 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Soldier: Using Universal Adversarial Perturbations for Detecting Backdoor Attacks
Paper and Code
Feb 07, 2023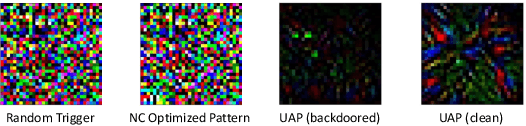
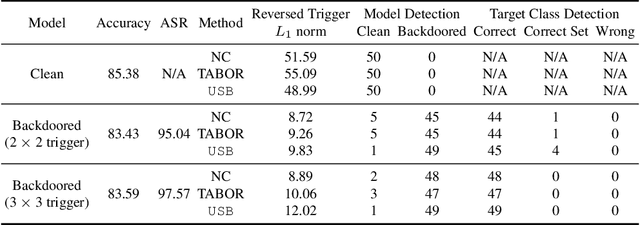

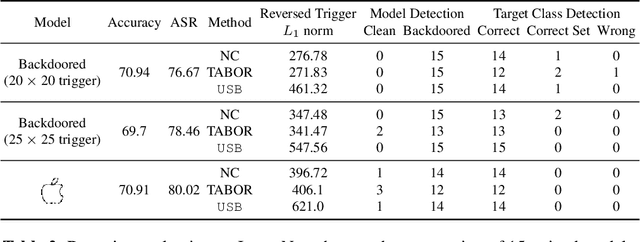
Deep learning models achieve excellent performance in numerous machine learning tasks. Yet, they suffer from security-related issues such as adversarial examples and poisoning (backdoor) attacks. A deep learning model may be poisoned by training with backdoored data or by modifying inner network parameters. Then, a backdoored model performs as expected when receiving a clean input, but it misclassifies when receiving a backdoored input stamped with a pre-designed pattern called "trigger". Unfortunately, it is difficult to distinguish between clean and backdoored models without prior knowledge of the trigger. This paper proposes a backdoor detection method by utilizing a special type of adversarial attack, universal adversarial perturbation (UAP), and its similarities with a backdoor trigger. We observe an intuitive phenomenon: UAPs generated from backdoored models need fewer perturbations to mislead the model than UAPs from clean models. UAPs of backdoored models tend to exploit the shortcut from all classes to the target class, built by the backdoor trigger. We propose a novel method called Universal Soldier for Backdoor detection (USB) and reverse engineering potential backdoor triggers via UAPs. Experiments on 345 models trained on several datasets show that USB effectively detects the injected backdoor and provides comparable or better results than state-of-the-art methods.