 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKARST: Multi-Kernel Kronecker Adaptation with Re-Scaling Transmission for Visual Classification
Paper and Code
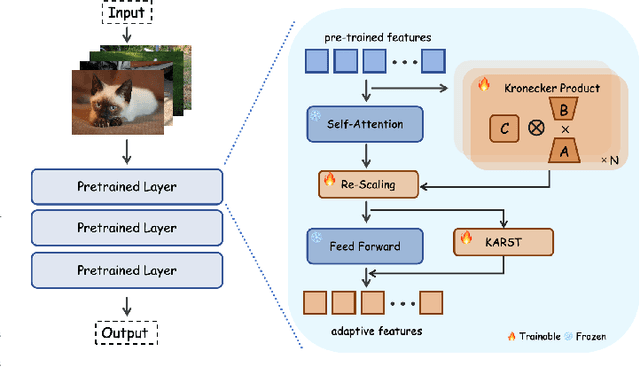
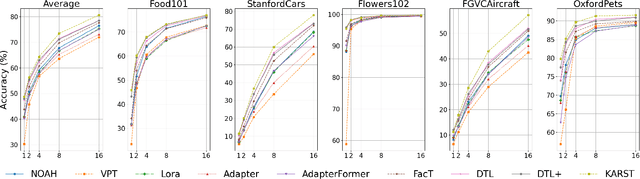
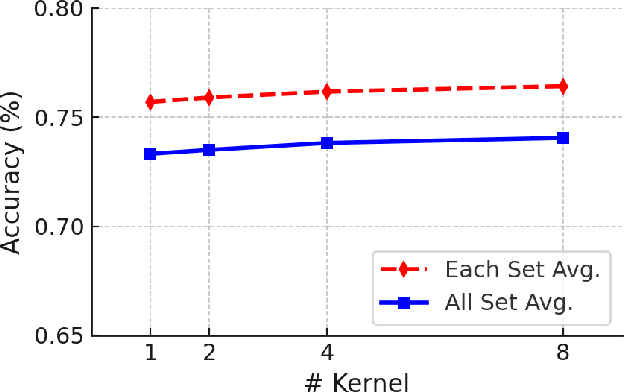
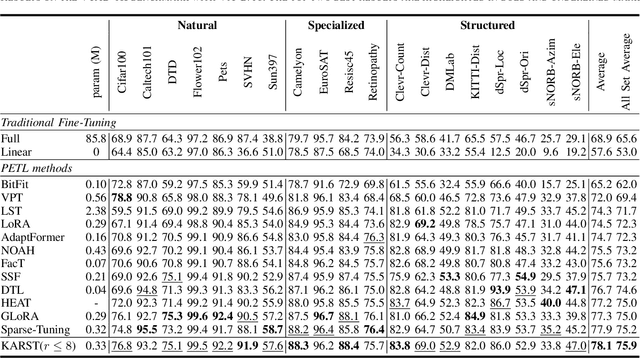
Fine-tuning pre-trained vision models for specific tasks is a common practice in computer vision. However, this process becomes more expensive as models grow larger. Recently, parameter-efficient fine-tuning (PEFT) methods have emerged as a popular solution to improve training efficiency and reduce storage needs by tuning additional low-rank modules within pre-trained backbones. Despite their advantages, they struggle with limited representation capabilities and misalignment with pre-trained intermediate features. To address these issues, we introduce an innovative Multi-Kernel Kronecker Adaptation with Re-Scaling Transmission (KARST) for various recognition tasks. Specifically, its multi-kernel design extends Kronecker projections horizontally and separates adaptation matrices into multiple complementary spaces, reducing parameter dependency and creating more compact subspaces. Besides, it incorporates extra learnable re-scaling factors to better align with pre-trained feature distributions, allowing for more flexible and balanced feature aggregation. Extensive experiments validate that our KARST outperforms other PEFT counterparts with a negligible inference cost due to its re-parameterization characteristics. Code is publicly available at: https://github.com/Lucenova/KARST.