 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Learning Meets Weakly Supervised Modality Correlation Learning
Dec 15, 2022



In the field of multimodal sentiment analysis (MSA), a few studies have leveraged the inherent modality correlation information stored in samples for self-supervised learning. However, they feed the training pairs in a random order without consideration of difficulty. Without human annotation, the generated training pairs of self-supervised learning often contain noise. If noisy or hard pairs are used for training at the easy stage, the model might be stuck in bad local optimum. In this paper, we inject curriculum learning into weakly supervised modality correlation learning. The weakly supervised correlation learning leverages the label information to generate scores for negative pairs to learn a more discriminative embedding space, where negative pairs are defined as two unimodal embeddings from different samples. To assist the correlation learning, we feed the training pairs to the model according to difficulty by the proposed curriculum learning, which consists of elaborately designed scoring and feeding functions. The scoring function computes the difficulty of pairs using pre-trained and current correlation predictors, where the pairs with large losses are defined as hard pairs. Notably, the hardest pairs are discarded in our algorithm, which are assumed as noisy pairs. Moreover, the feeding function takes the difference of correlation losses as feedback to determine the feeding actions (`stay', `step back', or `step forward'). The proposed method reaches state-of-the-art performance on MSA.
Subgraph-aware Few-Shot Inductive Link Prediction via Meta-Learning
Jul 26, 2021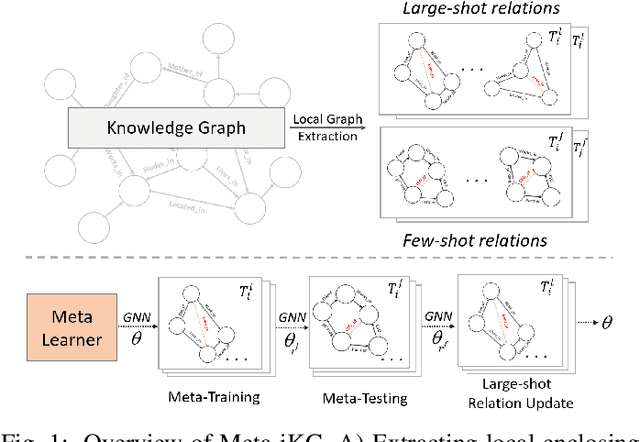



Link prediction for knowledge graphs aims to predict missing connections between entities. Prevailing methods are limited to a transductive setting and hard to process unseen entities. The recent proposed subgraph-based models provided alternatives to predict links from the subgraph structure surrounding a candidate triplet. However, these methods require abundant known facts of training triplets and perform poorly on relationships that only have a few triplets. In this paper, we propose Meta-iKG, a novel subgraph-based meta-learner for few-shot inductive relation reasoning. Meta-iKG utilizes local subgraphs to transfer subgraph-specific information and learn transferable patterns faster via meta gradients. In this way, we find the model can quickly adapt to few-shot relationships using only a handful of known facts with inductive settings. Moreover, we introduce a large-shot relation update procedure to traditional meta-learning to ensure that our model can generalize well both on few-shot and large-shot relations. We evaluate Meta-iKG on inductive benchmarks sampled from NELL and Freebase, and the results show that Meta-iKG outperforms the current state-of-the-art methods both in few-shot scenarios and standard inductive settings.
Part-based Multi-stream Model for Vehicle Searching
Nov 11, 2019
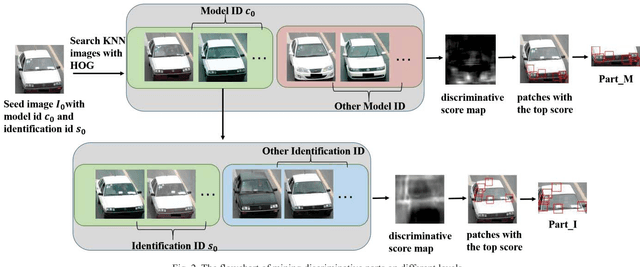
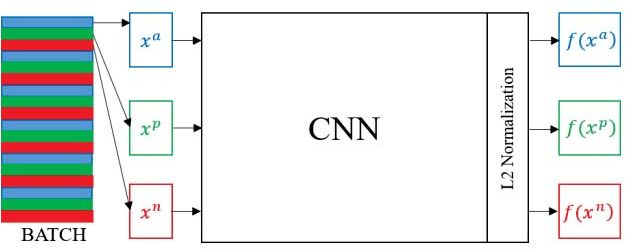
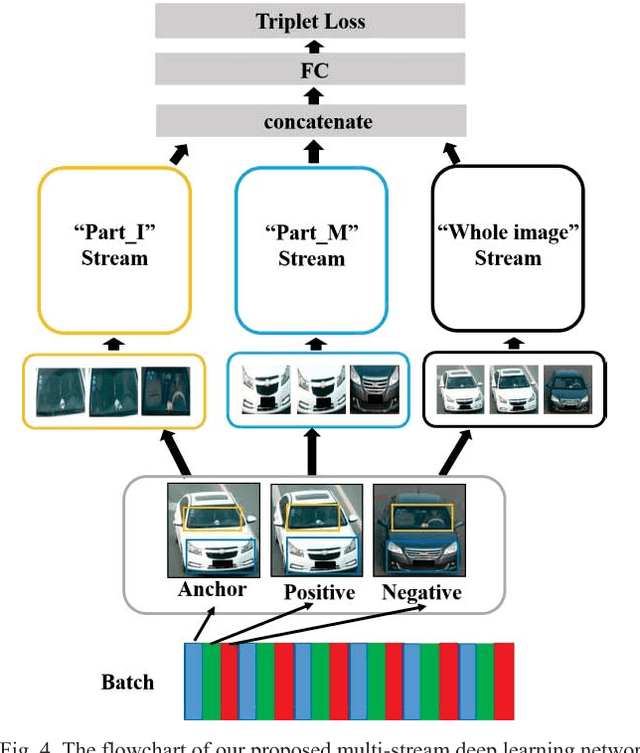
Due to the enormous requirement in public security and intelligent transportation system, searching an identical vehicle has become more and more important. Current studies usually treat vehicle as an integral object and then train a distance metric to measure the similarity among vehicles. However, these raw images may be exactly similar to ones with different identification and include some pixels in background that may disturb the distance metric learning. In this paper, we propose a novel and useful method to segment an original vehicle image into several discriminative foreground parts, and these parts consist of some fine grained regions that are named discriminative patches. After that, these parts combined with the raw image are fed into the proposed deep learning network. We can easily measure the similarity of two vehicle images by computing the Euclidean distance of the features from FC layer. Two main contributions of this paper are as follows. Firstly, a method is proposed to estimate if a patch in a raw vehicle image is discriminative or not. Secondly, a new Part-based Multi-Stream Model (PMSM) is designed and optimized for vehicle retrieval and re-identification tasks. We evaluate the proposed method on the VehicleID dataset, and the experimental results show that our method can outperform the baseline.