 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Generative Game Engine: Breaking the Resolution Wall via Hardware-Algorithm Co-Design
Jan 31, 2026Real-time generative game engines represent a paradigm shift in interactive simulation, promising to replace traditional graphics pipelines with neural world models. However, existing approaches are fundamentally constrained by the ``Memory Wall,'' restricting practical deployments to low resolutions (e.g., $64 \times 64$). This paper bridges the gap between generative models and high-resolution neural simulations by introducing a scalable \textit{Hardware-Algorithm Co-Design} framework. We identify that high-resolution generation suffers from a critical resource mismatch: the World Model is compute-bound while the Decoder is memory-bound. To address this, we propose a heterogeneous architecture that intelligently decouples these components across a cluster of AI accelerators. Our system features three core innovations: (1) an asymmetric resource allocation strategy that optimizes throughput under sequence parallelism constraints; (2) a memory-centric operator fusion scheme that minimizes off-chip bandwidth usage; and (3) a manifold-aware latent extrapolation mechanism that exploits temporal redundancy to mask latency. We validate our approach on a cluster of programmable AI accelerators, enabling real-time generation at $720 \times 480$ resolution -- a $50\times$ increase in pixel throughput over prior baselines. Evaluated on both continuous 3D racing and discrete 2D platformer benchmarks, our system delivers fluid 26.4 FPS and 48.3 FPS respectively, with an amortized effective latency of 2.7 ms. This work demonstrates that resolving the ``Memory Wall'' via architectural co-design is not merely an optimization, but a prerequisite for enabling high-fidelity, responsive neural gameplay.
MathMixup: Boosting LLM Mathematical Reasoning with Difficulty-Controllable Data Synthesis and Curriculum Learning
Jan 14, 2026In mathematical reasoning tasks, the advancement of Large Language Models (LLMs) relies heavily on high-quality training data with clearly defined and well-graded difficulty levels. However, existing data synthesis methods often suffer from limited diversity and lack precise control over problem difficulty, making them insufficient for supporting efficient training paradigms such as curriculum learning. To address these challenges, we propose MathMixup, a novel data synthesis paradigm that systematically generates high-quality, difficulty-controllable mathematical reasoning problems through hybrid and decomposed strategies. Automated self-checking and manual screening are incorporated to ensure semantic clarity and a well-structured difficulty gradient in the synthesized data. Building on this, we construct the MathMixupQA dataset and design a curriculum learning strategy that leverages these graded problems, supporting flexible integration with other datasets. Experimental results show that MathMixup and its curriculum learning strategy significantly enhance the mathematical reasoning performance of LLMs. Fine-tuned Qwen2.5-7B achieves an average score of 52.6\% across seven mathematical benchmarks, surpassing previous state-of-the-art methods. These results fully validate the effectiveness and broad applicability of MathMixup in improving the mathematical reasoning abilities of LLMs and advancing data-centric curriculum learning.
Beyond Accuracy: Evaluating Grounded Visual Evidence in Thinking with Images
Jan 14, 2026Despite the remarkable progress of Vision-Language Models (VLMs) in adopting "Thinking-with-Images" capabilities, accurately evaluating the authenticity of their reasoning process remains a critical challenge. Existing benchmarks mainly rely on outcome-oriented accuracy, lacking the capability to assess whether models can accurately leverage fine-grained visual cues for multi-step reasoning. To address these limitations, we propose ViEBench, a process-verifiable benchmark designed to evaluate faithful visual reasoning. Comprising 200 multi-scenario high-resolution images with expert-annotated visual evidence, ViEBench uniquely categorizes tasks by difficulty into perception and reasoning dimensions, where reasoning tasks require utilizing localized visual details with prior knowledge. To establish comprehensive evaluation criteria, we introduce a dual-axis matrix that provides fine-grained metrics through four diagnostic quadrants, enabling transparent diagnosis of model behavior across varying task complexities. Our experiments yield several interesting observations: (1) VLMs can sometimes produce correct final answers despite grounding on irrelevant regions, and (2) they may successfully locate the correct evidence but still fail to utilize it to reach accurate conclusions. Our findings demonstrate that ViEBench can serve as a more explainable and practical benchmark for comprehensively evaluating the effectiveness agentic VLMs. The codes will be released at: https://github.com/Xuchen-Li/ViEBench.
SciAgent: A Unified Multi-Agent System for Generalistic Scientific Reasoning
Nov 17, 2025Recent advances in large language models have enabled AI systems to achieve expert-level performance on domain-specific scientific tasks, yet these systems remain narrow and handcrafted. We introduce SciAgent, a unified multi-agent system designed for generalistic scientific reasoning-the ability to adapt reasoning strategies across disciplines and difficulty levels. SciAgent organizes problem solving as a hierarchical process: a Coordinator Agent interprets each problem's domain and complexity, dynamically orchestrating specialized Worker Systems, each composed of interacting reasoning Sub-agents for symbolic deduction, conceptual modeling, numerical computation, and verification. These agents collaboratively assemble and refine reasoning pipelines tailored to each task. Across mathematics and physics Olympiads (IMO, IMC, IPhO, CPhO), SciAgent consistently attains or surpasses human gold-medalist performance, demonstrating both domain generality and reasoning adaptability. Additionally, SciAgent has been tested on the International Chemistry Olympiad (IChO) and selected problems from the Humanity's Last Exam (HLE) benchmark, further confirming the system's ability to generalize across diverse scientific domains. This work establishes SciAgent as a concrete step toward generalistic scientific intelligence-AI systems capable of coherent, cross-disciplinary reasoning at expert levels.
MATrack: Efficient Multiscale Adaptive Tracker for Real-Time Nighttime UAV Operations
Oct 24, 2025Nighttime UAV tracking faces significant challenges in real-world robotics operations. Low-light conditions not only limit visual perception capabilities, but cluttered backgrounds and frequent viewpoint changes also cause existing trackers to drift or fail during deployment. To address these difficulties, researchers have proposed solutions based on low-light enhancement and domain adaptation. However, these methods still have notable shortcomings in actual UAV systems: low-light enhancement often introduces visual artifacts, domain adaptation methods are computationally expensive and existing lightweight designs struggle to fully leverage dynamic object information. Based on an in-depth analysis of these key issues, we propose MATrack-a multiscale adaptive system designed specifically for nighttime UAV tracking. MATrack tackles the main technical challenges of nighttime tracking through the collaborative work of three core modules: Multiscale Hierarchy Blende (MHB) enhances feature consistency between static and dynamic templates. Adaptive Key Token Gate accurately identifies object information within complex backgrounds. Nighttime Template Calibrator (NTC) ensures stable tracking performance over long sequences. Extensive experiments show that MATrack achieves a significant performance improvement. On the UAVDark135 benchmark, its precision, normalized precision and AUC surpass state-of-the-art (SOTA) methods by 5.9%, 5.4% and 4.2% respectively, while maintaining a real-time processing speed of 81 FPS. Further tests on a real-world UAV platform validate the system's reliability, demonstrating that MATrack can provide stable and effective nighttime UAV tracking support for critical robotics applications such as nighttime search and rescue and border patrol.
MorphoBench: A Benchmark with Difficulty Adaptive to Model Reasoning
Oct 16, 2025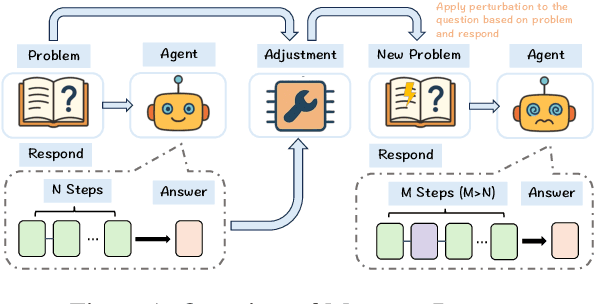

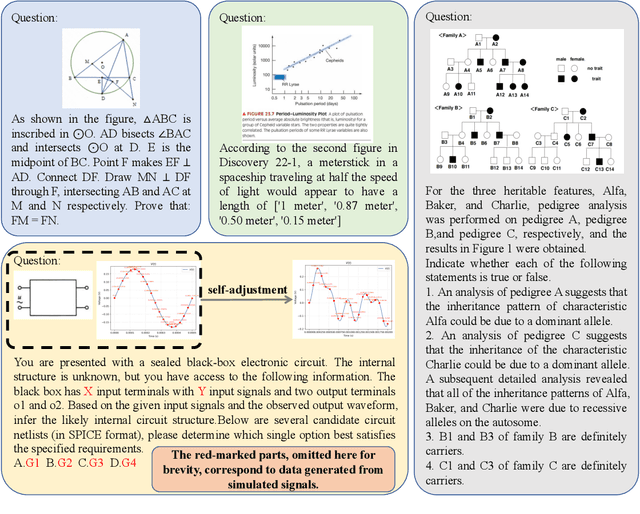
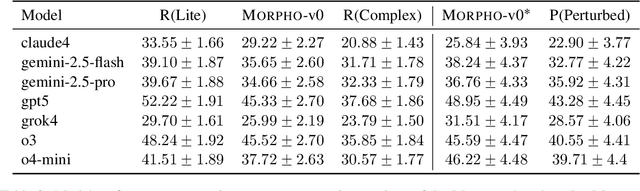
With the advancement of powerful large-scale reasoning models, effectively evaluating the reasoning capabilities of these models has become increasingly important. However, existing benchmarks designed to assess the reasoning abilities of large models tend to be limited in scope and lack the flexibility to adapt their difficulty according to the evolving reasoning capacities of the models. To address this, we propose MorphoBench, a benchmark that incorporates multidisciplinary questions to evaluate the reasoning capabilities of large models and can adjust and update question difficulty based on the reasoning abilities of advanced models. Specifically, we curate the benchmark by selecting and collecting complex reasoning questions from existing benchmarks and sources such as Olympiad-level competitions. Additionally, MorphoBench adaptively modifies the analytical challenge of questions by leveraging key statements generated during the model's reasoning process. Furthermore, it includes questions generated using simulation software, enabling dynamic adjustment of benchmark difficulty with minimal resource consumption. We have gathered over 1,300 test questions and iteratively adjusted the difficulty of MorphoBench based on the reasoning capabilities of models such as o3 and GPT-5. MorphoBench enhances the comprehensiveness and validity of model reasoning evaluation, providing reliable guidance for improving both the reasoning abilities and scientific robustness of large models. The code has been released in https://github.com/OpenDCAI/MorphoBench.
Look Less, Reason More: Rollout-Guided Adaptive Pixel-Space Reasoning
Oct 02, 2025Vision-Language Models (VLMs) excel at many multimodal tasks, yet they frequently struggle with tasks requiring precise understanding and handling of fine-grained visual elements. This is mainly due to information loss during image encoding or insufficient attention to critical regions. Recent work has shown promise by incorporating pixel-level visual information into the reasoning process, enabling VLMs to access high-resolution visual details during their thought process. However, this pixel-level information is often overused, leading to inefficiency and distraction from irrelevant visual details. To address these challenges, we propose the first framework for adaptive pixel reasoning that dynamically determines necessary pixel-level operations based on the input query. Specifically, we first apply operation-aware supervised fine-tuning to establish baseline competence in textual reasoning and visual operations, then design a novel rollout-guided reinforcement learning framework relying on feedback of the model's own responses, which enables the VLM to determine when pixel operations should be invoked based on query difficulty. Experiments on extensive multimodal reasoning benchmarks show that our model achieves superior performance while significantly reducing unnecessary visual operations. Impressively, our model achieves 73.4\% accuracy on HR-Bench 4K while maintaining a tool usage ratio of only 20.1\%, improving accuracy and simultaneously reducing tool usage by 66.5\% compared to the previous methods.
VS-LLM: Visual-Semantic Depression Assessment based on LLM for Drawing Projection Test
Aug 07, 2025The Drawing Projection Test (DPT) is an essential tool in art therapy, allowing psychologists to assess participants' mental states through their sketches. Specifically, through sketches with the theme of "a person picking an apple from a tree (PPAT)", it can be revealed whether the participants are in mental states such as depression. Compared with scales, the DPT can enrich psychologists' understanding of an individual's mental state. However, the interpretation of the PPAT is laborious and depends on the experience of the psychologists. To address this issue, we propose an effective identification method to support psychologists in conducting a large-scale automatic DPT. Unlike traditional sketch recognition, DPT more focus on the overall evaluation of the sketches, such as color usage and space utilization. Moreover, PPAT imposes a time limit and prohibits verbal reminders, resulting in low drawing accuracy and a lack of detailed depiction. To address these challenges, we propose the following efforts: (1) Providing an experimental environment for automated analysis of PPAT sketches for depression assessment; (2) Offering a Visual-Semantic depression assessment based on LLM (VS-LLM) method; (3) Experimental results demonstrate that our method improves by 17.6% compared to the psychologist assessment method. We anticipate that this work will contribute to the research in mental state assessment based on PPAT sketches' elements recognition. Our datasets and codes are available at https://github.com/wmeiqi/VS-LLM.
CausalStep: A Benchmark for Explicit Stepwise Causal Reasoning in Videos
Jul 22, 2025Recent advances in large language models (LLMs) have improved reasoning in text and image domains, yet achieving robust video reasoning remains a significant challenge. Existing video benchmarks mainly assess shallow understanding and reasoning and allow models to exploit global context, failing to rigorously evaluate true causal and stepwise reasoning. We present CausalStep, a benchmark designed for explicit stepwise causal reasoning in videos. CausalStep segments videos into causally linked units and enforces a strict stepwise question-answer (QA) protocol, requiring sequential answers and preventing shortcut solutions. Each question includes carefully constructed distractors based on error type taxonomy to ensure diagnostic value. The benchmark features 100 videos across six categories and 1,852 multiple-choice QA pairs. We introduce seven diagnostic metrics for comprehensive evaluation, enabling precise diagnosis of causal reasoning capabilities. Experiments with leading proprietary and open-source models, as well as human baselines, reveal a significant gap between current models and human-level stepwise reasoning. CausalStep provides a rigorous benchmark to drive progress in robust and interpretable video reasoning.
DARTer: Dynamic Adaptive Representation Tracker for Nighttime UAV Tracking
May 01, 2025Nighttime UAV tracking presents significant challenges due to extreme illumination variations and viewpoint changes, which severely degrade tracking performance. Existing approaches either rely on light enhancers with high computational costs or introduce redundant domain adaptation mechanisms, failing to fully utilize the dynamic features in varying perspectives. To address these issues, we propose \textbf{DARTer} (\textbf{D}ynamic \textbf{A}daptive \textbf{R}epresentation \textbf{T}racker), an end-to-end tracking framework designed for nighttime UAV scenarios. DARTer leverages a Dynamic Feature Blender (DFB) to effectively fuse multi-perspective nighttime features from static and dynamic templates, enhancing representation robustness. Meanwhile, a Dynamic Feature Activator (DFA) adaptively activates Vision Transformer layers based on extracted features, significantly improving efficiency by reducing redundant computations. Our model eliminates the need for complex multi-task loss functions, enabling a streamlined training process. Extensive experiments on multiple nighttime UAV tracking benchmarks demonstrate the superiority of DARTer over state-of-the-art trackers. These results confirm that DARTer effectively balances tracking accuracy and efficiency, making it a promising solution for real-world nighttime UAV tracking applications.