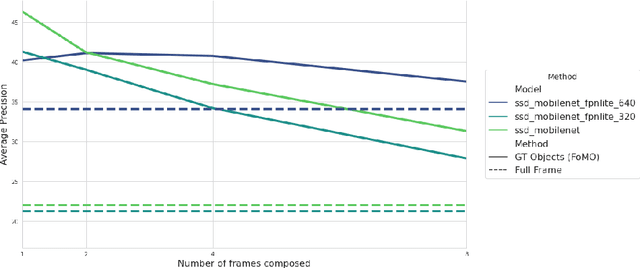

As the number of installed cameras grows, so do the compute resources required to process and analyze all the images captured by these cameras. Video analytics enables new use cases, such as smart cities or autonomous driving. At the same time, it urges service providers to install additional compute resources to cope with the demand while the strict latency requirements push compute towards the end of the network, forming a geographically distributed and heterogeneous set of compute locations, shared and resource-constrained. Such landscape (shared and distributed locations) forces us to design new techniques that can optimize and distribute work among all available locations and, ideally, make compute requirements grow sublinearly with respect to the number of cameras installed. In this paper, we present FoMO (Focus on Moving Objects). This method effectively optimizes multi-camera deployments by preprocessing images for scenes, filtering the empty regions out, and composing regions of interest from multiple cameras into a single image that serves as input for a pre-trained object detection model. Results show that overall system performance can be increased by 8x while accuracy improves 40% as a by-product of the methodology, all using an off-the-shelf pre-trained model with no additional training or fine-tuning.
Towards Unsupervised Fine-Tuning for Edge Video Analytics
Apr 14, 2021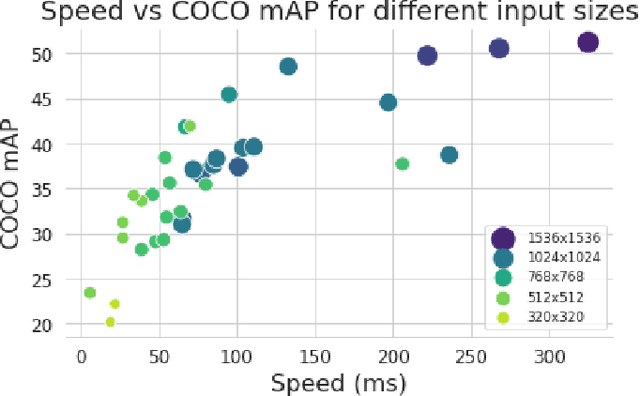
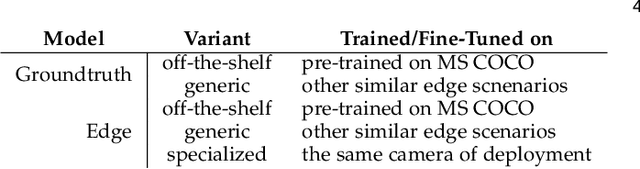
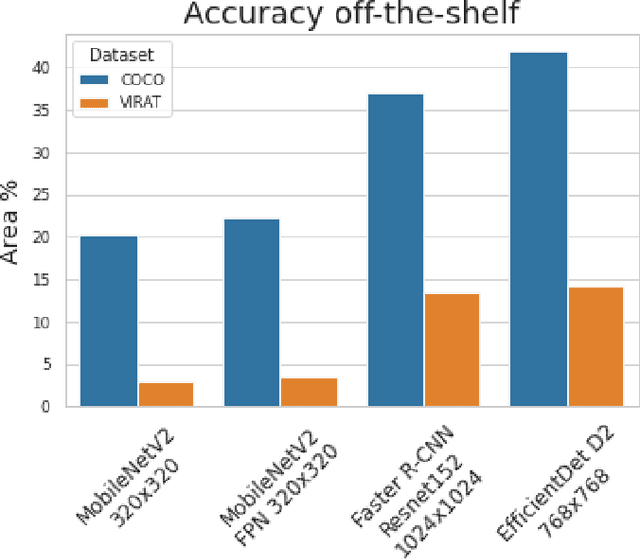
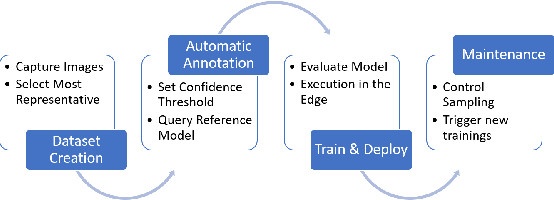
Judging by popular and generic computer vision challenges, such as the ImageNet or PASCAL VOC, neural networks have proven to be exceptionally accurate in recognition tasks. However, state-of-the-art accuracy often comes at a high computational price, requiring equally state-of-the-art and high-end hardware acceleration to achieve anything near real-time performance. At the same time, use cases such as smart cities or autonomous vehicles require an automated analysis of images from fixed cameras in real-time. Due to the huge and constant amount of network bandwidth these streams would generate, we cannot rely on offloading compute to the omnipresent and omnipotent cloud. Therefore, a distributed Edge Cloud must be in charge to process images locally. However, the Edge Cloud is, by nature, resource-constrained, which puts a limit on the computational complexity of the models executed in the edge. Nonetheless, there is a need for a meeting point between the Edge Cloud and accurate real-time video analytics. In this paper, we propose a method for improving accuracy of edge models without any extra compute cost by means of automatic model specialization. First, we show how the sole assumption of static cameras allows us to make a series of considerations that greatly simplify the scope of the problem. Then, we present Edge AutoTuner, a framework that implements and brings these considerations together to automate the end-to-end fine-tuning of models. Finally, we show that complex neural networks - able to generalize better - can be effectively used as teachers to annotate datasets for the fine-tuning of lightweight neural networks and tailor them to the specific edge context, which boosts accuracy at constant computational cost, and do so without any human interaction. Results show that our method can automatically improve accuracy of pre-trained models by an average of 21%.
Improving Maritime Traffic Emission Estimations on Missing Data with CRBMs
Sep 10, 2020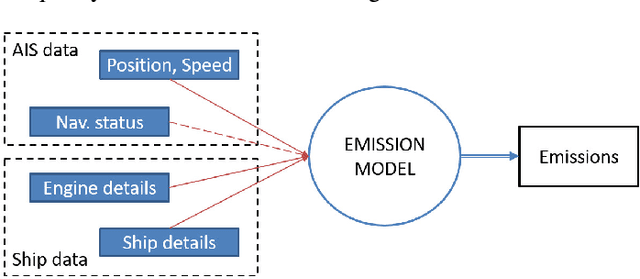
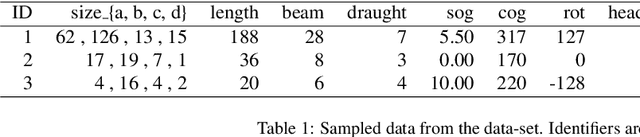
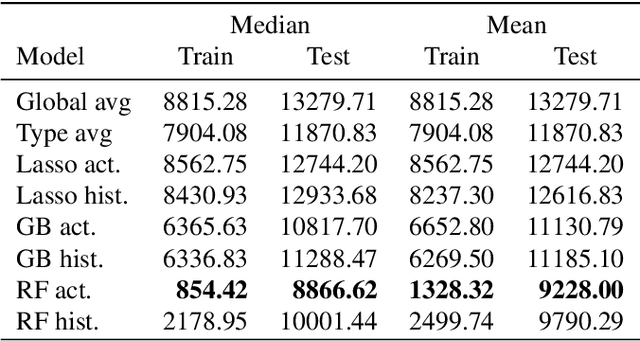
Maritime traffic emissions are a major concern to governments as they heavily impact the Air Quality in coastal cities. Ships use the Automatic Identification System (AIS) to continuously report position and speed among other features, and therefore this data is suitable to be used to estimate emissions, if it is combined with engine data. However, important ship features are often inaccurate or missing. State-of-the-art complex systems, like CALIOPE at the Barcelona Supercomputing Center, are used to model Air Quality. These systems can benefit from AIS based emission models as they are very precise in positioning the pollution. Unfortunately, these models are sensitive to missing or corrupted data, and therefore they need data curation techniques to significantly improve the estimation accuracy. In this work, we propose a methodology for treating ship data using Conditional Restricted Boltzmann Machines (CRBMs) plus machine learning methods to improve the quality of data passed to emission models. Results show that we can improve the default methods proposed to cover missing data. In our results, we observed that using our method the models boosted their accuracy to detect otherwise undetectable emissions. In particular, we used a real data-set of AIS data, provided by the Spanish Port Authority, to estimate that thanks to our method, the model was able to detect 45% of additional emissions, of additional emissions, representing 152 tonnes of pollutants per week in Barcelona and propose new features that may enhance emission modeling.
* 12 pages, 7 figures. Postprint accepted manuscript, find the full version at Engineering Applications of Artificial Intelligence (https://doi.org/10.1016/j.engappai.2020.103793)
Sequence-to-sequence models for workload interference
Jul 06, 2020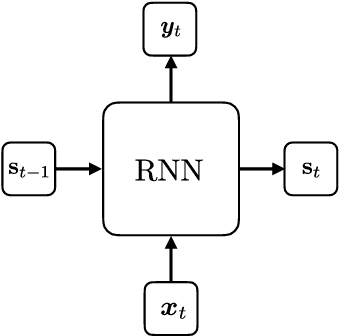

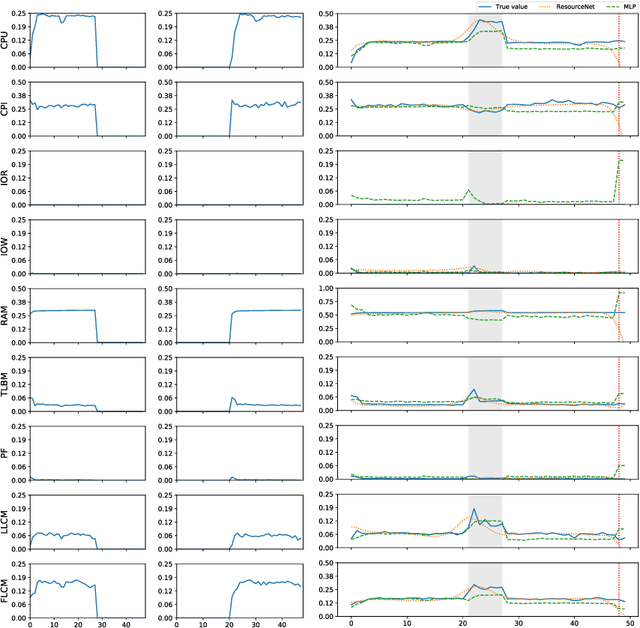
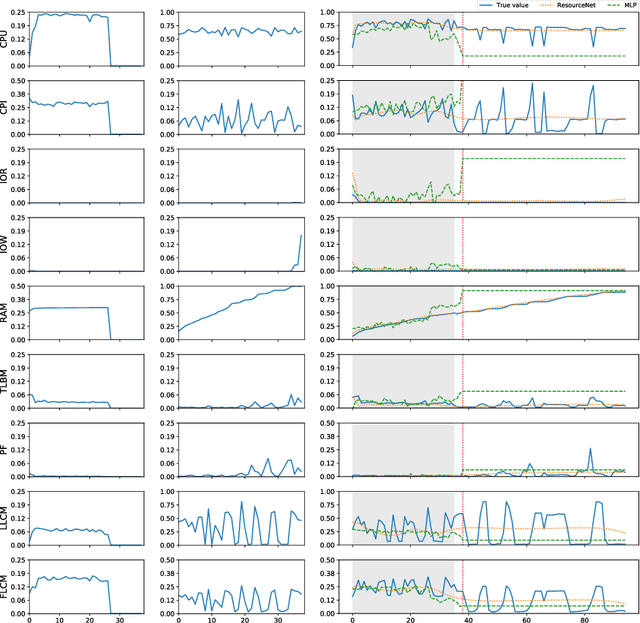
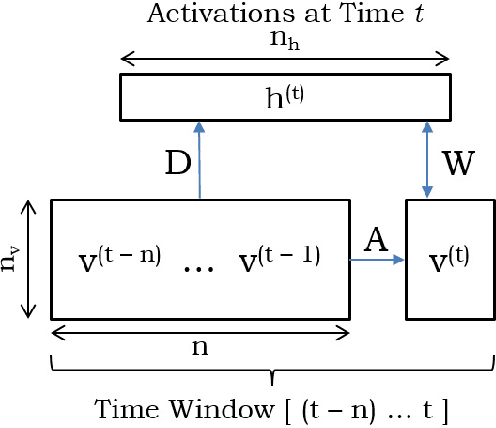
Co-scheduling of jobs in data-centers is a challenging scenario, where jobs can compete for resources yielding to severe slowdowns or failed executions. Efficient job placement on environments where resources are shared requires awareness on how jobs interfere during execution, to go far beyond ineffective resource overbooking techniques. Current techniques, most of them already involving machine learning and job modeling, are based on workload behavior summarization across time, instead of focusing on effective job requirements at each instant of the execution. In this work we propose a methodology for modeling co-scheduling of jobs on data-centers, based on their behavior towards resources and execution time, using sequence-to-sequence models based on recurrent neural networks. The goal is to forecast co-executed jobs footprint on resources along their execution time, from the profile shown by the individual jobs, to enhance resource managers and schedulers placement decisions. The methods here presented are validated using High Performance Computing benchmarks based on different frameworks (like Hadoop and Spark) and applications (CPU bound, IO bound, machine learning, SQL queries...). Experiments show that the model can correctly identify the resource usage trends from previously seen and even unseen co-scheduled jobs.
* artially funded by European Research Council (ERC) under the European Union's Horizon 2020 research and innovation programme (grant agreement No 639595) - HiEST Project
ALOJA: A Framework for Benchmarking and Predictive Analytics in Big Data Deployments
Nov 06, 2015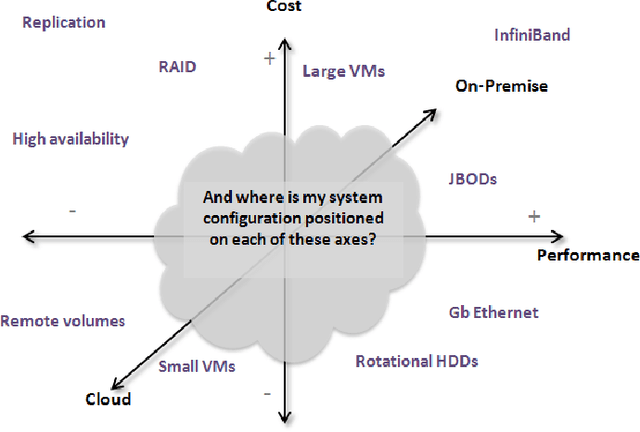
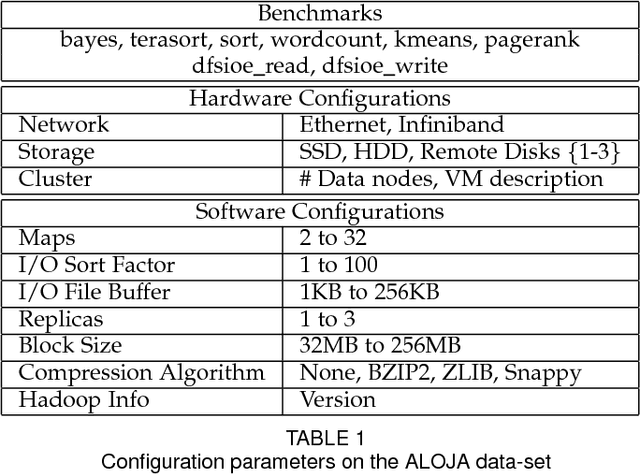

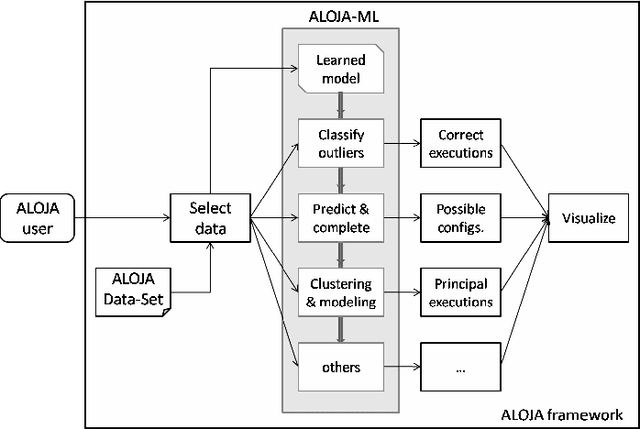
This article presents the ALOJA project and its analytics tools, which leverages machine learning to interpret Big Data benchmark performance data and tuning. ALOJA is part of a long-term collaboration between BSC and Microsoft to automate the characterization of cost-effectiveness on Big Data deployments, currently focusing on Hadoop. Hadoop presents a complex run-time environment, where costs and performance depend on a large number of configuration choices. The ALOJA project has created an open, vendor-neutral repository, featuring over 40,000 Hadoop job executions and their performance details. The repository is accompanied by a test-bed and tools to deploy and evaluate the cost-effectiveness of different hardware configurations, parameters and Cloud services. Despite early success within ALOJA, a comprehensive study requires automation of modeling procedures to allow an analysis of large and resource-constrained search spaces. The predictive analytics extension, ALOJA-ML, provides an automated system allowing knowledge discovery by modeling environments from observed executions. The resulting models can forecast execution behaviors, predicting execution times for new configurations and hardware choices. That also enables model-based anomaly detection or efficient benchmark guidance by prioritizing executions. In addition, the community can benefit from ALOJA data-sets and framework to improve the design and deployment of Big Data applications.
ALOJA-ML: A Framework for Automating Characterization and Knowledge Discovery in Hadoop Deployments
Nov 06, 2015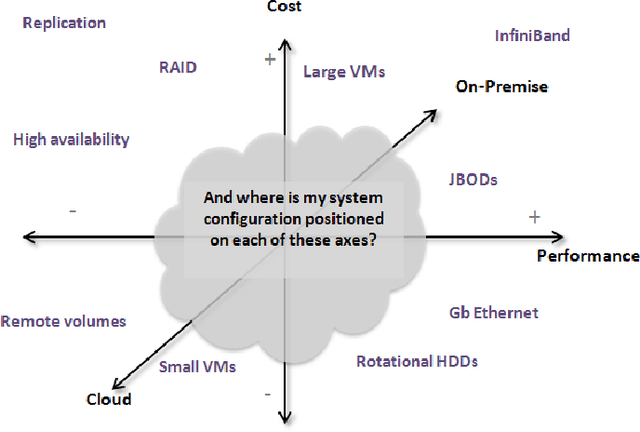
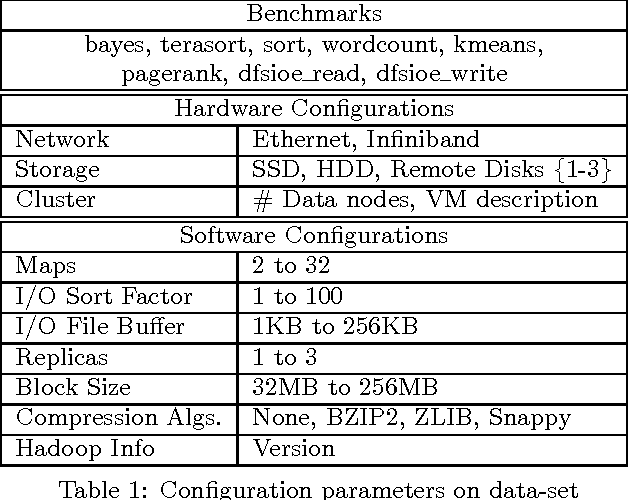

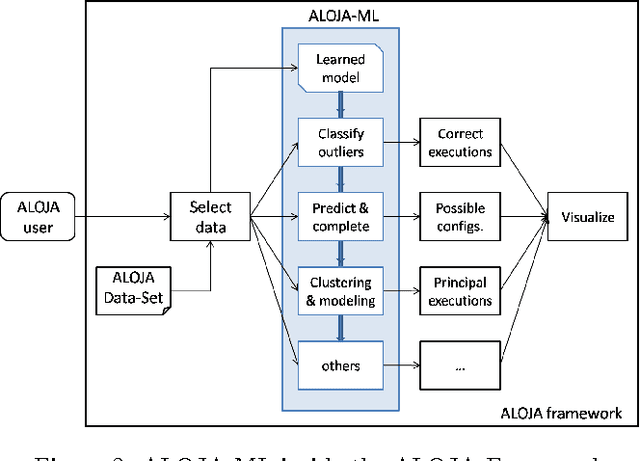
This article presents ALOJA-Machine Learning (ALOJA-ML) an extension to the ALOJA project that uses machine learning techniques to interpret Hadoop benchmark performance data and performance tuning; here we detail the approach, efficacy of the model and initial results. Hadoop presents a complex execution environment, where costs and performance depends on a large number of software (SW) configurations and on multiple hardware (HW) deployment choices. These results are accompanied by a test bed and tools to deploy and evaluate the cost-effectiveness of the different hardware configurations, parameter tunings, and Cloud services. Despite early success within ALOJA from expert-guided benchmarking, it became clear that a genuinely comprehensive study requires automation of modeling procedures to allow a systematic analysis of large and resource-constrained search spaces. ALOJA-ML provides such an automated system allowing knowledge discovery by modeling Hadoop executions from observed benchmarks across a broad set of configuration parameters. The resulting performance models can be used to forecast execution behavior of various workloads; they allow 'a-priori' prediction of the execution times for new configurations and HW choices and they offer a route to model-based anomaly detection. In addition, these models can guide the benchmarking exploration efficiently, by automatically prioritizing candidate future benchmark tests. Insights from ALOJA-ML's models can be used to reduce the operational time on clusters, speed-up the data acquisition and knowledge discovery process, and importantly, reduce running costs. In addition to learning from the methodology presented in this work, the community can benefit in general from ALOJA data-sets, framework, and derived insights to improve the design and deployment of Big Data applications.
* Submitted to KDD'2015. Part of the Aloja Project. Partially funded by European Research Council (ERC) under the European Union's Horizon 2020 research and innovation programme (grant agreement No 639595) - HiEST Project