 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Video Analytics through Object-Level Consolidation
Nov 30, 2021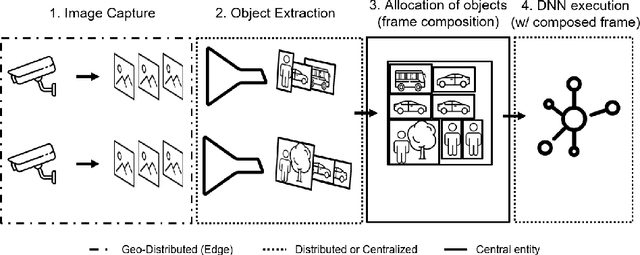

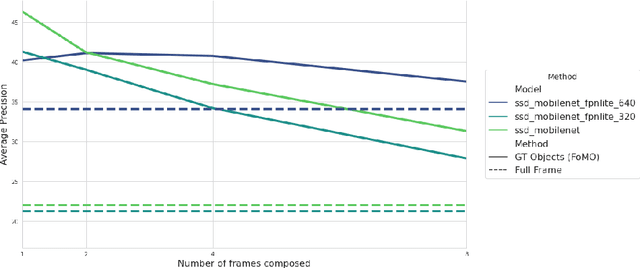

As the number of installed cameras grows, so do the compute resources required to process and analyze all the images captured by these cameras. Video analytics enables new use cases, such as smart cities or autonomous driving. At the same time, it urges service providers to install additional compute resources to cope with the demand while the strict latency requirements push compute towards the end of the network, forming a geographically distributed and heterogeneous set of compute locations, shared and resource-constrained. Such landscape (shared and distributed locations) forces us to design new techniques that can optimize and distribute work among all available locations and, ideally, make compute requirements grow sublinearly with respect to the number of cameras installed. In this paper, we present FoMO (Focus on Moving Objects). This method effectively optimizes multi-camera deployments by preprocessing images for scenes, filtering the empty regions out, and composing regions of interest from multiple cameras into a single image that serves as input for a pre-trained object detection model. Results show that overall system performance can be increased by 8x while accuracy improves 40% as a by-product of the methodology, all using an off-the-shelf pre-trained model with no additional training or fine-tuning.
Towards Unsupervised Fine-Tuning for Edge Video Analytics
Apr 14, 2021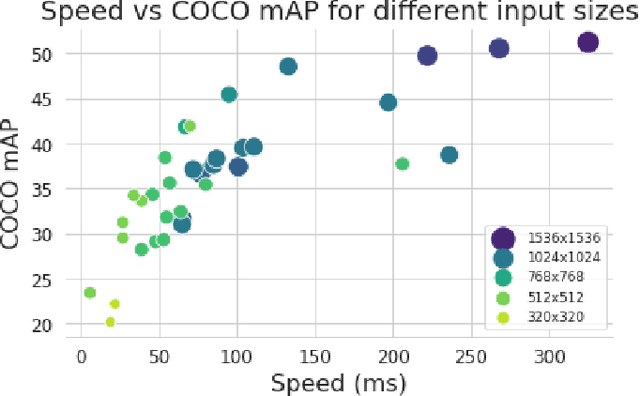
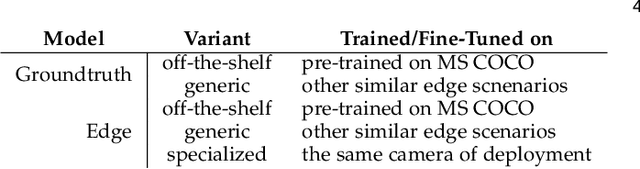
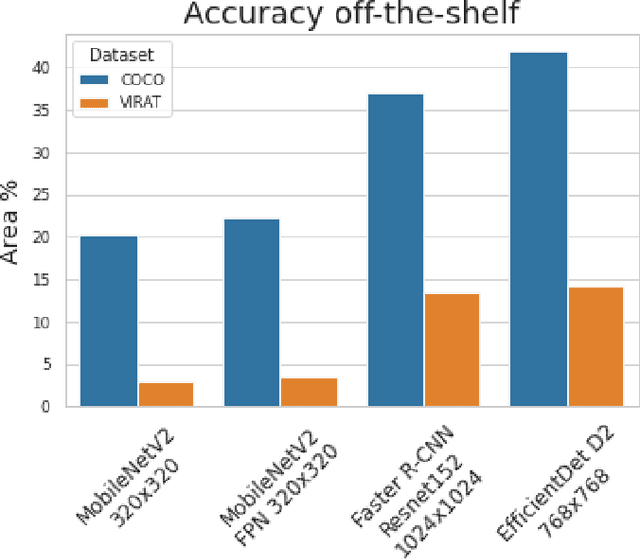
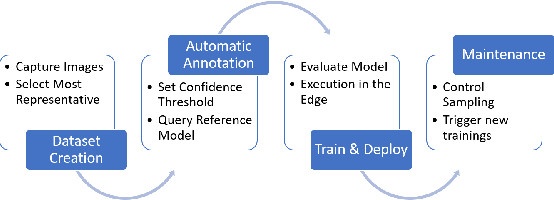
Judging by popular and generic computer vision challenges, such as the ImageNet or PASCAL VOC, neural networks have proven to be exceptionally accurate in recognition tasks. However, state-of-the-art accuracy often comes at a high computational price, requiring equally state-of-the-art and high-end hardware acceleration to achieve anything near real-time performance. At the same time, use cases such as smart cities or autonomous vehicles require an automated analysis of images from fixed cameras in real-time. Due to the huge and constant amount of network bandwidth these streams would generate, we cannot rely on offloading compute to the omnipresent and omnipotent cloud. Therefore, a distributed Edge Cloud must be in charge to process images locally. However, the Edge Cloud is, by nature, resource-constrained, which puts a limit on the computational complexity of the models executed in the edge. Nonetheless, there is a need for a meeting point between the Edge Cloud and accurate real-time video analytics. In this paper, we propose a method for improving accuracy of edge models without any extra compute cost by means of automatic model specialization. First, we show how the sole assumption of static cameras allows us to make a series of considerations that greatly simplify the scope of the problem. Then, we present Edge AutoTuner, a framework that implements and brings these considerations together to automate the end-to-end fine-tuning of models. Finally, we show that complex neural networks - able to generalize better - can be effectively used as teachers to annotate datasets for the fine-tuning of lightweight neural networks and tailor them to the specific edge context, which boosts accuracy at constant computational cost, and do so without any human interaction. Results show that our method can automatically improve accuracy of pre-trained models by an average of 21%.