 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Recommendation Explanations through User-Centric Refinement
Paper and Code
Feb 17, 2025

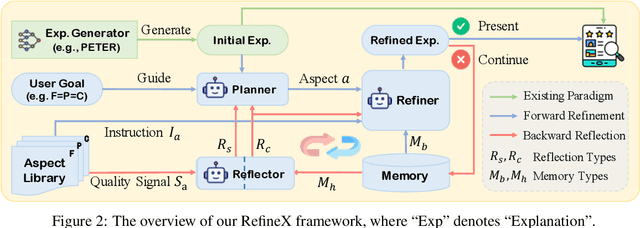

Generating natural language explanations for recommendations has become increasingly important in recommender systems. Traditional approaches typically treat user reviews as ground truth for explanations and focus on improving review prediction accuracy by designing various model architectures. However, due to limitations in data scale and model capability, these explanations often fail to meet key user-centric aspects such as factuality, personalization, and sentiment coherence, significantly reducing their overall helpfulness to users. In this paper, we propose a novel paradigm that refines initial explanations generated by existing explainable recommender models during the inference stage to enhance their quality in multiple aspects. Specifically, we introduce a multi-agent collaborative refinement framework based on large language models. To ensure alignment between the refinement process and user demands, we employ a plan-then-refine pattern to perform targeted modifications. To enable continuous improvements, we design a hierarchical reflection mechanism that provides feedback on the refinement process from both strategic and content perspectives. Extensive experiments on three datasets demonstrate the effectiveness of our framework.