 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinetune Like You Pretrain: Boosting Zero-shot Adversarial Robustness in Vision-language Models
Apr 13, 2026Despite their impressive zero-shot abilities, vision-language models such as CLIP have been shown to be susceptible to adversarial attacks. To enhance its adversarial robustness, recent studies finetune the pretrained vision encoder of CLIP with adversarial examples on a proxy dataset such as ImageNet by aligning adversarial images with correct class labels. However, these methods overlook the important roles of training data distributions and learning objectives, resulting in reduced zero-shot capabilities and limited transferability of robustness across domains and datasets. In this work, we propose a simple yet effective paradigm AdvFLYP, which follows the training recipe of CLIP's pretraining process when performing adversarial finetuning to the model. Specifically, AdvFLYP finetunes CLIP with adversarial images created based on image-text pairs collected from the web, and match them with their corresponding texts via a contrastive loss. To alleviate distortion of adversarial image embeddings of noisy web images, we further propose to regularise AdvFLYP by penalising deviation of adversarial image features. We show that logit- and feature-level regularisation terms benefit robustness and clean accuracy, respectively. Extensive experiments on 14 downstream datasets spanning various domains show the superiority of our paradigm over mainstream practices. Our code and model weights are released at https://github.com/Sxing2/AdvFLYP.
Pay Less Attention to Function Words for Free Robustness of Vision-Language Models
Dec 09, 2025To address the trade-off between robustness and performance for robust VLM, we observe that function words could incur vulnerability of VLMs against cross-modal adversarial attacks, and propose Function-word De-Attention (FDA) accordingly to mitigate the impact of function words. Similar to differential amplifiers, our FDA calculates the original and the function-word cross-attention within attention heads, and differentially subtracts the latter from the former for more aligned and robust VLMs. Comprehensive experiments include 2 SOTA baselines under 6 different attacks on 2 downstream tasks, 3 datasets, and 3 models. Overall, our FDA yields an average 18/13/53% ASR drop with only 0.2/0.3/0.6% performance drops on the 3 tested models on retrieval, and a 90% ASR drop with a 0.3% performance gain on visual grounding. We demonstrate the scalability, generalization, and zero-shot performance of FDA experimentally, as well as in-depth ablation studies and analysis. Code will be made publicly at https://github.com/michaeltian108/FDA.
Adversarial Video Promotion Against Text-to-Video Retrieval
Aug 12, 2025Thanks to the development of cross-modal models, text-to-video retrieval (T2VR) is advancing rapidly, but its robustness remains largely unexamined. Existing attacks against T2VR are designed to push videos away from queries, i.e., suppressing the ranks of videos, while the attacks that pull videos towards selected queries, i.e., promoting the ranks of videos, remain largely unexplored. These attacks can be more impactful as attackers may gain more views/clicks for financial benefits and widespread (mis)information. To this end, we pioneer the first attack against T2VR to promote videos adversarially, dubbed the Video Promotion attack (ViPro). We further propose Modal Refinement (MoRe) to capture the finer-grained, intricate interaction between visual and textual modalities to enhance black-box transferability. Comprehensive experiments cover 2 existing baselines, 3 leading T2VR models, 3 prevailing datasets with over 10k videos, evaluated under 3 scenarios. All experiments are conducted in a multi-target setting to reflect realistic scenarios where attackers seek to promote the video regarding multiple queries simultaneously. We also evaluated our attacks for defences and imperceptibility. Overall, ViPro surpasses other baselines by over $30/10/4\%$ for white/grey/black-box settings on average. Our work highlights an overlooked vulnerability, provides a qualitative analysis on the upper/lower bound of our attacks, and offers insights into potential counterplays. Code will be publicly available at https://github.com/michaeltian108/ViPro.
D3: Training-Free AI-Generated Video Detection Using Second-Order Features
Aug 01, 2025The evolution of video generation techniques, such as Sora, has made it increasingly easy to produce high-fidelity AI-generated videos, raising public concern over the dissemination of synthetic content. However, existing detection methodologies remain limited by their insufficient exploration of temporal artifacts in synthetic videos. To bridge this gap, we establish a theoretical framework through second-order dynamical analysis under Newtonian mechanics, subsequently extending the Second-order Central Difference features tailored for temporal artifact detection. Building on this theoretical foundation, we reveal a fundamental divergence in second-order feature distributions between real and AI-generated videos. Concretely, we propose Detection by Difference of Differences (D3), a novel training-free detection method that leverages the above second-order temporal discrepancies. We validate the superiority of our D3 on 4 open-source datasets (Gen-Video, VideoPhy, EvalCrafter, VidProM), 40 subsets in total. For example, on GenVideo, D3 outperforms the previous best method by 10.39% (absolute) mean Average Precision. Additional experiments on time cost and post-processing operations demonstrate D3's exceptional computational efficiency and strong robust performance. Our code is available at https://github.com/Zig-HS/D3.
Revisiting Adversarial Patch Defenses on Object Detectors: Unified Evaluation, Large-Scale Dataset, and New Insights
Aug 01, 2025

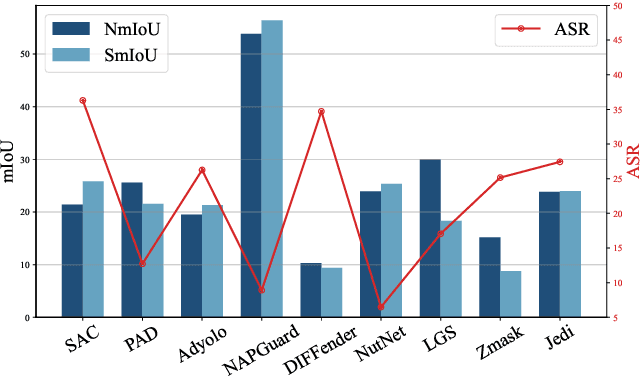
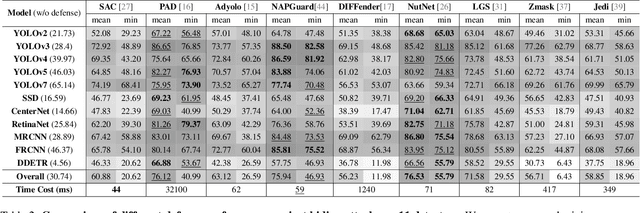
Developing reliable defenses against patch attacks on object detectors has attracted increasing interest. However, we identify that existing defense evaluations lack a unified and comprehensive framework, resulting in inconsistent and incomplete assessments of current methods. To address this issue, we revisit 11 representative defenses and present the first patch defense benchmark, involving 2 attack goals, 13 patch attacks, 11 object detectors, and 4 diverse metrics. This leads to the large-scale adversarial patch dataset with 94 types of patches and 94,000 images. Our comprehensive analyses reveal new insights: (1) The difficulty in defending against naturalistic patches lies in the data distribution, rather than the commonly believed high frequencies. Our new dataset with diverse patch distributions can be used to improve existing defenses by 15.09% AP@0.5. (2) The average precision of the attacked object, rather than the commonly pursued patch detection accuracy, shows high consistency with defense performance. (3) Adaptive attacks can substantially bypass existing defenses, and defenses with complex/stochastic models or universal patch properties are relatively robust. We hope that our analyses will serve as guidance on properly evaluating patch attacks/defenses and advancing their design. Code and dataset are available at https://github.com/Gandolfczjh/APDE, where we will keep integrating new attacks/defenses.
Concept Unlearning by Modeling Key Steps of Diffusion Process
Jul 09, 2025Text-to-image diffusion models (T2I DMs), represented by Stable Diffusion, which generate highly realistic images based on textual input, have been widely used. However, their misuse poses serious security risks. While existing concept unlearning methods aim to mitigate these risks, they struggle to balance unlearning effectiveness with generative retainability.To overcome this limitation, we innovatively propose the Key Step Concept Unlearning (KSCU) method, which ingeniously capitalizes on the unique stepwise sampling characteristic inherent in diffusion models during the image generation process. Unlike conventional approaches that treat all denoising steps equally, KSCU strategically focuses on pivotal steps with the most influence over the final outcome by dividing key steps for different concept unlearning tasks and fine-tuning the model only at those steps. This targeted approach reduces the number of parameter updates needed for effective unlearning, while maximizing the retention of the model's generative capabilities.Through extensive benchmark experiments, we demonstrate that KSCU effectively prevents T2I DMs from generating undesirable images while better retaining the model's generative capabilities.Our code will be released.
Adversarially Robust AI-Generated Image Detection for Free: An Information Theoretic Perspective
May 28, 2025Rapid advances in Artificial Intelligence Generated Images (AIGI) have facilitated malicious use, such as forgery and misinformation. Therefore, numerous methods have been proposed to detect fake images. Although such detectors have been proven to be universally vulnerable to adversarial attacks, defenses in this field are scarce. In this paper, we first identify that adversarial training (AT), widely regarded as the most effective defense, suffers from performance collapse in AIGI detection. Through an information-theoretic lens, we further attribute the cause of collapse to feature entanglement, which disrupts the preservation of feature-label mutual information. Instead, standard detectors show clear feature separation. Motivated by this difference, we propose Training-free Robust Detection via Information-theoretic Measures (TRIM), the first training-free adversarial defense for AIGI detection. TRIM builds on standard detectors and quantifies feature shifts using prediction entropy and KL divergence. Extensive experiments across multiple datasets and attacks validate the superiority of our TRIM, e.g., outperforming the state-of-the-art defense by 33.88% (28.91%) on ProGAN (GenImage), while well maintaining original accuracy.
Seeing It or Not? Interpretable Vision-aware Latent Steering to Mitigate Object Hallucinations
May 23, 2025Large Vision-Language Models (LVLMs) have achieved remarkable success but continue to struggle with object hallucination (OH), generating outputs inconsistent with visual inputs. While previous work has proposed methods to reduce OH, the visual decision-making mechanisms that lead to hallucinations remain poorly understood. In this paper, we propose VaLSe, a Vision-aware Latent Steering framework that adopts an interpretation-then-mitigation strategy to address OH in LVLMs. By tackling dual challenges of modeling complex vision-language interactions and eliminating spurious activation artifacts, VaLSe can generate visual contribution maps that trace how specific visual inputs influence individual output tokens. These maps reveal the model's vision-aware focus regions, which are then used to perform latent space steering, realigning internal representations toward semantically relevant content and reducing hallucinated outputs. Extensive experiments demonstrate that VaLSe is a powerful interpretability tool and an effective method for enhancing model robustness against OH across multiple benchmarks. Furthermore, our analysis uncovers limitations in existing OH evaluation metrics, underscoring the need for more nuanced, interpretable, and visually grounded OH benchmarks in future work. Code is available at: https://github.com/Ziwei-Zheng/VaLSe.
Use as Many Surrogates as You Want: Selective Ensemble Attack to Unleash Transferability without Sacrificing Resource Efficiency
May 19, 2025In surrogate ensemble attacks, using more surrogate models yields higher transferability but lower resource efficiency. This practical trade-off between transferability and efficiency has largely limited existing attacks despite many pre-trained models are easily accessible online. In this paper, we argue that such a trade-off is caused by an unnecessary common assumption, i.e., all models should be identical across iterations. By lifting this assumption, we can use as many surrogates as we want to unleash transferability without sacrificing efficiency. Concretely, we propose Selective Ensemble Attack (SEA), which dynamically selects diverse models (from easily accessible pre-trained models) across iterations based on our new interpretation of decoupling within-iteration and cross-iteration model diversity.In this way, the number of within-iteration models is fixed for maintaining efficiency, while only cross-iteration model diversity is increased for higher transferability. Experiments on ImageNet demonstrate the superiority of SEA in various scenarios. For example, when dynamically selecting 4 from 20 accessible models, SEA yields 8.5% higher transferability than existing attacks under the same efficiency. The superiority of SEA also generalizes to real-world systems, such as commercial vision APIs and large vision-language models. Overall, SEA opens up the possibility of adaptively balancing transferability and efficiency according to specific resource requirements.
Improving Adversarial Transferability on Vision Transformers via Forward Propagation Refinement
Mar 19, 2025Vision Transformers (ViTs) have been widely applied in various computer vision and vision-language tasks. To gain insights into their robustness in practical scenarios, transferable adversarial examples on ViTs have been extensively studied. A typical approach to improving adversarial transferability is by refining the surrogate model. However, existing work on ViTs has restricted their surrogate refinement to backward propagation. In this work, we instead focus on Forward Propagation Refinement (FPR) and specifically refine two key modules of ViTs: attention maps and token embeddings. For attention maps, we propose Attention Map Diversification (AMD), which diversifies certain attention maps and also implicitly imposes beneficial gradient vanishing during backward propagation. For token embeddings, we propose Momentum Token Embedding (MTE), which accumulates historical token embeddings to stabilize the forward updates in both the Attention and MLP blocks. We conduct extensive experiments with adversarial examples transferred from ViTs to various CNNs and ViTs, demonstrating that our FPR outperforms the current best (backward) surrogate refinement by up to 7.0\% on average. We also validate its superiority against popular defenses and its compatibility with other transfer methods. Codes and appendix are available at https://github.com/RYC-98/FPR.