 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: The Last Line of Defense: On Backdoor Defense Evaluation
Nov 17, 2025Backdoor attacks pose a significant threat to deep learning models by implanting hidden vulnerabilities that can be activated by malicious inputs. While numerous defenses have been proposed to mitigate these attacks, the heterogeneous landscape of evaluation methodologies hinders fair comparison between defenses. This work presents a systematic (meta-)analysis of backdoor defenses through a comprehensive literature review and empirical evaluation. We analyzed 183 backdoor defense papers published between 2018 and 2025 across major AI and security venues, examining the properties and evaluation methodologies of these defenses. Our analysis reveals significant inconsistencies in experimental setups, evaluation metrics, and threat model assumptions in the literature. Through extensive experiments involving three datasets (MNIST, CIFAR-100, ImageNet-1K), four model architectures (ResNet-18, VGG-19, ViT-B/16, DenseNet-121), 16 representative defenses, and five commonly used attacks, totaling over 3\,000 experiments, we demonstrate that defense effectiveness varies substantially across different evaluation setups. We identify critical gaps in current evaluation practices, including insufficient reporting of computational overhead and behavior under benign conditions, bias in hyperparameter selection, and incomplete experimentation. Based on our findings, we provide concrete challenges and well-motivated recommendations to standardize and improve future defense evaluations. Our work aims to equip researchers and industry practitioners with actionable insights for developing, assessing, and deploying defenses to different systems.
Towards Backdoor Stealthiness in Model Parameter Space
Jan 10, 2025



Recent research on backdoor stealthiness focuses mainly on indistinguishable triggers in input space and inseparable backdoor representations in feature space, aiming to circumvent backdoor defenses that examine these respective spaces. However, existing backdoor attacks are typically designed to resist a specific type of backdoor defense without considering the diverse range of defense mechanisms. Based on this observation, we pose a natural question: Are current backdoor attacks truly a real-world threat when facing diverse practical defenses? To answer this question, we examine 12 common backdoor attacks that focus on input-space or feature-space stealthiness and 17 diverse representative defenses. Surprisingly, we reveal a critical blind spot: Backdoor attacks designed to be stealthy in input and feature spaces can be mitigated by examining backdoored models in parameter space. To investigate the underlying causes behind this common vulnerability, we study the characteristics of backdoor attacks in the parameter space. Notably, we find that input- and feature-space attacks introduce prominent backdoor-related neurons in parameter space, which are not thoroughly considered by current backdoor attacks. Taking comprehensive stealthiness into account, we propose a novel supply-chain attack called Grond. Grond limits the parameter changes by a simple yet effective module, Adversarial Backdoor Injection (ABI), which adaptively increases the parameter-space stealthiness during the backdoor injection. Extensive experiments demonstrate that Grond outperforms all 12 backdoor attacks against state-of-the-art (including adaptive) defenses on CIFAR-10, GTSRB, and a subset of ImageNet. In addition, we show that ABI consistently improves the effectiveness of common backdoor attacks.
BAN: Detecting Backdoors Activated by Adversarial Neuron Noise
May 30, 2024



Backdoor attacks on deep learning represent a recent threat that has gained significant attention in the research community. Backdoor defenses are mainly based on backdoor inversion, which has been shown to be generic, model-agnostic, and applicable to practical threat scenarios. State-of-the-art backdoor inversion recovers a mask in the feature space to locate prominent backdoor features, where benign and backdoor features can be disentangled. However, it suffers from high computational overhead, and we also find that it overly relies on prominent backdoor features that are highly distinguishable from benign features. To tackle these shortcomings, this paper improves backdoor feature inversion for backdoor detection by incorporating extra neuron activation information. In particular, we adversarially increase the loss of backdoored models with respect to weights to activate the backdoor effect, based on which we can easily differentiate backdoored and clean models. Experimental results demonstrate our defense, BAN, is 1.37$\times$ (on CIFAR-10) and 5.11$\times$ (on ImageNet200) more efficient with 9.99% higher detect success rate than the state-of-the-art defense BTI-DBF. Our code and trained models are publicly available.\url{https://anonymous.4open.science/r/ban-4B32}
MIMIR: Masked Image Modeling for Mutual Information-based Adversarial Robustness
Dec 08, 2023



Vision Transformers (ViTs) achieve superior performance on various tasks compared to convolutional neural networks (CNNs), but ViTs are also vulnerable to adversarial attacks. Adversarial training is one of the most successful methods to build robust CNN models. Thus, recent works explored new methodologies for adversarial training of ViTs based on the differences between ViTs and CNNs, such as better training strategies, preventing attention from focusing on a single block, or discarding low-attention embeddings. However, these methods still follow the design of traditional supervised adversarial training, limiting the potential of adversarial training on ViTs. This paper proposes a novel defense method, MIMIR, which aims to build a different adversarial training methodology by utilizing Masked Image Modeling at pre-training. We create an autoencoder that accepts adversarial examples as input but takes the clean examples as the modeling target. Then, we create a mutual information (MI) penalty following the idea of the Information Bottleneck. Among the two information source inputs and corresponding adversarial perturbation, the perturbation information is eliminated due to the constraint of the modeling target. Next, we provide a theoretical analysis of MIMIR using the bounds of the MI penalty. We also design two adaptive attacks when the adversary is aware of the MIMIR defense and show that MIMIR still performs well. The experimental results show that MIMIR improves (natural and adversarial) accuracy on average by 4.19\% on CIFAR-10 and 5.52\% on ImageNet-1K, compared to baselines. On Tiny-ImageNet, we obtained improved natural accuracy of 2.99\% on average and comparable adversarial accuracy. Our code and trained models are publicly available\footnote{\url{https://anonymous.4open.science/r/MIMIR-5444/README.md}}.
IB-RAR: Information Bottleneck as Regularizer for Adversarial Robustness
Feb 09, 2023In this paper, we propose a novel method, IB-RAR, which uses Information Bottleneck (IB) to strengthen adversarial robustness for both adversarial training and non-adversarial-trained methods. We first use the IB theory to build regularizers as learning objectives in the loss function. Then, we filter out unnecessary features of intermediate representation according to their mutual information (MI) with labels, as the network trained with IB provides easily distinguishable MI for its features. Experimental results show that our method can be naturally combined with adversarial training and provides consistently better accuracy on new adversarial examples. Our method improves the accuracy by an average of 3.07% against five adversarial attacks for the VGG16 network, trained with three adversarial training benchmarks and the CIFAR-10 dataset. In addition, our method also provides good robustness for undefended methods, such as training with cross-entropy loss only. Finally, in the absence of adversarial training, the VGG16 network trained using our method and the CIFAR-10 dataset reaches an accuracy of 35.86% against PGD examples, while using all layers reaches 25.61% accuracy.
Universal Soldier: Using Universal Adversarial Perturbations for Detecting Backdoor Attacks
Feb 07, 2023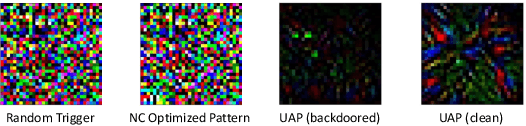
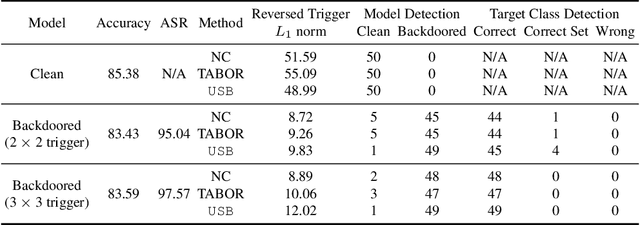

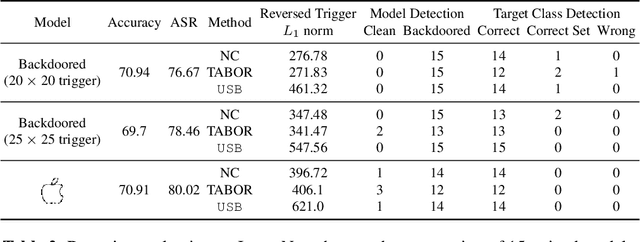
Deep learning models achieve excellent performance in numerous machine learning tasks. Yet, they suffer from security-related issues such as adversarial examples and poisoning (backdoor) attacks. A deep learning model may be poisoned by training with backdoored data or by modifying inner network parameters. Then, a backdoored model performs as expected when receiving a clean input, but it misclassifies when receiving a backdoored input stamped with a pre-designed pattern called "trigger". Unfortunately, it is difficult to distinguish between clean and backdoored models without prior knowledge of the trigger. This paper proposes a backdoor detection method by utilizing a special type of adversarial attack, universal adversarial perturbation (UAP), and its similarities with a backdoor trigger. We observe an intuitive phenomenon: UAPs generated from backdoored models need fewer perturbations to mislead the model than UAPs from clean models. UAPs of backdoored models tend to exploit the shortcut from all classes to the target class, built by the backdoor trigger. We propose a novel method called Universal Soldier for Backdoor detection (USB) and reverse engineering potential backdoor triggers via UAPs. Experiments on 345 models trained on several datasets show that USB effectively detects the injected backdoor and provides comparable or better results than state-of-the-art methods.