 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyIN: Cyclic Informative Latent Space for Bridging Complete and Incomplete Multimodal Learning
Feb 04, 2026Multimodal machine learning, mimicking the human brain's ability to integrate various modalities has seen rapid growth. Most previous multimodal models are trained on perfectly paired multimodal input to reach optimal performance. In real-world deployments, however, the presence of modality is highly variable and unpredictable, causing the pre-trained models in suffering significant performance drops and fail to remain robust with dynamic missing modalities circumstances. In this paper, we present a novel Cyclic INformative Learning framework (CyIN) to bridge the gap between complete and incomplete multimodal learning. Specifically, we firstly build an informative latent space by adopting token- and label-level Information Bottleneck (IB) cyclically among various modalities. Capturing task-related features with variational approximation, the informative bottleneck latents are purified for more efficient cross-modal interaction and multimodal fusion. Moreover, to supplement the missing information caused by incomplete multimodal input, we propose cross-modal cyclic translation by reconstruct the missing modalities with the remained ones through forward and reverse propagation process. With the help of the extracted and reconstructed informative latents, CyIN succeeds in jointly optimizing complete and incomplete multimodal learning in one unified model. Extensive experiments on 4 multimodal datasets demonstrate the superior performance of our method in both complete and diverse incomplete scenarios.
MissMAC-Bench: Building Solid Benchmark for Missing Modality Issue in Robust Multimodal Affective Computing
Jan 31, 2026As a knowledge discovery task over heterogeneous data sources, current Multimodal Affective Computing (MAC) heavily rely on the completeness of multiple modalities to accurately understand human's affective state. However, in real-world scenarios, the availability of modality data is often dynamic and uncertain, leading to substantial performance fluctuations due to the distribution shifts and semantic deficiencies of the incomplete multimodal inputs. Known as the missing modality issue, this challenge poses a critical barrier to the robustness and practical deployment of MAC models. To systematically quantify this issue, we introduce MissMAC-Bench, a comprehensive benchmark designed to establish fair and unified evaluation standards from the perspective of cross-modal synergy. Two guiding principles are proposed, including no missing prior during training, and one single model capable of handling both complete and incomplete modality scenarios, thereby ensuring better generalization. Moreover, to bridge the gap between academic research and real-world applications, our benchmark integrates evaluation protocols with both fixed and random missing patterns at the dataset and instance levels. Extensive experiments conducted on 3 widely-used language models across 4 datasets validate the effectiveness of diverse MAC approaches in tackling the missing modality issue. Our benchmark provides a solid foundation for advancing robust multimodal affective computing and promotes the development of multimedia data mining.
End-to-end Semantic-centric Video-based Multimodal Affective Computing
Aug 14, 2024In the pathway toward Artificial General Intelligence (AGI), understanding human's affection is essential to enhance machine's cognition abilities. For achieving more sensual human-AI interaction, Multimodal Affective Computing (MAC) in human-spoken videos has attracted increasing attention. However, previous methods are mainly devoted to designing multimodal fusion algorithms, suffering from two issues: semantic imbalance caused by diverse pre-processing operations and semantic mismatch raised by inconsistent affection content contained in different modalities comparing with the multimodal ground truth. Besides, the usage of manual features extractors make they fail in building end-to-end pipeline for multiple MAC downstream tasks. To address above challenges, we propose a novel end-to-end framework named SemanticMAC to compute multimodal semantic-centric affection for human-spoken videos. We firstly employ pre-trained Transformer model in multimodal data pre-processing and design Affective Perceiver module to capture unimodal affective information. Moreover, we present a semantic-centric approach to unify multimodal representation learning in three ways, including gated feature interaction, multi-task pseudo label generation, and intra-/inter-sample contrastive learning. Finally, SemanticMAC effectively learn specific- and shared-semantic representations in the guidance of semantic-centric labels. Extensive experimental results demonstrate that our approach surpass the state-of-the-art methods on 7 public datasets in four MAC downstream tasks.
Sparse array design for MIMO radar in multipath scenarios
Jan 16, 2024



Sparse array designs have focused mostly on angular resolution, peak sidelobe level and directivity factor of virtual arrays for multiple-input multiple-output (MIMO) radar. The notion of the MIMO radar virtual array is based on the direct path assumption in that the direction-of-departure (DOD) and direction-of-arrival (DOA) of the targets are equal. However, the DOD and DOA of targets in multipath scenarios are likely to be very different. The identification of multipath targets requires DOD-DOA imaging using the the transmit and receive arrays, not the virtual array. To improve the imaging of both direct path and multipath targets, we introduce several new criteria for MIMO radar sparse linear array (SLA) designs for multipath scenarios. Under the new criteria, we adopt a cyclic optimization strategy under a coordinate descent framework to design the MIMO SLAs. We present several numerical examples to demonstrate the effectiveness of the proposed approaches.
Mixed-ADC Based PMCW MIMO Radar Angle-Doppler Imaging
Jun 15, 2023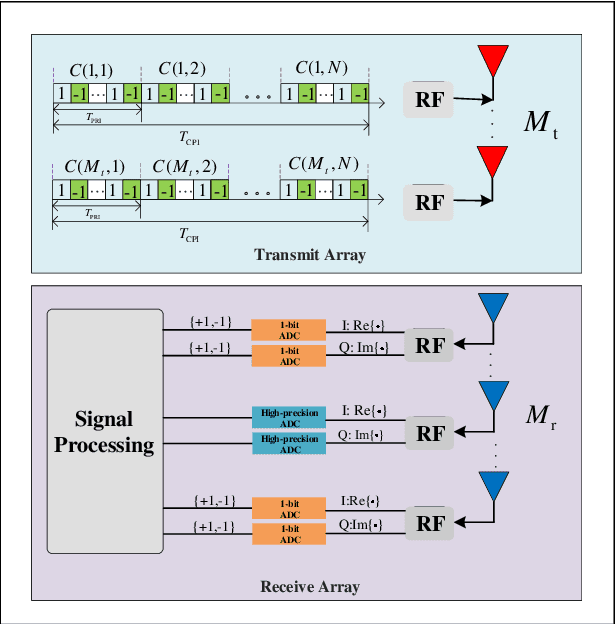
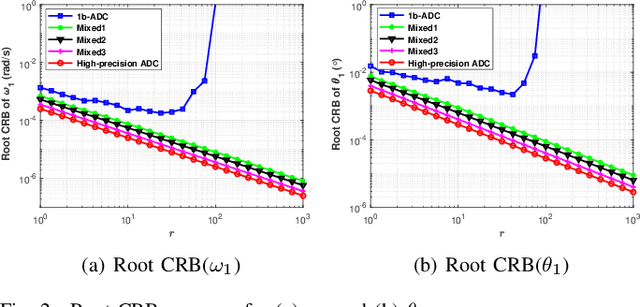
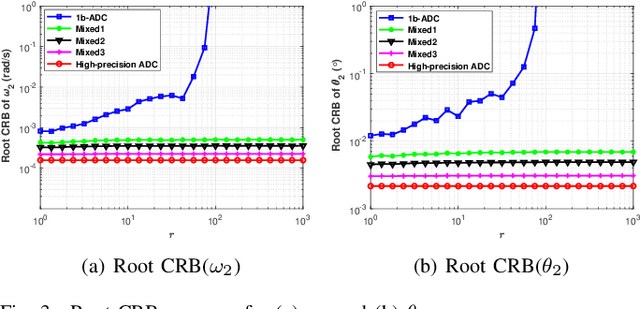
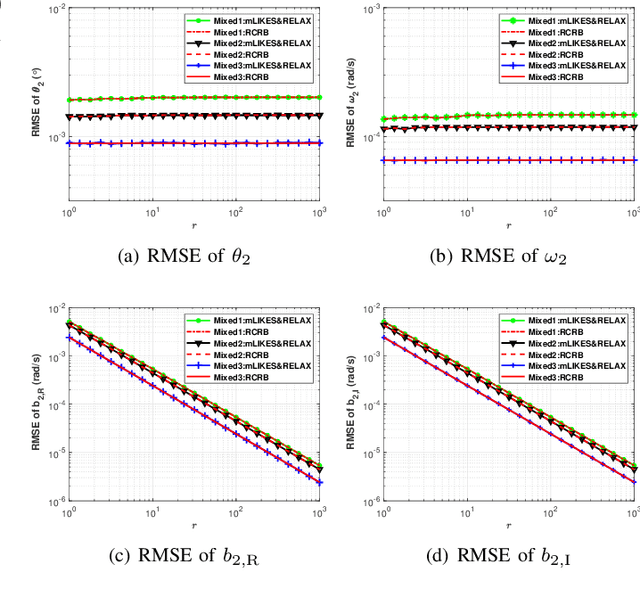
Phase-modulated continuous-wave (PMCW) multiple-input multiple-output (MIMO) radar systems are known to possess excellent mutual interference mitigation capabilities, but require costly and power-hungry high sampling rate and high-precision analog-to-digital converters (ADC's). To reduce cost and power consumption, we consider a mixed-ADC architecture, in which most receive antenna outputs are sampled by one-bit ADC's, and only one or a few outputs by high-precision ADC's. We first derive the Cram{\'e}r-Rao bound (CRB) for the mixed-ADC based PMCW MIMO radar to characterize the best achievable performance of an unbiased target parameter estimator. The CRB analysis demonstrates that the mixed-ADC architecture with a relatively small number of high-precision ADC's and a large number of one-bit ADC's allows us to drastically reduce the hardware cost and power consumption while still maintain a high dynamic range needed for autonomous driving applications. We also introduce a two-step estimator to realize the computationally efficient maximum likelihood (ML) estimation of the target parameters. We formulate the angle-Doppler imaging problem as a sparse parameter estimation problem, and a computationally efficient majorization-minimization (MM) based estimator of sparse parameters, referred to as mLIKES, is devised for accurate angle-Doppler imaging. This is followed by using a relaxation-based approach to cyclically refine the results of mLIKES for accurate off-grid target parameter estimation. Numerical examples are provided to demonstrate the effectiveness of the proposed algorithms for angle-Doppler imaging using mixed-ADC based PMCW MIMO radar.
Multimodal Contrastive Learning via Uni-Modal Coding and Cross-Modal Prediction for Multimodal Sentiment Analysis
Oct 26, 2022Multimodal representation learning is a challenging task in which previous work mostly focus on either uni-modality pre-training or cross-modality fusion. In fact, we regard modeling multimodal representation as building a skyscraper, where laying stable foundation and designing the main structure are equally essential. The former is like encoding robust uni-modal representation while the later is like integrating interactive information among different modalities, both of which are critical to learning an effective multimodal representation. Recently, contrastive learning has been successfully applied in representation learning, which can be utilized as the pillar of the skyscraper and benefit the model to extract the most important features contained in the multimodal data. In this paper, we propose a novel framework named MultiModal Contrastive Learning (MMCL) for multimodal representation to capture intra- and inter-modality dynamics simultaneously. Specifically, we devise uni-modal contrastive coding with an efficient uni-modal feature augmentation strategy to filter inherent noise contained in acoustic and visual modality and acquire more robust uni-modality representations. Besides, a pseudo siamese network is presented to predict representation across different modalities, which successfully captures cross-modal dynamics. Moreover, we design two contrastive learning tasks, instance- and sentiment-based contrastive learning, to promote the process of prediction and learn more interactive information related to sentiment. Extensive experiments conducted on two public datasets demonstrate that our method surpasses the state-of-the-art methods.