 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALOJA-ML: A Framework for Automating Characterization and Knowledge Discovery in Hadoop Deployments
Paper and Code
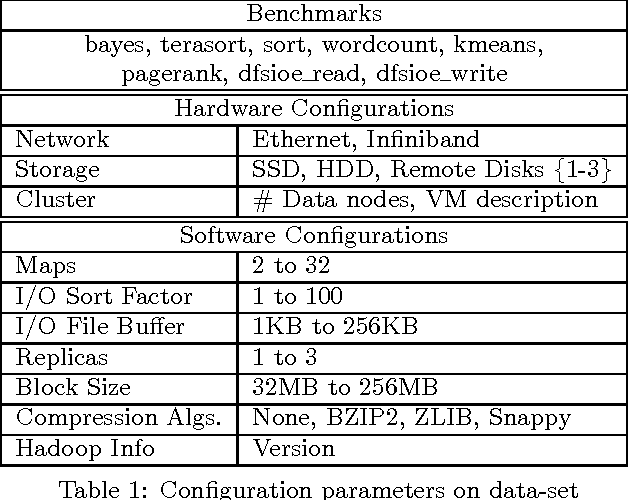

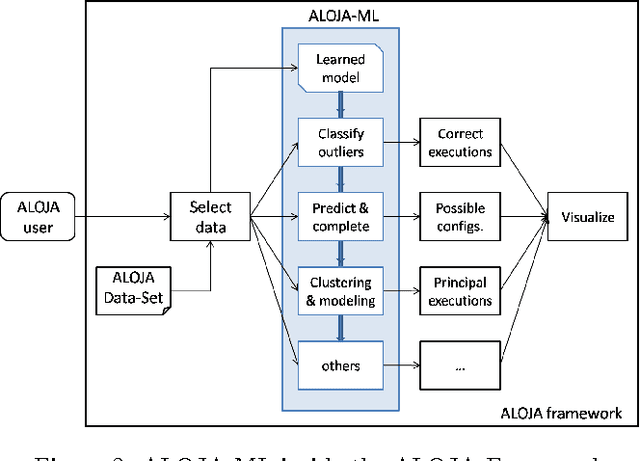
This article presents ALOJA-Machine Learning (ALOJA-ML) an extension to the ALOJA project that uses machine learning techniques to interpret Hadoop benchmark performance data and performance tuning; here we detail the approach, efficacy of the model and initial results. Hadoop presents a complex execution environment, where costs and performance depends on a large number of software (SW) configurations and on multiple hardware (HW) deployment choices. These results are accompanied by a test bed and tools to deploy and evaluate the cost-effectiveness of the different hardware configurations, parameter tunings, and Cloud services. Despite early success within ALOJA from expert-guided benchmarking, it became clear that a genuinely comprehensive study requires automation of modeling procedures to allow a systematic analysis of large and resource-constrained search spaces. ALOJA-ML provides such an automated system allowing knowledge discovery by modeling Hadoop executions from observed benchmarks across a broad set of configuration parameters. The resulting performance models can be used to forecast execution behavior of various workloads; they allow 'a-priori' prediction of the execution times for new configurations and HW choices and they offer a route to model-based anomaly detection. In addition, these models can guide the benchmarking exploration efficiently, by automatically prioritizing candidate future benchmark tests. Insights from ALOJA-ML's models can be used to reduce the operational time on clusters, speed-up the data acquisition and knowledge discovery process, and importantly, reduce running costs. In addition to learning from the methodology presented in this work, the community can benefit in general from ALOJA data-sets, framework, and derived insights to improve the design and deployment of Big Data applications.