 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does Personalized Memory Shape LLM Behavior? Benchmarking Rational Preference Utilization in Personalized Assistants
Jan 23, 2026Large language model (LLM)-powered assistants have recently integrated memory mechanisms that record user preferences, leading to more personalized and user-aligned responses. However, irrelevant personalized memories are often introduced into the context, interfering with the LLM's intent understanding. To comprehensively investigate the dual effects of personalization, we develop RPEval, a benchmark comprising a personalized intent reasoning dataset and a multi-granularity evaluation protocol. RPEval reveals the widespread phenomenon of irrational personalization in existing LLMs and, through error pattern analysis, illustrates its negative impact on user experience. Finally, we introduce RP-Reasoner, which treats memory utilization as a pragmatic reasoning process, enabling the selective integration of personalized information. Experimental results demonstrate that our method significantly outperforms carefully designed baselines on RPEval, and resolves 80% of the bad cases observed in a large-scale commercial personalized assistant, highlighting the potential of pragmatic reasoning to mitigate irrational personalization. Our benchmark is publicly available at https://github.com/XueyangFeng/RPEval.
Expectation Confirmation Preference Optimization for Multi-Turn Conversational Recommendation Agent
Jun 17, 2025Recent advancements in Large Language Models (LLMs) have significantly propelled the development of Conversational Recommendation Agents (CRAs). However, these agents often generate short-sighted responses that fail to sustain user guidance and meet expectations. Although preference optimization has proven effective in aligning LLMs with user expectations, it remains costly and performs poorly in multi-turn dialogue. To address this challenge, we introduce a novel multi-turn preference optimization (MTPO) paradigm ECPO, which leverages Expectation Confirmation Theory to explicitly model the evolution of user satisfaction throughout multi-turn dialogues, uncovering the underlying causes of dissatisfaction. These causes can be utilized to support targeted optimization of unsatisfactory responses, thereby achieving turn-level preference optimization. ECPO ingeniously eliminates the significant sampling overhead of existing MTPO methods while ensuring the optimization process drives meaningful improvements. To support ECPO, we introduce an LLM-based user simulator, AILO, to simulate user feedback and perform expectation confirmation during conversational recommendations. Experimental results show that ECPO significantly enhances CRA's interaction capabilities, delivering notable improvements in both efficiency and effectiveness over existing MTPO methods.
HF4Rec: Human-Like Feedback-Driven Optimization Framework for Explainable Recommendation
Apr 19, 2025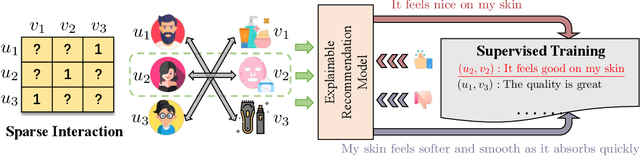

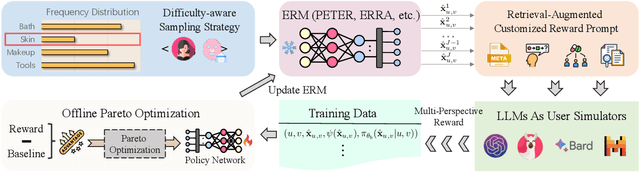
Recent advancements in explainable recommendation have greatly bolstered user experience by elucidating the decision-making rationale. However, the existing methods actually fail to provide effective feedback signals for potentially better or worse generated explanations due to their reliance on traditional supervised learning paradigms in sparse interaction data. To address these issues, we propose a novel human-like feedback-driven optimization framework. This framework employs a dynamic interactive optimization mechanism for achieving human-centered explainable requirements without incurring high labor costs. Specifically, we propose to utilize large language models (LLMs) as human simulators to predict human-like feedback for guiding the learning process. To enable the LLMs to deeply understand the task essence and meet user's diverse personalized requirements, we introduce a human-induced customized reward scoring method, which helps stimulate the language understanding and logical reasoning capabilities of LLMs. Furthermore, considering the potential conflicts between different perspectives of explanation quality, we introduce a principled Pareto optimization that transforms the multi-perspective quality enhancement task into a multi-objective optimization problem for improving explanation performance. At last, to achieve efficient model training, we design an off-policy optimization pipeline. By incorporating a replay buffer and addressing the data distribution biases, we can effectively improve data utilization and enhance model generality. Extensive experiments on four datasets demonstrate the superiority of our approach.
Improving Retrospective Language Agents via Joint Policy Gradient Optimization
Mar 03, 2025In recent research advancements within the community, large language models (LLMs) have sparked great interest in creating autonomous agents. However, current prompt-based agents often heavily rely on large-scale LLMs. Meanwhile, although fine-tuning methods significantly enhance the capabilities of smaller LLMs, the fine-tuned agents often lack the potential for self-reflection and self-improvement. To address these challenges, we introduce a novel agent framework named RetroAct, which is a framework that jointly optimizes both task-planning and self-reflective evolution capabilities in language agents. Specifically, we develop a two-stage joint optimization process that integrates imitation learning and reinforcement learning, and design an off-policy joint policy gradient optimization algorithm with imitation learning regularization to enhance the data efficiency and training stability in agent tasks. RetroAct significantly improves the performance of open-source models, reduces dependency on closed-source LLMs, and enables fine-tuned agents to learn and evolve continuously. We conduct extensive experiments across various testing environments, demonstrating RetroAct has substantial improvements in task performance and decision-making processes.
Enhancing Recommendation Explanations through User-Centric Refinement
Feb 17, 2025

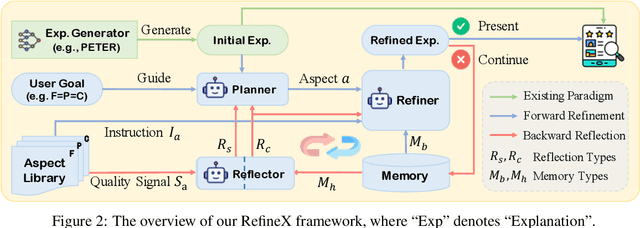

Generating natural language explanations for recommendations has become increasingly important in recommender systems. Traditional approaches typically treat user reviews as ground truth for explanations and focus on improving review prediction accuracy by designing various model architectures. However, due to limitations in data scale and model capability, these explanations often fail to meet key user-centric aspects such as factuality, personalization, and sentiment coherence, significantly reducing their overall helpfulness to users. In this paper, we propose a novel paradigm that refines initial explanations generated by existing explainable recommender models during the inference stage to enhance their quality in multiple aspects. Specifically, we introduce a multi-agent collaborative refinement framework based on large language models. To ensure alignment between the refinement process and user demands, we employ a plan-then-refine pattern to perform targeted modifications. To enable continuous improvements, we design a hierarchical reflection mechanism that provides feedback on the refinement process from both strategic and content perspectives. Extensive experiments on three datasets demonstrate the effectiveness of our framework.
Large Language Model-based Human-Agent Collaboration for Complex Task Solving
Feb 20, 2024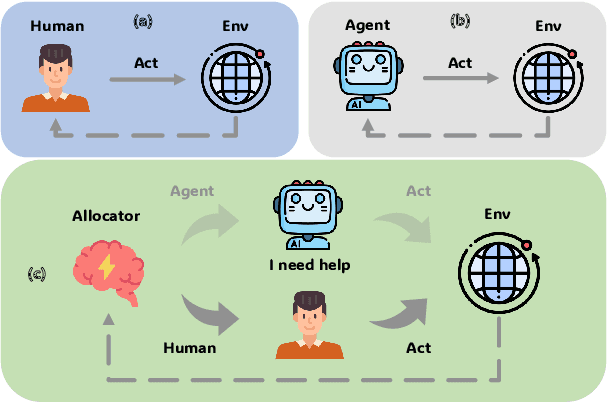
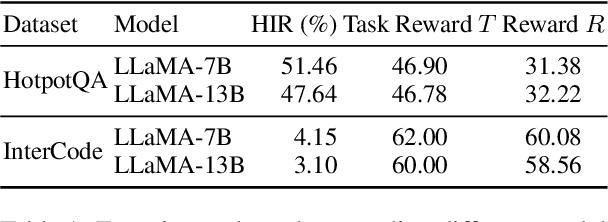
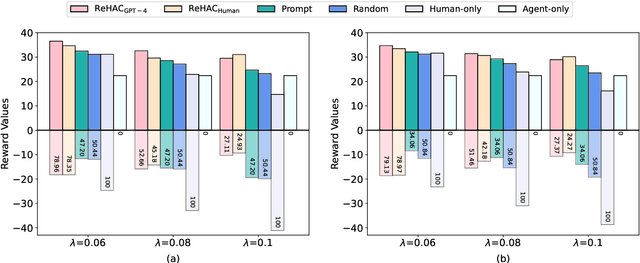
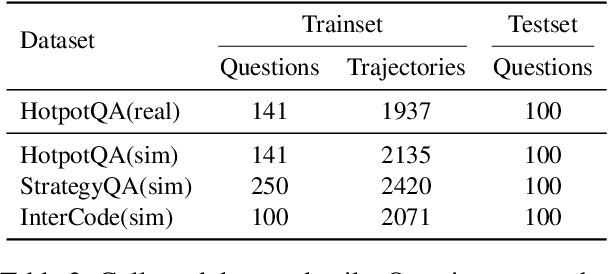
In recent developments within the research community, the integration of Large Language Models (LLMs) in creating fully autonomous agents has garnered significant interest. Despite this, LLM-based agents frequently demonstrate notable shortcomings in adjusting to dynamic environments and fully grasping human needs. In this work, we introduce the problem of LLM-based human-agent collaboration for complex task-solving, exploring their synergistic potential. In addition, we propose a Reinforcement Learning-based Human-Agent Collaboration method, ReHAC. This approach includes a policy model designed to determine the most opportune stages for human intervention within the task-solving process. We construct a human-agent collaboration dataset to train this policy model in an offline reinforcement learning environment. Our validation tests confirm the model's effectiveness. The results demonstrate that the synergistic efforts of humans and LLM-based agents significantly improve performance in complex tasks, primarily through well-planned, limited human intervention. Datasets and code are available at: https://github.com/XueyangFeng/ReHAC.
A Survey on Large Language Model based Autonomous Agents
Sep 07, 2023Autonomous agents have long been a prominent research focus in both academic and industry communities. Previous research in this field often focuses on training agents with limited knowledge within isolated environments, which diverges significantly from human learning processes, and thus makes the agents hard to achieve human-like decisions. Recently, through the acquisition of vast amounts of web knowledge, large language models (LLMs) have demonstrated remarkable potential in achieving human-level intelligence. This has sparked an upsurge in studies investigating LLM-based autonomous agents. In this paper, we present a comprehensive survey of these studies, delivering a systematic review of the field of LLM-based autonomous agents from a holistic perspective. More specifically, we first discuss the construction of LLM-based autonomous agents, for which we propose a unified framework that encompasses a majority of the previous work. Then, we present a comprehensive overview of the diverse applications of LLM-based autonomous agents in the fields of social science, natural science, and engineering. Finally, we delve into the evaluation strategies commonly used for LLM-based autonomous agents. Based on the previous studies, we also present several challenges and future directions in this field. To keep track of this field and continuously update our survey, we maintain a repository of relevant references at https://github.com/Paitesanshi/LLM-Agent-Survey.
Fairness-aware Cross-Domain Recommendation
Feb 01, 2023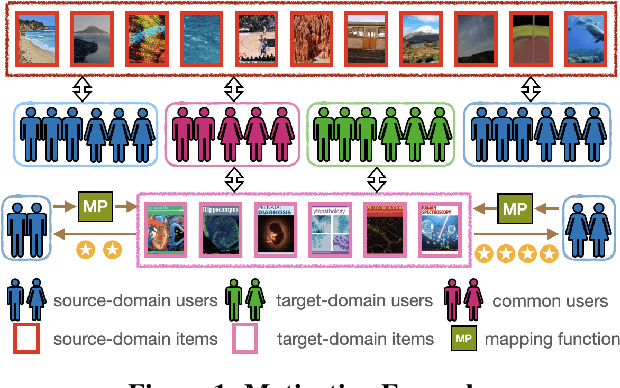
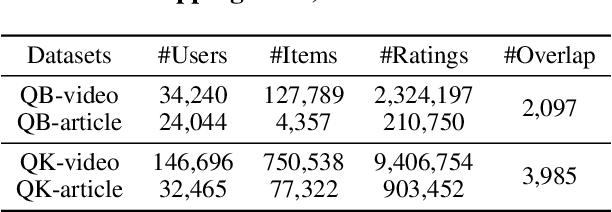
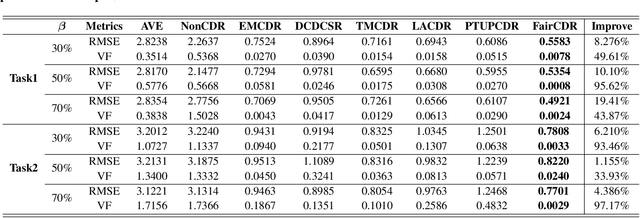
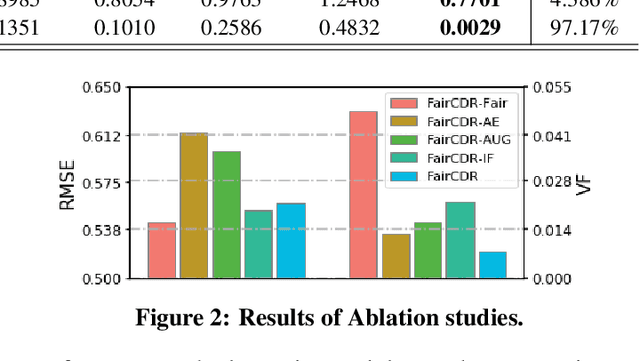
Cross-Domain Recommendation (CDR) is an effective way to alleviate the cold-start problem. However, previous work severely ignores fairness and bias when learning the mapping function, which is used to obtain the representations for fresh users in the target domain. To study this problem, in this paper, we propose a Fairness-aware Cross-Domain Recommendation model, called FairCDR. Our method achieves user-oriented group fairness by learning the fairness-aware mapping function. Since the overlapping data are quite limited and distributionally biased, FairCDR leverages abundant non-overlapping users and interactions to help alleviate these problems. Considering that each individual has different influence on model fairness, we propose a new reweighing method based on Influence Function (IF) to reduce unfairness while maintaining recommendation accuracy. Extensive experiments are conducted to demonstrate the effectiveness of our model.