 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Invariant Modality Representation for Robust Multimodal Learning from a Causal Inference Perspective
Apr 20, 2026Multimodal affective computing aims to predict humans' sentiment, emotion, intention, and opinion using language, acoustic, and visual modalities. However, current models often learn spurious correlations that harm generalization under distribution shifts or noisy modalities. To address this, we propose a causal modality-invariant representation (CmIR) learning framework for robust multimodal learning. At its core, we introduce a theoretically grounded disentanglement method that separates each modality into `causal invariant representation' and `environment-specific spurious representation' from a causal inference perspective. CmIR ensures that the learned invariant representations retain stable predictive relationships with labels across different environments while preserving sufficient information from the raw inputs via invariance constraint, mutual information constraint, and reconstruction constraint. Experiments across multiple multimodal benchmarks demonstrate that CmIR achieves state-of-the-art performance. CmIR particularly excels on out-of-distribution data and noisy data, confirming its robustness and generalizability.
Addressing Missing and Noisy Modalities in One Solution: Unified Modality-Quality Framework for Low-quality Multimodal Data
Mar 03, 2026Multimodal data encountered in real-world scenarios are typically of low quality, with noisy modalities and missing modalities being typical forms that severely hinder model performance and robustness. However, prior works often handle noisy and missing modalities separately. In contrast, we jointly address missing and noisy modalities to enhance model robustness in low-quality data scenarios. We regard both noisy and missing modalities as a unified low-quality modality problem, and propose a unified modality-quality (UMQ) framework to enhance low-quality representations for multimodal affective computing. Firstly, we train a quality estimator with explicit supervised signals via a rank-guided training strategy that compares the relative quality of different representations by adding a ranking constraint, avoiding training noise caused by inaccurate absolute quality labels. Then, a quality enhancer for each modality is constructed, which uses the sample-specific information provided by other modalities and the modality-specific information provided by the defined modality baseline representation to enhance the quality of unimodal representations. Finally, we propose a quality-aware mixture-of-experts module with particular routing mechanism to enable multiple modality-quality problems to be addressed more specifically. UMQ consistently outperforms state-of-the-art baselines on multiple datasets under the settings of complete, missing, and noisy modalities.
CaReFlow: Cyclic Adaptive Rectified Flow for Multimodal Fusion
Feb 22, 2026Modality gap significantly restricts the effectiveness of multimodal fusion. Previous methods often use techniques such as diffusion models and adversarial learning to reduce the modality gap, but they typically focus on one-to-one alignment without exposing the data points of the source modality to the global distribution information of the target modality. To this end, leveraging the characteristic of rectified flow that can map one distribution to another via a straight trajectory, we extend rectified flow for modality distribution mapping. Specifically, we leverage the `one-to-many mapping' strategy in rectified flow that allows each data point of the source modality to observe the overall target distribution. This also alleviates the issue of insufficient paired data within each sample, enabling a more robust distribution transformation. Moreover, to achieve more accurate distribution mapping and address the ambiguous flow directions in one-to-many mapping, we design `adaptive relaxed alignment', enforcing stricter alignment for modality pairs belonging to the same sample, while applying relaxed mapping for pairs not belonging to the same sample or category. Additionally, to prevent information loss during distribution mapping, we introduce `cyclic rectified flow' to ensure the transferred features can be translated back to the original features, allowing multimodal representations to learn sufficient modality-specific information. After distribution alignment, our approach achieves very competitive results on multiple tasks of multimodal affective computing even with a simple fusion method, and visualizations verify that it can effectively reduce the modality gap.
CyIN: Cyclic Informative Latent Space for Bridging Complete and Incomplete Multimodal Learning
Feb 04, 2026Multimodal machine learning, mimicking the human brain's ability to integrate various modalities has seen rapid growth. Most previous multimodal models are trained on perfectly paired multimodal input to reach optimal performance. In real-world deployments, however, the presence of modality is highly variable and unpredictable, causing the pre-trained models in suffering significant performance drops and fail to remain robust with dynamic missing modalities circumstances. In this paper, we present a novel Cyclic INformative Learning framework (CyIN) to bridge the gap between complete and incomplete multimodal learning. Specifically, we firstly build an informative latent space by adopting token- and label-level Information Bottleneck (IB) cyclically among various modalities. Capturing task-related features with variational approximation, the informative bottleneck latents are purified for more efficient cross-modal interaction and multimodal fusion. Moreover, to supplement the missing information caused by incomplete multimodal input, we propose cross-modal cyclic translation by reconstruct the missing modalities with the remained ones through forward and reverse propagation process. With the help of the extracted and reconstructed informative latents, CyIN succeeds in jointly optimizing complete and incomplete multimodal learning in one unified model. Extensive experiments on 4 multimodal datasets demonstrate the superior performance of our method in both complete and diverse incomplete scenarios.
MissMAC-Bench: Building Solid Benchmark for Missing Modality Issue in Robust Multimodal Affective Computing
Jan 31, 2026As a knowledge discovery task over heterogeneous data sources, current Multimodal Affective Computing (MAC) heavily rely on the completeness of multiple modalities to accurately understand human's affective state. However, in real-world scenarios, the availability of modality data is often dynamic and uncertain, leading to substantial performance fluctuations due to the distribution shifts and semantic deficiencies of the incomplete multimodal inputs. Known as the missing modality issue, this challenge poses a critical barrier to the robustness and practical deployment of MAC models. To systematically quantify this issue, we introduce MissMAC-Bench, a comprehensive benchmark designed to establish fair and unified evaluation standards from the perspective of cross-modal synergy. Two guiding principles are proposed, including no missing prior during training, and one single model capable of handling both complete and incomplete modality scenarios, thereby ensuring better generalization. Moreover, to bridge the gap between academic research and real-world applications, our benchmark integrates evaluation protocols with both fixed and random missing patterns at the dataset and instance levels. Extensive experiments conducted on 3 widely-used language models across 4 datasets validate the effectiveness of diverse MAC approaches in tackling the missing modality issue. Our benchmark provides a solid foundation for advancing robust multimodal affective computing and promotes the development of multimedia data mining.
GRCF: Two-Stage Groupwise Ranking and Calibration Framework for Multimodal Sentiment Analysis
Jan 14, 2026Most Multimodal Sentiment Analysis research has focused on point-wise regression. While straightforward, this approach is sensitive to label noise and neglects whether one sample is more positive than another, resulting in unstable predictions and poor correlation alignment. Pairwise ordinal learning frameworks emerged to address this gap, capturing relative order by learning from comparisons. Yet, they introduce two new trade-offs: First, they assign uniform importance to all comparisons, failing to adaptively focus on hard-to-rank samples. Second, they employ static ranking margins, which fail to reflect the varying semantic distances between sentiment groups. To address this, we propose a Two-Stage Group-wise Ranking and Calibration Framework (GRCF) that adapts the philosophy of Group Relative Policy Optimization (GRPO). Our framework resolves these trade-offs by simultaneously preserving relative ordinal structure, ensuring absolute score calibration, and adaptively focusing on difficult samples. Specifically, Stage 1 introduces a GRPO-inspired Advantage-Weighted Dynamic Margin Ranking Loss to build a fine-grained ordinal structure. Stage 2 then employs an MAE-driven objective to align prediction magnitudes. To validate its generalizability, we extend GRCF to classification tasks, including multimodal humor detection and sarcasm detection. GRCF achieves state-of-the-art performance on core regression benchmarks, while also showing strong generalizability in classification tasks.
DaQ-MSA: Denoising and Qualifying Diffusion Augmentations for Multimodal Sentiment Analysis
Jan 11, 2026Multimodal large language models (MLLMs) have demonstrated strong performance on vision-language tasks, yet their effectiveness on multimodal sentiment analysis remains constrained by the scarcity of high-quality training data, which limits accurate multimodal understanding and generalization. To alleviate this bottleneck, we leverage diffusion models to perform semantics-preserving augmentation on the video and audio modalities, expanding the multimodal training distribution. However, increasing data quantity alone is insufficient, as diffusion-generated samples exhibit substantial quality variation and noisy augmentations may degrade performance. We therefore propose DaQ-MSA (Denoising and Qualifying Diffusion Augmentations for Multimodal Sentiment Analysis), which introduces a quality scoring module to evaluate the reliability of augmented samples and assign adaptive training weights. By down-weighting low-quality samples and emphasizing high-fidelity ones, DaQ-MSA enables more stable learning. By integrating the generative capability of diffusion models with the semantic understanding of MLLMs, our approach provides a robust and generalizable automated augmentation strategy for training MLLMs without any human annotation or additional supervision.
Beyond Cosine Similarity Magnitude-Aware CLIP for No-Reference Image Quality Assessment
Nov 13, 2025Recent efforts have repurposed the Contrastive Language-Image Pre-training (CLIP) model for No-Reference Image Quality Assessment (NR-IQA) by measuring the cosine similarity between the image embedding and textual prompts such as "a good photo" or "a bad photo." However, this semantic similarity overlooks a critical yet underexplored cue: the magnitude of the CLIP image features, which we empirically find to exhibit a strong correlation with perceptual quality. In this work, we introduce a novel adaptive fusion framework that complements cosine similarity with a magnitude-aware quality cue. Specifically, we first extract the absolute CLIP image features and apply a Box-Cox transformation to statistically normalize the feature distribution and mitigate semantic sensitivity. The resulting scalar summary serves as a semantically-normalized auxiliary cue that complements cosine-based prompt matching. To integrate both cues effectively, we further design a confidence-guided fusion scheme that adaptively weighs each term according to its relative strength. Extensive experiments on multiple benchmark IQA datasets demonstrate that our method consistently outperforms standard CLIP-based IQA and state-of-the-art baselines, without any task-specific training.
Disentangling Bias by Modeling Intra- and Inter-modal Causal Attention for Multimodal Sentiment Analysis
Aug 07, 2025
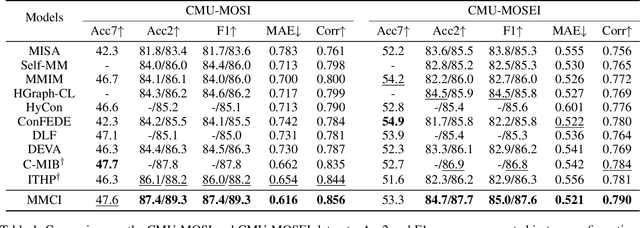
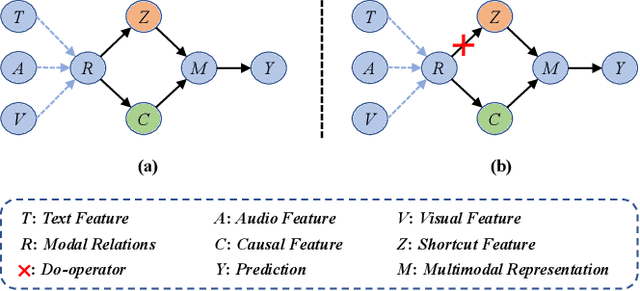
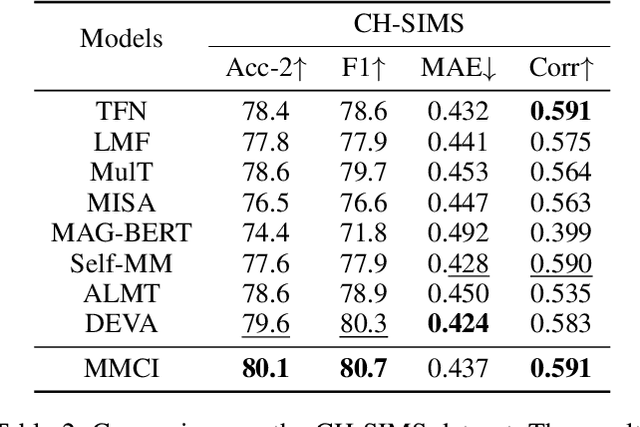
Multimodal sentiment analysis (MSA) aims to understand human emotions by integrating information from multiple modalities, such as text, audio, and visual data. However, existing methods often suffer from spurious correlations both within and across modalities, leading models to rely on statistical shortcuts rather than true causal relationships, thereby undermining generalization. To mitigate this issue, we propose a Multi-relational Multimodal Causal Intervention (MMCI) model, which leverages the backdoor adjustment from causal theory to address the confounding effects of such shortcuts. Specifically, we first model the multimodal inputs as a multi-relational graph to explicitly capture intra- and inter-modal dependencies. Then, we apply an attention mechanism to separately estimate and disentangle the causal features and shortcut features corresponding to these intra- and inter-modal relations. Finally, by applying the backdoor adjustment, we stratify the shortcut features and dynamically combine them with the causal features to encourage MMCI to produce stable predictions under distribution shifts. Extensive experiments on several standard MSA datasets and out-of-distribution (OOD) test sets demonstrate that our method effectively suppresses biases and improves performance.
Towards Explainable Fusion and Balanced Learning in Multimodal Sentiment Analysis
Apr 16, 2025Multimodal Sentiment Analysis (MSA) faces two critical challenges: the lack of interpretability in the decision logic of multimodal fusion and modality imbalance caused by disparities in inter-modal information density. To address these issues, we propose KAN-MCP, a novel framework that integrates the interpretability of Kolmogorov-Arnold Networks (KAN) with the robustness of the Multimodal Clean Pareto (MCPareto) framework. First, KAN leverages its univariate function decomposition to achieve transparent analysis of cross-modal interactions. This structural design allows direct inspection of feature transformations without relying on external interpretation tools, thereby ensuring both high expressiveness and interpretability. Second, the proposed MCPareto enhances robustness by addressing modality imbalance and noise interference. Specifically, we introduce the Dimensionality Reduction and Denoising Modal Information Bottleneck (DRD-MIB) method, which jointly denoises and reduces feature dimensionality. This approach provides KAN with discriminative low-dimensional inputs to reduce the modeling complexity of KAN while preserving critical sentiment-related information. Furthermore, MCPareto dynamically balances gradient contributions across modalities using the purified features output by DRD-MIB, ensuring lossless transmission of auxiliary signals and effectively alleviating modality imbalance. This synergy of interpretability and robustness not only achieves superior performance on benchmark datasets such as CMU-MOSI, CMU-MOSEI, and CH-SIMS v2 but also offers an intuitive visualization interface through KAN's interpretable architecture.