 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: The Last Line of Defense: On Backdoor Defense Evaluation
Nov 17, 2025Backdoor attacks pose a significant threat to deep learning models by implanting hidden vulnerabilities that can be activated by malicious inputs. While numerous defenses have been proposed to mitigate these attacks, the heterogeneous landscape of evaluation methodologies hinders fair comparison between defenses. This work presents a systematic (meta-)analysis of backdoor defenses through a comprehensive literature review and empirical evaluation. We analyzed 183 backdoor defense papers published between 2018 and 2025 across major AI and security venues, examining the properties and evaluation methodologies of these defenses. Our analysis reveals significant inconsistencies in experimental setups, evaluation metrics, and threat model assumptions in the literature. Through extensive experiments involving three datasets (MNIST, CIFAR-100, ImageNet-1K), four model architectures (ResNet-18, VGG-19, ViT-B/16, DenseNet-121), 16 representative defenses, and five commonly used attacks, totaling over 3\,000 experiments, we demonstrate that defense effectiveness varies substantially across different evaluation setups. We identify critical gaps in current evaluation practices, including insufficient reporting of computational overhead and behavior under benign conditions, bias in hyperparameter selection, and incomplete experimentation. Based on our findings, we provide concrete challenges and well-motivated recommendations to standardize and improve future defense evaluations. Our work aims to equip researchers and industry practitioners with actionable insights for developing, assessing, and deploying defenses to different systems.
Towards Efficient Key-Value Cache Management for Prefix Prefilling in LLM Inference
May 28, 2025The increasing adoption of large language models (LLMs) with extended context windows necessitates efficient Key-Value Cache (KVC) management to optimize inference performance. Inference workloads like Retrieval-Augmented Generation (RAG) and agents exhibit high cache reusability, making efficient caching critical to reducing redundancy and improving speed. We analyze real-world KVC access patterns using publicly available traces and evaluate commercial key-value stores like Redis and state-of-the-art RDMA-based systems (CHIME [1] and Sherman [2]) for KVC metadata management. Our work demonstrates the lack of tailored storage solution for KVC prefilling, underscores the need for an efficient distributed caching system with optimized metadata management for LLM workloads, and provides insights into designing improved KVC management systems for scalable, low-latency inference.
Towards Backdoor Stealthiness in Model Parameter Space
Jan 10, 2025



Recent research on backdoor stealthiness focuses mainly on indistinguishable triggers in input space and inseparable backdoor representations in feature space, aiming to circumvent backdoor defenses that examine these respective spaces. However, existing backdoor attacks are typically designed to resist a specific type of backdoor defense without considering the diverse range of defense mechanisms. Based on this observation, we pose a natural question: Are current backdoor attacks truly a real-world threat when facing diverse practical defenses? To answer this question, we examine 12 common backdoor attacks that focus on input-space or feature-space stealthiness and 17 diverse representative defenses. Surprisingly, we reveal a critical blind spot: Backdoor attacks designed to be stealthy in input and feature spaces can be mitigated by examining backdoored models in parameter space. To investigate the underlying causes behind this common vulnerability, we study the characteristics of backdoor attacks in the parameter space. Notably, we find that input- and feature-space attacks introduce prominent backdoor-related neurons in parameter space, which are not thoroughly considered by current backdoor attacks. Taking comprehensive stealthiness into account, we propose a novel supply-chain attack called Grond. Grond limits the parameter changes by a simple yet effective module, Adversarial Backdoor Injection (ABI), which adaptively increases the parameter-space stealthiness during the backdoor injection. Extensive experiments demonstrate that Grond outperforms all 12 backdoor attacks against state-of-the-art (including adaptive) defenses on CIFAR-10, GTSRB, and a subset of ImageNet. In addition, we show that ABI consistently improves the effectiveness of common backdoor attacks.
RescueADI: Adaptive Disaster Interpretation in Remote Sensing Images with Autonomous Agents
Oct 17, 2024



Current methods for disaster scene interpretation in remote sensing images (RSIs) mostly focus on isolated tasks such as segmentation, detection, or visual question-answering (VQA). However, current interpretation methods often fail at tasks that require the combination of multiple perception methods and specialized tools. To fill this gap, this paper introduces Adaptive Disaster Interpretation (ADI), a novel task designed to solve requests by planning and executing multiple sequentially correlative interpretation tasks to provide a comprehensive analysis of disaster scenes. To facilitate research and application in this area, we present a new dataset named RescueADI, which contains high-resolution RSIs with annotations for three connected aspects: planning, perception, and recognition. The dataset includes 4,044 RSIs, 16,949 semantic masks, 14,483 object bounding boxes, and 13,424 interpretation requests across nine challenging request types. Moreover, we propose a new disaster interpretation method employing autonomous agents driven by large language models (LLMs) for task planning and execution, proving its efficacy in handling complex disaster interpretations. The proposed agent-based method solves various complex interpretation requests such as counting, area calculation, and path-finding without human intervention, which traditional single-task approaches cannot handle effectively. Experimental results on RescueADI demonstrate the feasibility of the proposed task and show that our method achieves an accuracy 9% higher than existing VQA methods, highlighting its advantages over conventional disaster interpretation approaches. The dataset will be publicly available.
TopoNAS: Boosting Search Efficiency of Gradient-based NAS via Topological Simplification
Aug 02, 2024Improving search efficiency serves as one of the crucial objectives of Neural Architecture Search (NAS). However, many current approaches ignore the universality of the search strategy and fail to reduce the computational redundancy during the search process, especially in one-shot NAS architectures. Besides, current NAS methods show invalid reparameterization in non-linear search space, leading to poor efficiency in common search spaces like DARTS. In this paper, we propose TopoNAS, a model-agnostic approach for gradient-based one-shot NAS that significantly reduces searching time and memory usage by topological simplification of searchable paths. Firstly, we model the non-linearity in search spaces to reveal the parameterization difficulties. To improve the search efficiency, we present a topological simplification method and iteratively apply module-sharing strategies to simplify the topological structure of searchable paths. In addition, a kernel normalization technique is also proposed to preserve the search accuracy. Experimental results on the NASBench201 benchmark with various search spaces demonstrate the effectiveness of our method. It proves the proposed TopoNAS enhances the performance of various architectures in terms of search efficiency while maintaining a high level of accuracy. The project page is available at https://xdedss.github.io/topo_simplification.
Continual Panoptic Perception: Towards Multi-modal Incremental Interpretation of Remote Sensing Images
Jul 19, 2024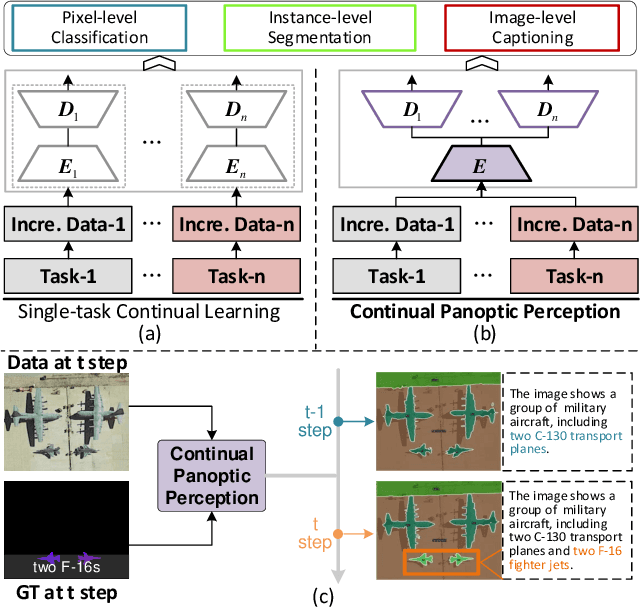
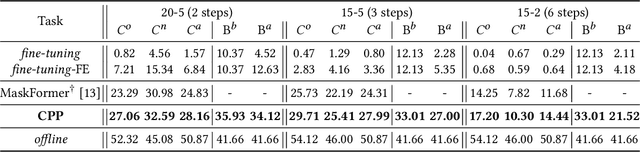
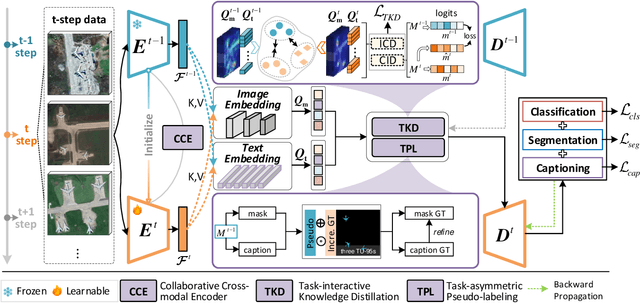

Continual learning (CL) breaks off the one-way training manner and enables a model to adapt to new data, semantics and tasks continuously. However, current CL methods mainly focus on single tasks. Besides, CL models are plagued by catastrophic forgetting and semantic drift since the lack of old data, which often occurs in remote-sensing interpretation due to the intricate fine-grained semantics. In this paper, we propose Continual Panoptic Perception (CPP), a unified continual learning model that leverages multi-task joint learning covering pixel-level classification, instance-level segmentation and image-level perception for universal interpretation in remote sensing images. Concretely, we propose a collaborative cross-modal encoder (CCE) to extract the input image features, which supports pixel classification and caption generation synchronously. To inherit the knowledge from the old model without exemplar memory, we propose a task-interactive knowledge distillation (TKD) method, which leverages cross-modal optimization and task-asymmetric pseudo-labeling (TPL) to alleviate catastrophic forgetting. Furthermore, we also propose a joint optimization mechanism to achieve end-to-end multi-modal panoptic perception. Experimental results on the fine-grained panoptic perception dataset validate the effectiveness of the proposed model, and also prove that joint optimization can boost sub-task CL efficiency with over 13\% relative improvement on panoptic quality.
The infrastructure powering IBM's Gen AI model development
Jul 07, 2024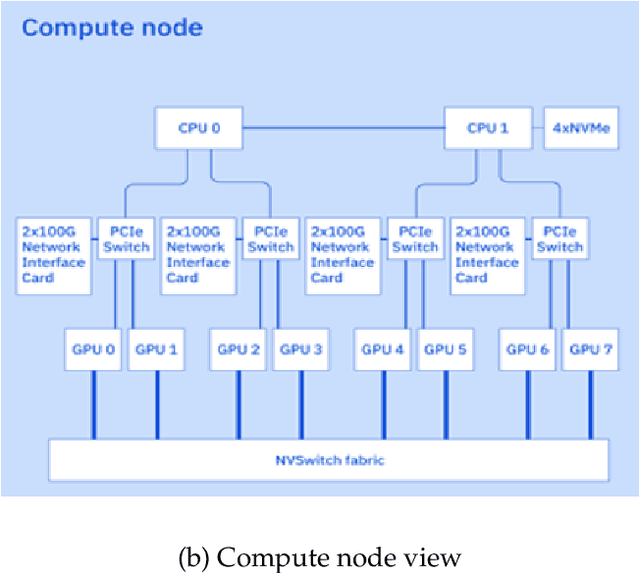
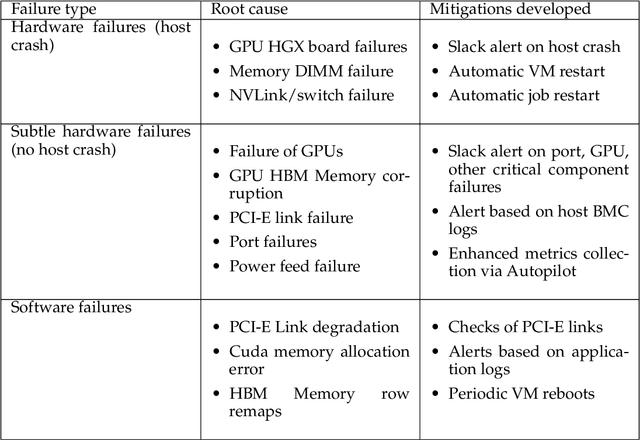
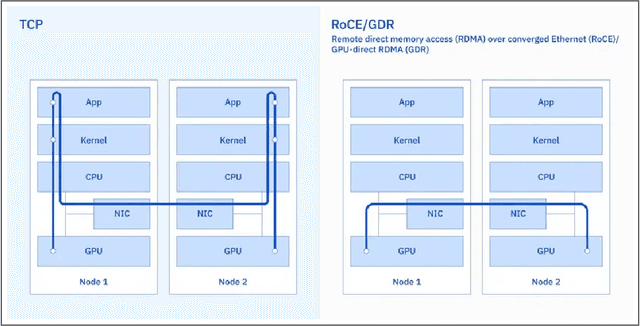
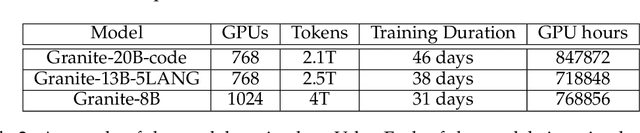
AI Infrastructure plays a key role in the speed and cost-competitiveness of developing and deploying advanced AI models. The current demand for powerful AI infrastructure for model training is driven by the emergence of generative AI and foundational models, where on occasion thousands of GPUs must cooperate on a single training job for the model to be trained in a reasonable time. Delivering efficient and high-performing AI training requires an end-to-end solution that combines hardware, software and holistic telemetry to cater for multiple types of AI workloads. In this report, we describe IBM's hybrid cloud infrastructure that powers our generative AI model development. This infrastructure includes (1) Vela: an AI-optimized supercomputing capability directly integrated into the IBM Cloud, delivering scalable, dynamic, multi-tenant and geographically distributed infrastructure for large-scale model training and other AI workflow steps and (2) Blue Vela: a large-scale, purpose-built, on-premises hosting environment that is optimized to support our largest and most ambitious AI model training tasks. Vela provides IBM with the dual benefit of high performance for internal use along with the flexibility to adapt to an evolving commercial landscape. Blue Vela provides us with the benefits of rapid development of our largest and most ambitious models, as well as future-proofing against the evolving model landscape in the industry. Taken together, they provide IBM with the ability to rapidly innovate in the development of both AI models and commercial offerings.
BAN: Detecting Backdoors Activated by Adversarial Neuron Noise
May 30, 2024



Backdoor attacks on deep learning represent a recent threat that has gained significant attention in the research community. Backdoor defenses are mainly based on backdoor inversion, which has been shown to be generic, model-agnostic, and applicable to practical threat scenarios. State-of-the-art backdoor inversion recovers a mask in the feature space to locate prominent backdoor features, where benign and backdoor features can be disentangled. However, it suffers from high computational overhead, and we also find that it overly relies on prominent backdoor features that are highly distinguishable from benign features. To tackle these shortcomings, this paper improves backdoor feature inversion for backdoor detection by incorporating extra neuron activation information. In particular, we adversarially increase the loss of backdoored models with respect to weights to activate the backdoor effect, based on which we can easily differentiate backdoored and clean models. Experimental results demonstrate our defense, BAN, is 1.37$\times$ (on CIFAR-10) and 5.11$\times$ (on ImageNet200) more efficient with 9.99% higher detect success rate than the state-of-the-art defense BTI-DBF. Our code and trained models are publicly available.\url{https://anonymous.4open.science/r/ban-4B32}
Panoptic Perception: A Novel Task and Fine-grained Dataset for Universal Remote Sensing Image Interpretation
Apr 06, 2024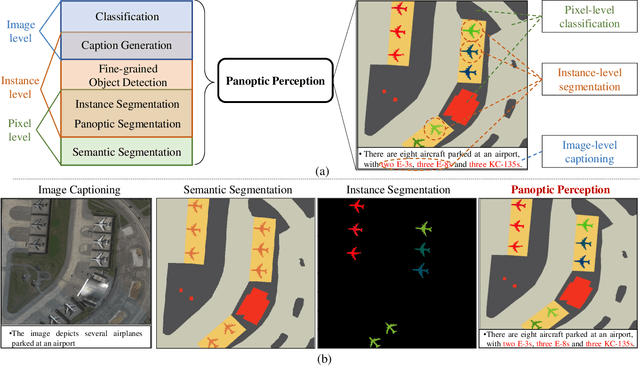
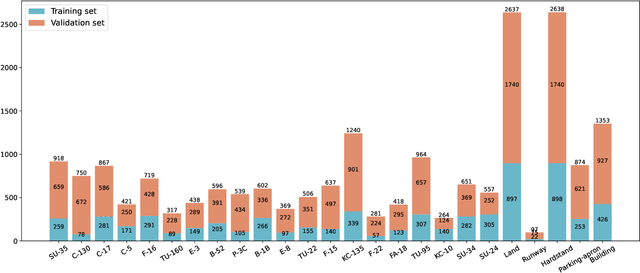
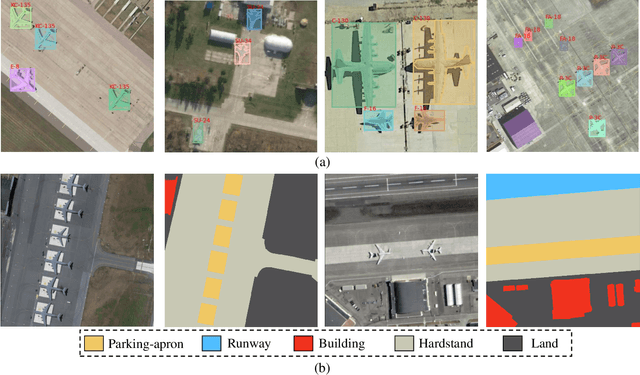
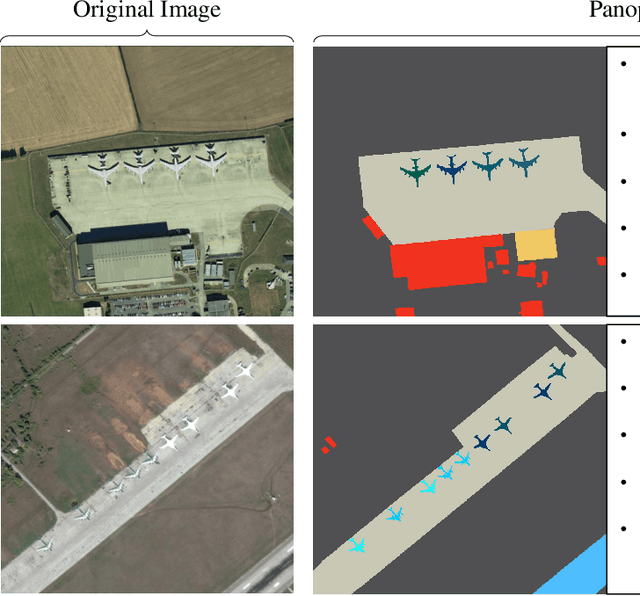
Current remote-sensing interpretation models often focus on a single task such as detection, segmentation, or caption. However, the task-specific designed models are unattainable to achieve the comprehensive multi-level interpretation of images. The field also lacks support for multi-task joint interpretation datasets. In this paper, we propose Panoptic Perception, a novel task and a new fine-grained dataset (FineGrip) to achieve a more thorough and universal interpretation for RSIs. The new task, 1) integrates pixel-level, instance-level, and image-level information for universal image perception, 2) captures image information from coarse to fine granularity, achieving deeper scene understanding and description, and 3) enables various independent tasks to complement and enhance each other through multi-task learning. By emphasizing multi-task interactions and the consistency of perception results, this task enables the simultaneous processing of fine-grained foreground instance segmentation, background semantic segmentation, and global fine-grained image captioning. Concretely, the FineGrip dataset includes 2,649 remote sensing images, 12,054 fine-grained instance segmentation masks belonging to 20 foreground things categories, 7,599 background semantic masks for 5 stuff classes and 13,245 captioning sentences. Furthermore, we propose a joint optimization-based panoptic perception model. Experimental results on FineGrip demonstrate the feasibility of the panoptic perception task and the beneficial effect of multi-task joint optimization on individual tasks. The dataset will be publicly available.
Beyond Neural-on-Neural Approaches to Speaker Gender Protection
Jun 30, 2023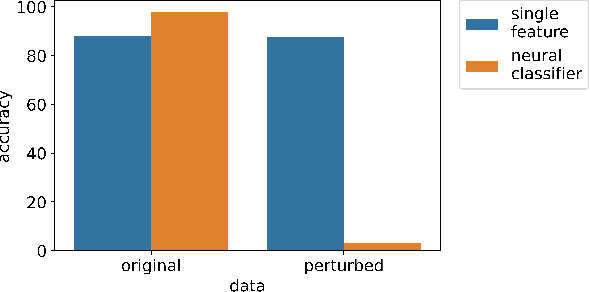
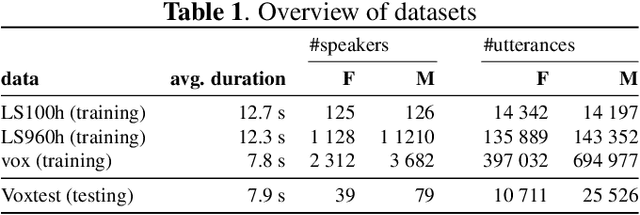

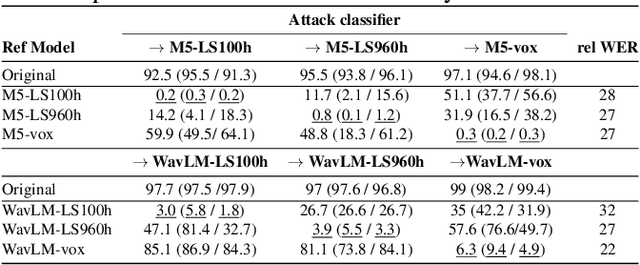
Recent research has proposed approaches that modify speech to defend against gender inference attacks. The goal of these protection algorithms is to control the availability of information about a speaker's gender, a privacy-sensitive attribute. Currently, the common practice for developing and testing gender protection algorithms is "neural-on-neural", i.e., perturbations are generated and tested with a neural network. In this paper, we propose to go beyond this practice to strengthen the study of gender protection. First, we demonstrate the importance of testing gender inference attacks that are based on speech features historically developed by speech scientists, alongside the conventionally used neural classifiers. Next, we argue that researchers should use speech features to gain insight into how protective modifications change the speech signal. Finally, we point out that gender-protection algorithms should be compared with novel "vocal adversaries", human-executed voice adaptations, in order to improve interpretability and enable before-the-mic protection.