 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP is Strong Enough to Fight Back: Test-time Counterattacks towards Zero-shot Adversarial Robustness of CLIP
Mar 05, 2025



Despite its prevalent use in image-text matching tasks in a zero-shot manner, CLIP has been shown to be highly vulnerable to adversarial perturbations added onto images. Recent studies propose to finetune the vision encoder of CLIP with adversarial samples generated on the fly, and show improved robustness against adversarial attacks on a spectrum of downstream datasets, a property termed as zero-shot robustness. In this paper, we show that malicious perturbations that seek to maximise the classification loss lead to `falsely stable' images, and propose to leverage the pre-trained vision encoder of CLIP to counterattack such adversarial images during inference to achieve robustness. Our paradigm is simple and training-free, providing the first method to defend CLIP from adversarial attacks at test time, which is orthogonal to existing methods aiming to boost zero-shot adversarial robustness of CLIP. We conduct experiments across 16 classification datasets, and demonstrate stable and consistent gains compared to test-time defence methods adapted from existing adversarial robustness studies that do not rely on external networks, without noticeably impairing performance on clean images. We also show that our paradigm can be employed on CLIP models that have been adversarially finetuned to further enhance their robustness at test time. Our code is available \href{https://github.com/Sxing2/CLIP-Test-time-Counterattacks}{here}.
SpectralCLIP: Preventing Artifacts in Text-Guided Style Transfer from a Spectral Perspective
Mar 16, 2023Contrastive Language-Image Pre-Training (CLIP) has refreshed the state of the art for a broad range of vision-language cross-modal tasks. Particularly, it has created an intriguing research line of text-guided image style transfer, dispensing with the need for style reference images as in traditional style transfer methods. However, directly using CLIP to guide the transfer of style leads to undesirable artifacts (mainly written words and unrelated visual entities) spread over the image, partly due to the entanglement of visual and written concepts inherent in CLIP. Inspired by the use of spectral analysis in filtering linguistic information at different granular levels, we analyse the patch embeddings from the last layer of the CLIP vision encoder from the perspective of spectral analysis and find that the presence of undesirable artifacts is highly correlated to some certain frequency components. We propose SpectralCLIP, which implements a spectral filtering layer on top of the CLIP vision encoder, to alleviate the artifact issue. Experimental results show that SpectralCLIP prevents the generation of artifacts effectively in quantitative and qualitative terms, without impairing the stylisation quality. We further apply SpectralCLIP to text-conditioned image generation and show that it prevents written words in the generated images. Code is available at https://github.com/zipengxuc/SpectralCLIP.
Analyzing Unaligned Multimodal Sequence via Graph Convolution and Graph Pooling Fusion
Dec 02, 2020

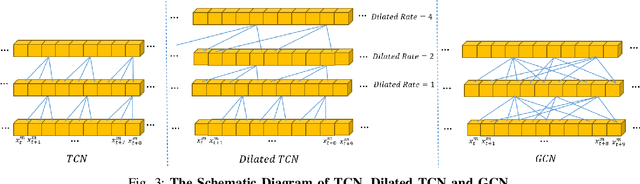
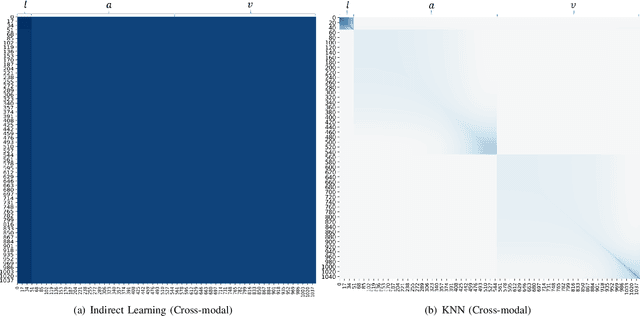
In this paper, we study the task of multimodal sequence analysis which aims to draw inferences from visual, language and acoustic sequences. A majority of existing works generally focus on aligned fusion, mostly at word level, of the three modalities to accomplish this task, which is impractical in real-world scenarios. To overcome this issue, we seek to address the task of multimodal sequence analysis on unaligned modality sequences which is still relatively underexplored and also more challenging. Recurrent neural network (RNN) and its variants are widely used in multimodal sequence analysis, but they are susceptible to the issues of gradient vanishing/explosion and high time complexity due to its recurrent nature. Therefore, we propose a novel model, termed Multimodal Graph, to investigate the effectiveness of graph neural networks (GNN) on modeling multimodal sequential data. The graph-based structure enables parallel computation in time dimension and can learn longer temporal dependency in long unaligned sequences. Specifically, our Multimodal Graph is hierarchically structured to cater to two stages, i.e., intra- and inter-modal dynamics learning. For the first stage, a graph convolutional network is employed for each modality to learn intra-modal dynamics. In the second stage, given that the multimodal sequences are unaligned, the commonly considered word-level fusion does not pertain. To this end, we devise a graph pooling fusion network to automatically learn the associations between various nodes from different modalities. Additionally, we define multiple ways to construct the adjacency matrix for sequential data. Experimental results suggest that our graph-based model reaches state-of-the-art performance on two benchmark datasets.
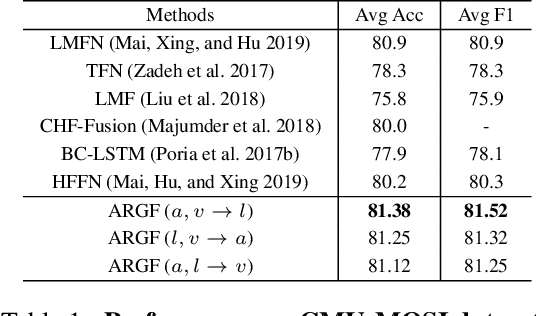
Modality to Modality Translation: An Adversarial Representation Learning and Graph Fusion Network for Multimodal Fusion
Dec 12, 2019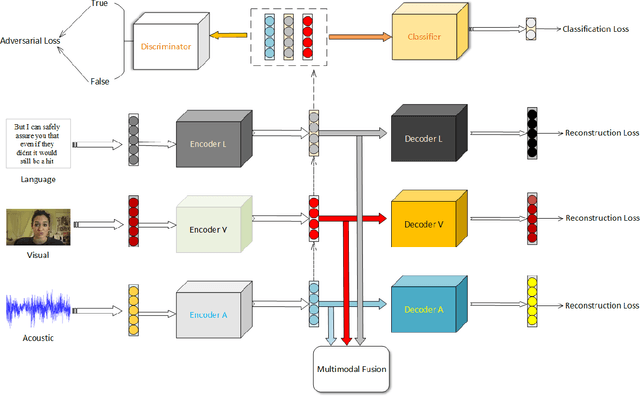
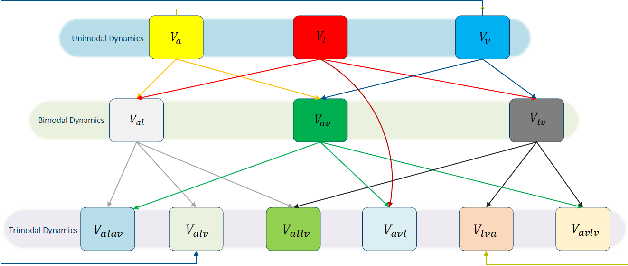
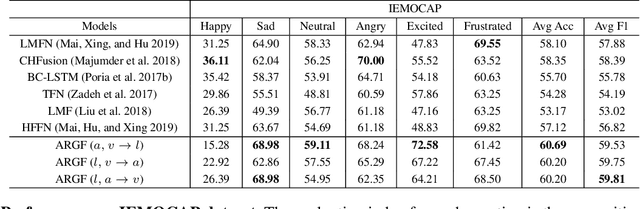
Learning joint embedding space for various modalities is of vital importance for multimodal fusion. Mainstream modality fusion approaches fail to achieve this goal, leaving a modality gap which heavily affects cross-modal fusion. In this paper, we propose a novel adversarial encoder-decoder-classifier framework to learn a modality-invariant embedding space. Since the distributions of various modalities vary in nature, to reduce the modality gap, we translate the distributions of source modalities into that of target modality via their respective encoders using adversarial training. Furthermore, we exert additional constraints on embedding space by introducing reconstruction loss and classification loss. Then we fuse the encoded representations using hierarchical graph neural network which explicitly explores unimodal, bimodal and trimodal interactions in multi-stage. Our method achieves state-of-the-art performance on multiple datasets. Visualization of the learned embeddings suggests that the joint embedding space learned by our method is discriminative.