 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTunaOil: A Tuning Algorithm Strategy for Reservoir Simulation Workloads
Aug 04, 2022



Reservoir simulations for petroleum fields and seismic imaging are known as the most demanding workloads for high-performance computing (HPC) in the oil and gas (O&G) industry. The optimization of the simulator numerical parameters plays a vital role as it could save considerable computational efforts. State-of-the-art optimization techniques are based on running numerous simulations, specific for that purpose, to find good parameter candidates. However, using such an approach is highly costly in terms of time and computing resources. This work presents TunaOil, a new methodology to enhance the search for optimal numerical parameters of reservoir flow simulations using a performance model. In the O&G industry, it is common to use ensembles of models in different workflows to reduce the uncertainty associated with forecasting O&G production. We leverage the runs of those ensembles in such workflows to extract information from each simulation and optimize the numerical parameters in their subsequent runs. To validate the methodology, we implemented it in a history matching (HM) process that uses a Kalman filter algorithm to adjust an ensemble of reservoir models to match the observed data from the real field. We mine past execution logs from many simulations with different numerical configurations and build a machine learning model based on extracted features from the data. These features include properties of the reservoir models themselves, such as the number of active cells, to statistics of the simulation's behavior, such as the number of iterations of the linear solver. A sampling technique is used to query the oracle to find the numerical parameters that can reduce the elapsed time without significantly impacting the quality of the results. Our experiments show that the predictions can improve the overall HM workflow runtime on average by 31%.
Sequence-to-sequence models for workload interference
Jul 06, 2020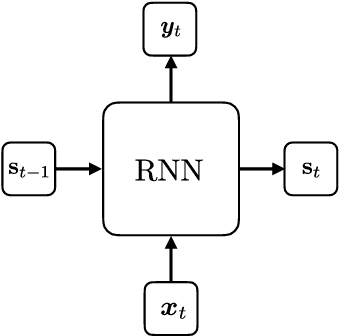

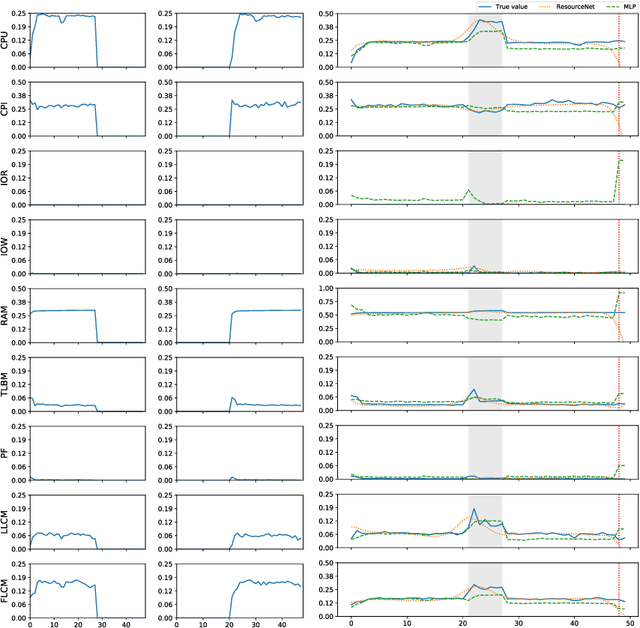
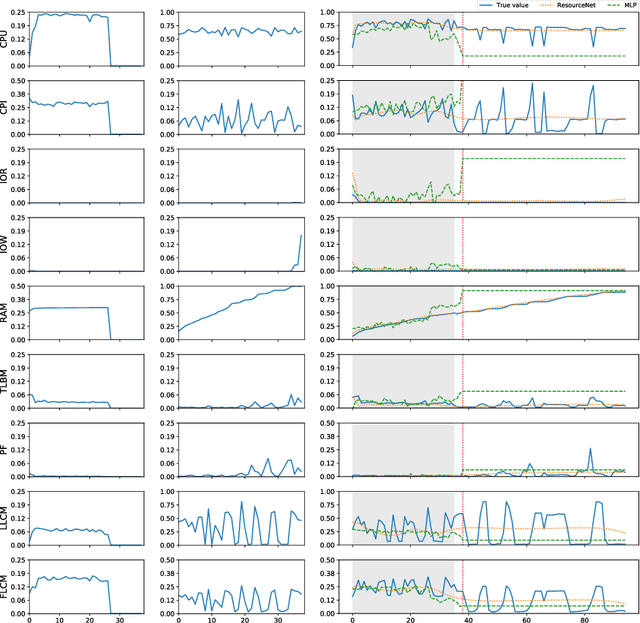
Co-scheduling of jobs in data-centers is a challenging scenario, where jobs can compete for resources yielding to severe slowdowns or failed executions. Efficient job placement on environments where resources are shared requires awareness on how jobs interfere during execution, to go far beyond ineffective resource overbooking techniques. Current techniques, most of them already involving machine learning and job modeling, are based on workload behavior summarization across time, instead of focusing on effective job requirements at each instant of the execution. In this work we propose a methodology for modeling co-scheduling of jobs on data-centers, based on their behavior towards resources and execution time, using sequence-to-sequence models based on recurrent neural networks. The goal is to forecast co-executed jobs footprint on resources along their execution time, from the profile shown by the individual jobs, to enhance resource managers and schedulers placement decisions. The methods here presented are validated using High Performance Computing benchmarks based on different frameworks (like Hadoop and Spark) and applications (CPU bound, IO bound, machine learning, SQL queries...). Experiments show that the model can correctly identify the resource usage trends from previously seen and even unseen co-scheduled jobs.
* artially funded by European Research Council (ERC) under the European Union's Horizon 2020 research and innovation programme (grant agreement No 639595) - HiEST Project