 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving Without Ending: Unifying Multimodal Incremental Learning for Continual Panoptic Perception
Jan 22, 2026Continual learning (CL) is a great endeavour in developing intelligent perception AI systems. However, the pioneer research has predominantly focus on single-task CL, which restricts the potential in multi-task and multimodal scenarios. Beyond the well-known issue of catastrophic forgetting, the multi-task CL also brings semantic obfuscation across multimodal alignment, leading to severe model degradation during incremental training steps. In this paper, we extend CL to continual panoptic perception (CPP), integrating multimodal and multi-task CL to enhance comprehensive image perception through pixel-level, instance-level, and image-level joint interpretation. We formalize the CL task in multimodal scenarios and propose an end-to-end continual panoptic perception model. Concretely, CPP model features a collaborative cross-modal encoder (CCE) for multimodal embedding. We also propose a malleable knowledge inheritance module via contrastive feature distillation and instance distillation, addressing catastrophic forgetting from task-interactive boosting manner. Furthermore, we propose a cross-modal consistency constraint and develop CPP+, ensuring multimodal semantic alignment for model updating under multi-task incremental scenarios. Additionally, our proposed model incorporates an asymmetric pseudo-labeling manner, enabling model evolving without exemplar replay. Extensive experiments on multimodal datasets and diverse CL tasks demonstrate the superiority of the proposed model, particularly in fine-grained CL tasks.
Reconciling Semantic Controllability and Diversity for Remote Sensing Image Synthesis with Hybrid Semantic Embedding
Nov 22, 2024



Significant advancements have been made in semantic image synthesis in remote sensing. However, existing methods still face formidable challenges in balancing semantic controllability and diversity. In this paper, we present a Hybrid Semantic Embedding Guided Generative Adversarial Network (HySEGGAN) for controllable and efficient remote sensing image synthesis. Specifically, HySEGGAN leverages hierarchical information from a single source. Motivated by feature description, we propose a hybrid semantic Embedding method, that coordinates fine-grained local semantic layouts to characterize the geometric structure of remote sensing objects without extra information. Besides, a Semantic Refinement Network (SRN) is introduced, incorporating a novel loss function to ensure fine-grained semantic feedback. The proposed approach mitigates semantic confusion and prevents geometric pattern collapse. Experimental results indicate that the method strikes an excellent balance between semantic controllability and diversity. Furthermore, HySEGGAN significantly improves the quality of synthesized images and achieves state-of-the-art performance as a data augmentation technique across multiple datasets for downstream tasks.
RescueADI: Adaptive Disaster Interpretation in Remote Sensing Images with Autonomous Agents
Oct 17, 2024



Current methods for disaster scene interpretation in remote sensing images (RSIs) mostly focus on isolated tasks such as segmentation, detection, or visual question-answering (VQA). However, current interpretation methods often fail at tasks that require the combination of multiple perception methods and specialized tools. To fill this gap, this paper introduces Adaptive Disaster Interpretation (ADI), a novel task designed to solve requests by planning and executing multiple sequentially correlative interpretation tasks to provide a comprehensive analysis of disaster scenes. To facilitate research and application in this area, we present a new dataset named RescueADI, which contains high-resolution RSIs with annotations for three connected aspects: planning, perception, and recognition. The dataset includes 4,044 RSIs, 16,949 semantic masks, 14,483 object bounding boxes, and 13,424 interpretation requests across nine challenging request types. Moreover, we propose a new disaster interpretation method employing autonomous agents driven by large language models (LLMs) for task planning and execution, proving its efficacy in handling complex disaster interpretations. The proposed agent-based method solves various complex interpretation requests such as counting, area calculation, and path-finding without human intervention, which traditional single-task approaches cannot handle effectively. Experimental results on RescueADI demonstrate the feasibility of the proposed task and show that our method achieves an accuracy 9% higher than existing VQA methods, highlighting its advantages over conventional disaster interpretation approaches. The dataset will be publicly available.
TopoNAS: Boosting Search Efficiency of Gradient-based NAS via Topological Simplification
Aug 02, 2024Improving search efficiency serves as one of the crucial objectives of Neural Architecture Search (NAS). However, many current approaches ignore the universality of the search strategy and fail to reduce the computational redundancy during the search process, especially in one-shot NAS architectures. Besides, current NAS methods show invalid reparameterization in non-linear search space, leading to poor efficiency in common search spaces like DARTS. In this paper, we propose TopoNAS, a model-agnostic approach for gradient-based one-shot NAS that significantly reduces searching time and memory usage by topological simplification of searchable paths. Firstly, we model the non-linearity in search spaces to reveal the parameterization difficulties. To improve the search efficiency, we present a topological simplification method and iteratively apply module-sharing strategies to simplify the topological structure of searchable paths. In addition, a kernel normalization technique is also proposed to preserve the search accuracy. Experimental results on the NASBench201 benchmark with various search spaces demonstrate the effectiveness of our method. It proves the proposed TopoNAS enhances the performance of various architectures in terms of search efficiency while maintaining a high level of accuracy. The project page is available at https://xdedss.github.io/topo_simplification.
Learning at a Glance: Towards Interpretable Data-limited Continual Semantic Segmentation via Semantic-Invariance Modelling
Jul 22, 2024Continual semantic segmentation (CSS) based on incremental learning (IL) is a great endeavour in developing human-like segmentation models. However, current CSS approaches encounter challenges in the trade-off between preserving old knowledge and learning new ones, where they still need large-scale annotated data for incremental training and lack interpretability. In this paper, we present Learning at a Glance (LAG), an efficient, robust, human-like and interpretable approach for CSS. Specifically, LAG is a simple and model-agnostic architecture, yet it achieves competitive CSS efficiency with limited incremental data. Inspired by human-like recognition patterns, we propose a semantic-invariance modelling approach via semantic features decoupling that simultaneously reconciles solid knowledge inheritance and new-term learning. Concretely, the proposed decoupling manner includes two ways, i.e., channel-wise decoupling and spatial-level neuron-relevant semantic consistency. Our approach preserves semantic-invariant knowledge as solid prototypes to alleviate catastrophic forgetting, while also constraining sample-specific contents through an asymmetric contrastive learning method to enhance model robustness during IL steps. Experimental results in multiple datasets validate the effectiveness of the proposed method. Furthermore, we introduce a novel CSS protocol that better reflects realistic data-limited CSS settings, and LAG achieves superior performance under multiple data-limited conditions.
Continual Panoptic Perception: Towards Multi-modal Incremental Interpretation of Remote Sensing Images
Jul 19, 2024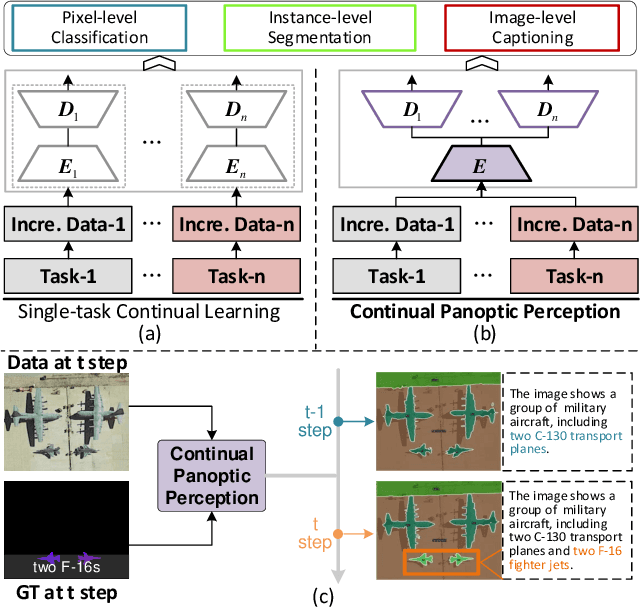
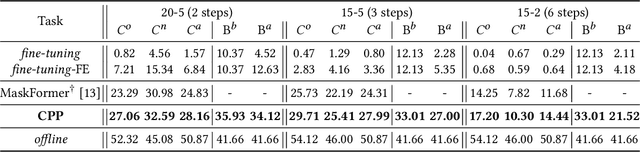
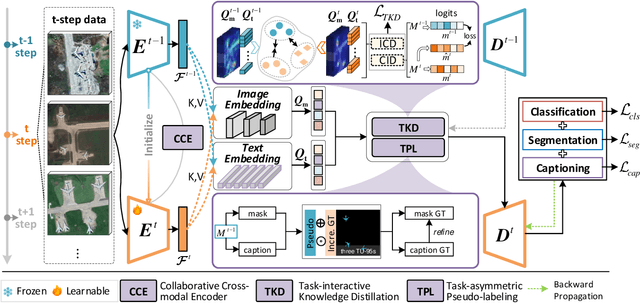

Continual learning (CL) breaks off the one-way training manner and enables a model to adapt to new data, semantics and tasks continuously. However, current CL methods mainly focus on single tasks. Besides, CL models are plagued by catastrophic forgetting and semantic drift since the lack of old data, which often occurs in remote-sensing interpretation due to the intricate fine-grained semantics. In this paper, we propose Continual Panoptic Perception (CPP), a unified continual learning model that leverages multi-task joint learning covering pixel-level classification, instance-level segmentation and image-level perception for universal interpretation in remote sensing images. Concretely, we propose a collaborative cross-modal encoder (CCE) to extract the input image features, which supports pixel classification and caption generation synchronously. To inherit the knowledge from the old model without exemplar memory, we propose a task-interactive knowledge distillation (TKD) method, which leverages cross-modal optimization and task-asymmetric pseudo-labeling (TPL) to alleviate catastrophic forgetting. Furthermore, we also propose a joint optimization mechanism to achieve end-to-end multi-modal panoptic perception. Experimental results on the fine-grained panoptic perception dataset validate the effectiveness of the proposed model, and also prove that joint optimization can boost sub-task CL efficiency with over 13\% relative improvement on panoptic quality.
Panoptic Perception: A Novel Task and Fine-grained Dataset for Universal Remote Sensing Image Interpretation
Apr 06, 2024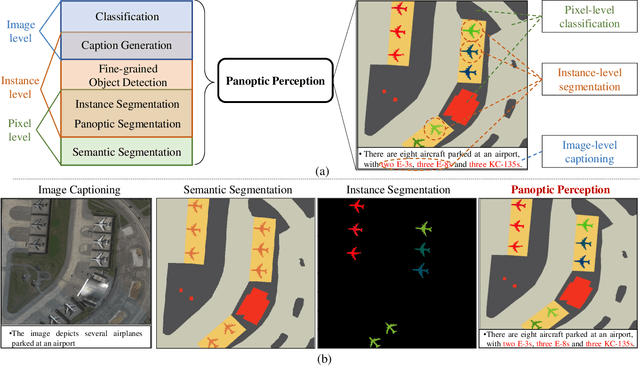
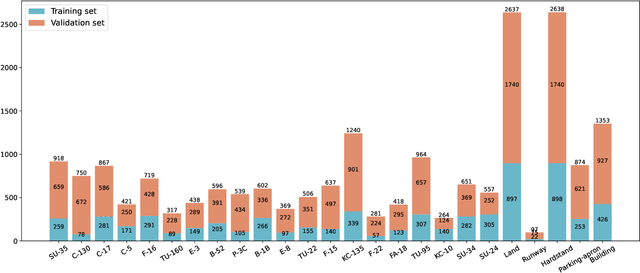
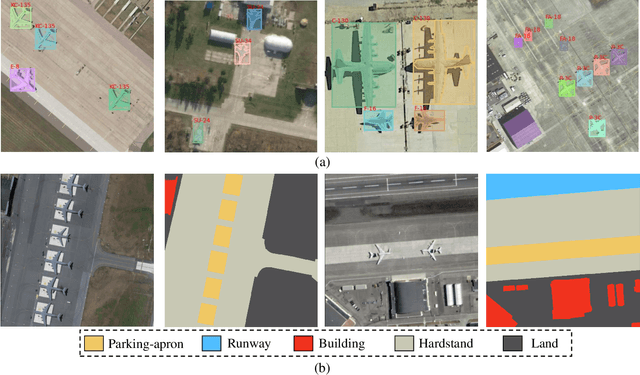
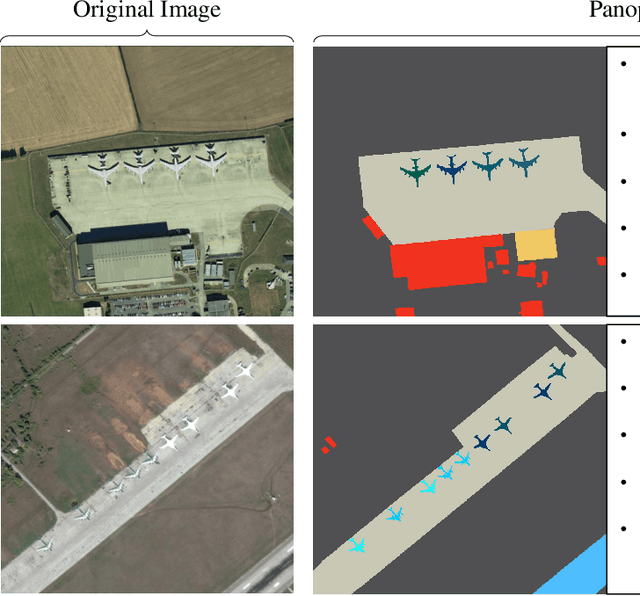
Current remote-sensing interpretation models often focus on a single task such as detection, segmentation, or caption. However, the task-specific designed models are unattainable to achieve the comprehensive multi-level interpretation of images. The field also lacks support for multi-task joint interpretation datasets. In this paper, we propose Panoptic Perception, a novel task and a new fine-grained dataset (FineGrip) to achieve a more thorough and universal interpretation for RSIs. The new task, 1) integrates pixel-level, instance-level, and image-level information for universal image perception, 2) captures image information from coarse to fine granularity, achieving deeper scene understanding and description, and 3) enables various independent tasks to complement and enhance each other through multi-task learning. By emphasizing multi-task interactions and the consistency of perception results, this task enables the simultaneous processing of fine-grained foreground instance segmentation, background semantic segmentation, and global fine-grained image captioning. Concretely, the FineGrip dataset includes 2,649 remote sensing images, 12,054 fine-grained instance segmentation masks belonging to 20 foreground things categories, 7,599 background semantic masks for 5 stuff classes and 13,245 captioning sentences. Furthermore, we propose a joint optimization-based panoptic perception model. Experimental results on FineGrip demonstrate the feasibility of the panoptic perception task and the beneficial effect of multi-task joint optimization on individual tasks. The dataset will be publicly available.
PETDet: Proposal Enhancement for Two-Stage Fine-Grained Object Detection
Dec 16, 2023



Fine-grained object detection (FGOD) extends object detection with the capability of fine-grained recognition. In recent two-stage FGOD methods, the region proposal serves as a crucial link between detection and fine-grained recognition. However, current methods overlook that some proposal-related procedures inherited from general detection are not equally suitable for FGOD, limiting the multi-task learning from generation, representation, to utilization. In this paper, we present PETDet (Proposal Enhancement for Two-stage fine-grained object detection) to better handle the sub-tasks in two-stage FGOD methods. Firstly, an anchor-free Quality Oriented Proposal Network (QOPN) is proposed with dynamic label assignment and attention-based decomposition to generate high-quality oriented proposals. Additionally, we present a Bilinear Channel Fusion Network (BCFN) to extract independent and discriminative features of the proposals. Furthermore, we design a novel Adaptive Recognition Loss (ARL) which offers guidance for the R-CNN head to focus on high-quality proposals. Extensive experiments validate the effectiveness of PETDet. Quantitative analysis reveals that PETDet with ResNet50 reaches state-of-the-art performance on various FGOD datasets, including FAIR1M-v1.0 (42.96 AP), FAIR1M-v2.0 (48.81 AP), MAR20 (85.91 AP) and ShipRSImageNet (74.90 AP). The proposed method also achieves superior compatibility between accuracy and inference speed. Our code and models will be released at https://github.com/canoe-Z/PETDet.
A Survey on Continual Semantic Segmentation: Theory, Challenge, Method and Application
Oct 22, 2023Continual learning, also known as incremental learning or life-long learning, stands at the forefront of deep learning and AI systems. It breaks through the obstacle of one-way training on close sets and enables continuous adaptive learning on open-set conditions. In the recent decade, continual learning has been explored and applied in multiple fields especially in computer vision covering classification, detection and segmentation tasks. Continual semantic segmentation (CSS), of which the dense prediction peculiarity makes it a challenging, intricate and burgeoning task. In this paper, we present a review of CSS, committing to building a comprehensive survey on problem formulations, primary challenges, universal datasets, neoteric theories and multifarious applications. Concretely, we begin by elucidating the problem definitions and primary challenges. Based on an in-depth investigation of relevant approaches, we sort out and categorize current CSS models into two main branches including \textit{data-replay} and \textit{data-free} sets. In each branch, the corresponding approaches are similarity-based clustered and thoroughly analyzed, following qualitative comparison and quantitative reproductions on relevant datasets. Besides, we also introduce four CSS specialities with diverse application scenarios and development tendencies. Furthermore, we develop a benchmark for CSS encompassing representative references, evaluation results and reproductions, which is available at~\url{https://github.com/YBIO/SurveyCSS}. We hope this survey can serve as a reference-worthy and stimulating contribution to the advancement of the life-long learning field, while also providing valuable perspectives for related fields.
Inherit with Distillation and Evolve with Contrast: Exploring Class Incremental Semantic Segmentation Without Exemplar Memory
Sep 27, 2023As a front-burner problem in incremental learning, class incremental semantic segmentation (CISS) is plagued by catastrophic forgetting and semantic drift. Although recent methods have utilized knowledge distillation to transfer knowledge from the old model, they are still unable to avoid pixel confusion, which results in severe misclassification after incremental steps due to the lack of annotations for past and future classes. Meanwhile data-replay-based approaches suffer from storage burdens and privacy concerns. In this paper, we propose to address CISS without exemplar memory and resolve catastrophic forgetting as well as semantic drift synchronously. We present Inherit with Distillation and Evolve with Contrast (IDEC), which consists of a Dense Knowledge Distillation on all Aspects (DADA) manner and an Asymmetric Region-wise Contrastive Learning (ARCL) module. Driven by the devised dynamic class-specific pseudo-labelling strategy, DADA distils intermediate-layer features and output-logits collaboratively with more emphasis on semantic-invariant knowledge inheritance. ARCL implements region-wise contrastive learning in the latent space to resolve semantic drift among known classes, current classes, and unknown classes. We demonstrate the effectiveness of our method on multiple CISS tasks by state-of-the-art performance, including Pascal VOC 2012, ADE20K and ISPRS datasets. Our method also shows superior anti-forgetting ability, particularly in multi-step CISS tasks.