 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEduPersona: Benchmarking Subjective Ability Boundaries of Virtual Student Agents
Oct 06, 2025As large language models are increasingly integrated into education, virtual student agents are becoming vital for classroom simulation and teacher training. Yet their classroom-oriented subjective abilities remain largely unassessed, limiting understanding of model boundaries and hindering trustworthy deployment. We present EduPersona, a large-scale benchmark spanning two languages, three subjects, and ten persona types based on the Big Five theory. The dataset contains 1,308 authentic classroom dialogue rounds, corresponding to 12,814 teacher-student Q&A turns, and is further expanded through persona stylization into roughly 10 times larger scale (128k turns), providing a solid foundation for evaluation. Building on this resource, we decompose hard-to-quantify subjective performance into three progressive tasks: TASK1 basic coherence (whether behavior, emotion, expression, and voice align with classroom context), TASK2 student realism, and TASK3 long-term persona consistency, thereby establishing an evaluation framework grounded in educational theory and research value. We conduct systematic experiments on three representative LLMs, comparing their original versions with ten persona-fine-tuned variants trained on EduPersona. Results show consistent and significant average improvements across all tasks: TASK1 +33.6%, TASK2 +30.6%, and TASK3 +14.9%. These improvements highlight the dataset's effectiveness and research value, while also revealing the heterogeneous difficulty of persona modeling. In summary, EduPersona delivers the first classroom benchmark centered on subjective abilities, establishes a decoupled and verifiable research paradigm, and we will open-source both the dataset and the framework to support the broader research community in advancing trustworthy and human-like AI for education.
Visual Evolutionary Optimization on Combinatorial Problems with Multimodal Large Language Models: A Case Study of Influence Maximization
May 11, 2025Graph-structured combinatorial problems in complex networks are prevalent in many domains, and are computationally demanding due to their complexity and non-linear nature. Traditional evolutionary algorithms (EAs), while robust, often face obstacles due to content-shallow encoding limitations and lack of structural awareness, necessitating hand-crafted modifications for effective application. In this work, we introduce an original framework, Visual Evolutionary Optimization (VEO), leveraging multimodal large language models (MLLMs) as the backbone evolutionary optimizer in this context. Specifically, we propose a context-aware encoding way, representing the solution of the network as an image. In this manner, we can utilize MLLMs' image processing capabilities to intuitively comprehend network configurations, thus enabling machines to solve these problems in a human-like way. We have developed MLLM-based operators tailored for various evolutionary optimization stages, including initialization, crossover, and mutation. Furthermore, we propose that graph sparsification can effectively enhance the applicability and scalability of VEO on large-scale networks, owing to the scale-free nature of real-world networks. We demonstrate the effectiveness of our method using a well-known task in complex networks, influence maximization, and validate it on eight different real-world networks of various structures. The results have confirmed VEO's reliability and enhanced effectiveness compared to traditional evolutionary optimization.
Can Large Language Models Be Trusted as Black-Box Evolutionary Optimizers for Combinatorial Problems?
Jan 25, 2025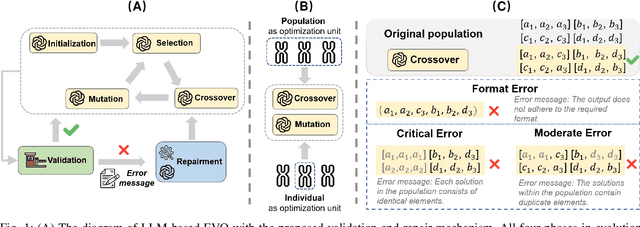
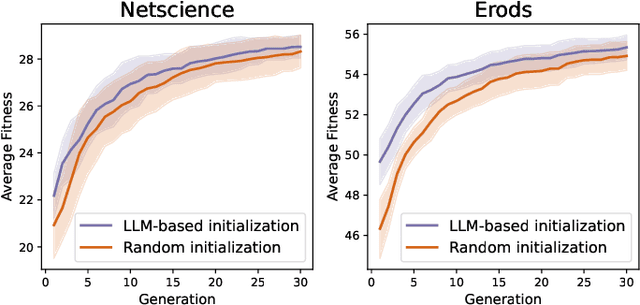


Evolutionary computation excels in complex optimization but demands deep domain knowledge, restricting its accessibility. Large Language Models (LLMs) offer a game-changing solution with their extensive knowledge and could democratize the optimization paradigm. Although LLMs possess significant capabilities, they may not be universally effective, particularly since evolutionary optimization encompasses multiple stages. It is therefore imperative to evaluate the suitability of LLMs as evolutionary optimizer (EVO). Thus, we establish a series of rigid standards to thoroughly examine the fidelity of LLM-based EVO output in different stages of evolutionary optimization and then introduce a robust error-correction mechanism to mitigate the output uncertainty. Furthermore, we explore a cost-efficient method that directly operates on entire populations with excellent effectiveness in contrast to individual-level optimization. Through extensive experiments, we rigorously validate the performance of LLMs as operators targeted for combinatorial problems. Our findings provide critical insights and valuable observations, advancing the understanding and application of LLM-based optimization.
Bridging Visualization and Optimization: Multimodal Large Language Models on Graph-Structured Combinatorial Optimization
Jan 21, 2025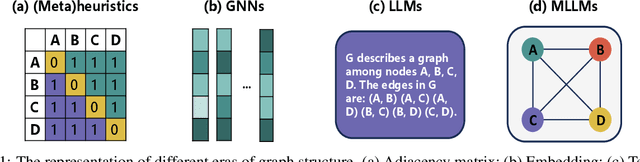


Graph-structured combinatorial challenges are inherently difficult due to their nonlinear and intricate nature, often rendering traditional computational methods ineffective or expensive. However, these challenges can be more naturally tackled by humans through visual representations that harness our innate ability for spatial reasoning. In this study, we propose transforming graphs into images to preserve their higher-order structural features accurately, revolutionizing the representation used in solving graph-structured combinatorial tasks. This approach allows machines to emulate human-like processing in addressing complex combinatorial challenges. By combining the innovative paradigm powered by multimodal large language models (MLLMs) with simple search techniques, we aim to develop a novel and effective framework for tackling such problems. Our investigation into MLLMs spanned a variety of graph-based tasks, from combinatorial problems like influence maximization to sequential decision-making in network dismantling, as well as addressing six fundamental graph-related issues. Our findings demonstrate that MLLMs exhibit exceptional spatial intelligence and a distinctive capability for handling these problems, significantly advancing the potential for machines to comprehend and analyze graph-structured data with a depth and intuition akin to human cognition. These results also imply that integrating MLLMs with simple optimization strategies could form a novel and efficient approach for navigating graph-structured combinatorial challenges without complex derivations, computationally demanding training and fine-tuning.
Students Rather Than Experts: A New AI For Education Pipeline To Model More Human-Like And Personalised Early Adolescences
Oct 21, 2024



The capabilities of large language models (LLMs) have been applied in expert systems across various domains, providing new opportunities for AI in Education. Educational interactions involve a cyclical exchange between teachers and students. Current research predominantly focuses on using LLMs to simulate teachers, leveraging their expertise to enhance student learning outcomes. However, the simulation of students, which could improve teachers' instructional skills, has received insufficient attention due to the challenges of modeling and evaluating virtual students. This research asks: Can LLMs be utilized to develop virtual student agents that mimic human-like behavior and individual variability? Unlike expert systems focusing on knowledge delivery, virtual students must replicate learning difficulties, emotional responses, and linguistic uncertainties. These traits present significant challenges in both modeling and evaluation. To address these issues, this study focuses on language learning as a context for modeling virtual student agents. We propose a novel AI4Education framework, called SOE (Scene-Object-Evaluation), to systematically construct LVSA (LLM-based Virtual Student Agents). By curating a dataset of personalized teacher-student interactions with various personality traits, question types, and learning stages, and fine-tuning LLMs using LoRA, we conduct multi-dimensional evaluation experiments. Specifically, we: (1) develop a theoretical framework for generating LVSA; (2) integrate human subjective evaluation metrics into GPT-4 assessments, demonstrating a strong correlation between human evaluators and GPT-4 in judging LVSA authenticity; and (3) validate that LLMs can generate human-like, personalized virtual student agents in educational contexts, laying a foundation for future applications in pre-service teacher training and multi-agent simulation environments.
Can LVLMs Describe Videos like Humans? A Five-in-One Video Annotations Benchmark for Better Human-Machine Comparison
Oct 20, 2024



Large vision-language models (LVLMs) have made significant strides in addressing complex video tasks, sparking researchers' interest in their human-like multimodal understanding capabilities. Video description serves as a fundamental task for evaluating video comprehension, necessitating a deep understanding of spatial and temporal dynamics, which presents challenges for both humans and machines. Thus, investigating whether LVLMs can describe videos as comprehensively as humans (through reasonable human-machine comparisons using video captioning as a proxy task) will enhance our understanding and application of these models. However, current benchmarks for video comprehension have notable limitations, including short video durations, brief annotations, and reliance on a single annotator's perspective. These factors hinder a comprehensive assessment of LVLMs' ability to understand complex, lengthy videos and prevent the establishment of a robust human baseline that accurately reflects human video comprehension capabilities. To address these issues, we propose a novel benchmark, FIOVA (Five In One Video Annotations), designed to evaluate the differences between LVLMs and human understanding more comprehensively. FIOVA includes 3,002 long video sequences (averaging 33.6 seconds) that cover diverse scenarios with complex spatiotemporal relationships. Each video is annotated by five distinct annotators, capturing a wide range of perspectives and resulting in captions that are 4-15 times longer than existing benchmarks, thereby establishing a robust baseline that represents human understanding comprehensively for the first time in video description tasks. Using the FIOVA benchmark, we conducted an in-depth evaluation of six state-of-the-art LVLMs, comparing their performance with humans. More detailed information can be found at https://huuuuusy.github.io/fiova/.
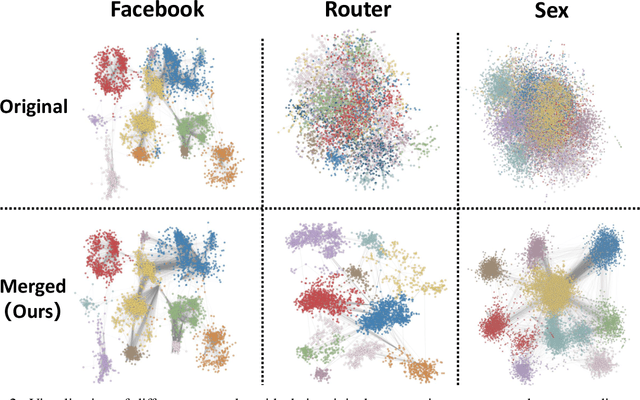
Multi-Domain Evolutionary Optimization of Network Structures
Jun 21, 2024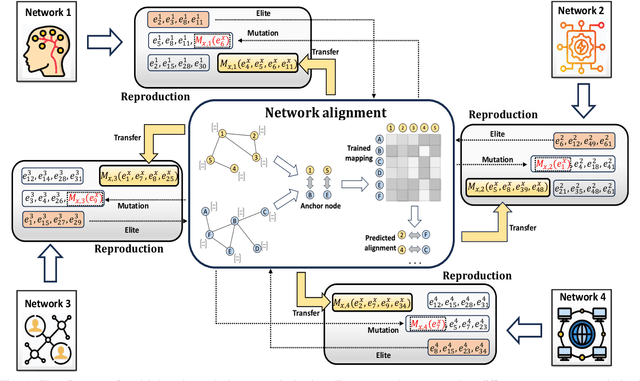
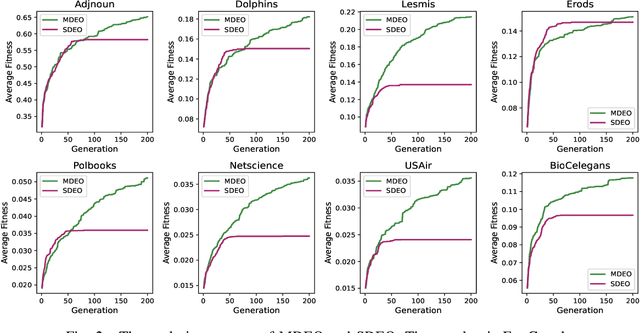
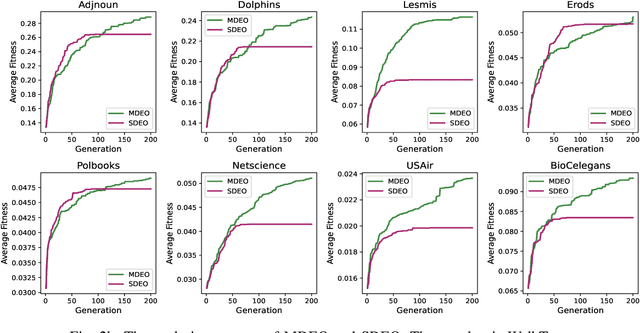
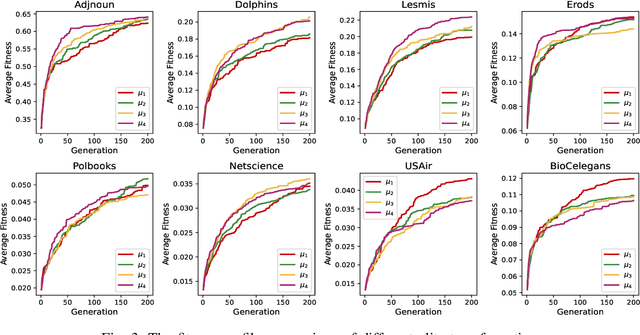
Multi-Task Evolutionary Optimization (MTEO), an important field focusing on addressing complex problems through optimizing multiple tasks simultaneously, has attracted much attention. While MTEO has been primarily focusing on task similarity, there remains a hugely untapped potential in harnessing the shared characteristics between different domains to enhance evolutionary optimization. For example, real-world complex systems usually share the same characteristics, such as the power-law rule, small-world property, and community structure, thus making it possible to transfer solutions optimized in one system to another to facilitate the optimization. Drawing inspiration from this observation of shared characteristics within complex systems, we set out to extend MTEO to a novel framework - multi-domain evolutionary optimization (MDEO). To examine the performance of the proposed MDEO, we utilize a challenging combinatorial problem of great security concern - community deception in complex networks as the optimization task. To achieve MDEO, we propose a community-based measurement of graph similarity to manage the knowledge transfer among domains. Furthermore, we develop a graph representation-based network alignment model that serves as the conduit for effectively transferring solutions between different domains. Moreover, we devise a self-adaptive mechanism to determine the number of transferred solutions from different domains and introduce a novel mutation operator based on the learned mapping to facilitate the utilization of knowledge from other domains. Experiments on eight real-world networks of different domains demonstrate MDEO superiority in efficacy compared to classical evolutionary optimization. Simulations of attacks on the community validate the effectiveness of the proposed MDEO in safeguarding community security.
Limit of the Maximum Random Permutation Set Entropy
Mar 10, 2024



The Random Permutation Set (RPS) is a new type of set proposed recently, which can be regarded as the generalization of evidence theory. To measure the uncertainty of RPS, the entropy of RPS and its corresponding maximum entropy have been proposed. Exploring the maximum entropy provides a possible way of understanding the physical meaning of RPS. In this paper, a new concept, the envelope of entropy function, is defined. In addition, the limit of the envelope of RPS entropy is derived and proved. Compared with the existing method, the computational complexity of the proposed method to calculate the envelope of RPS entropy decreases greatly. The result shows that when $N \to \infty$, the limit form of the envelope of the entropy of RPS converges to $e \times (N!)^2$, which is highly connected to the constant $e$ and factorial. Finally, numerical examples validate the efficiency and conciseness of the proposed envelope, which provides a new insight into the maximum entropy function.
When does the Physarum Solver Distinguish the Shortest Path from other Paths: the Transition Point and its Applications
Jan 08, 2021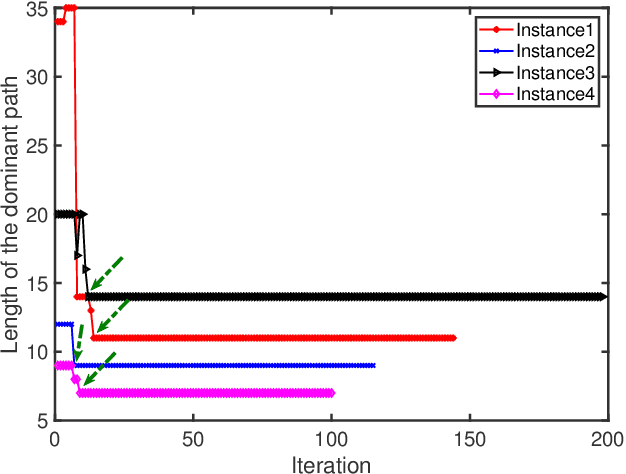
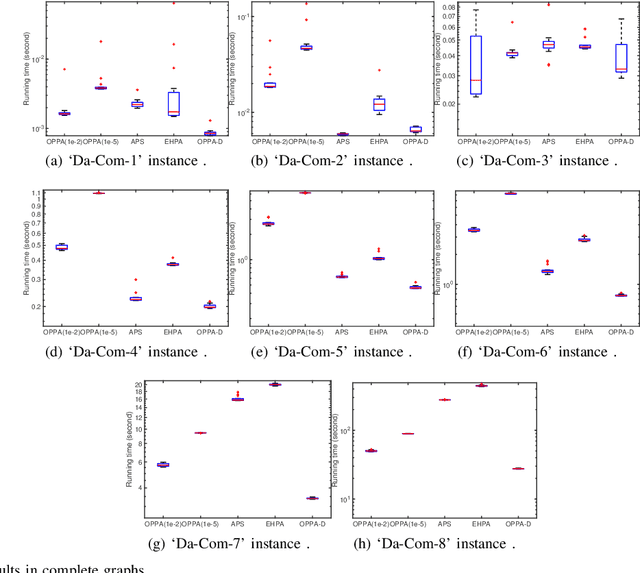
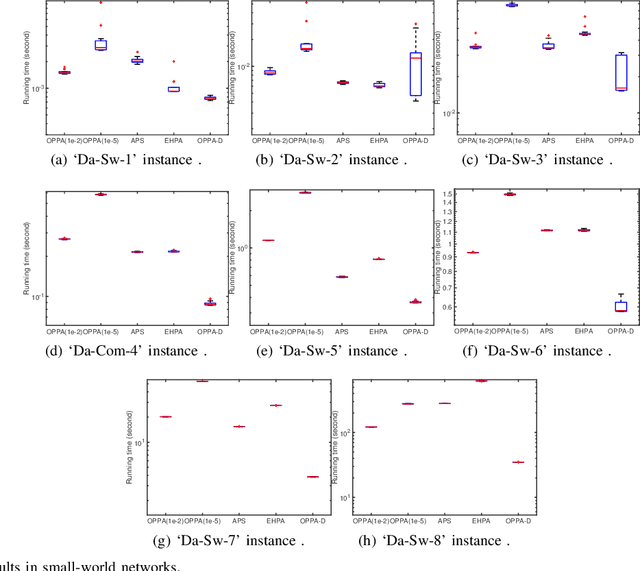
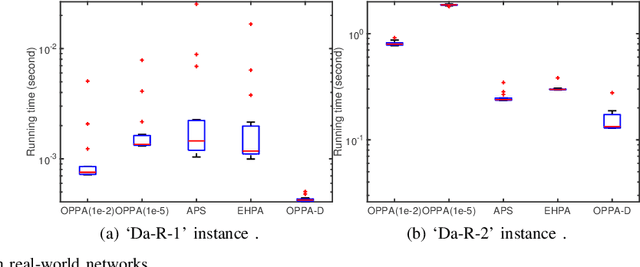
Physarum solver, also called the physarum polycephalum inspired algorithm (PPA), is a newly developed bio-inspired algorithm that has an inherent ability to find the shortest path in a given graph. Recent research has proposed methods to develop this algorithm further by accelerating the original PPA (OPPA)'s path-finding process. However, when does the PPA ascertain that the shortest path has been found? Is there a point after which the PPA could distinguish the shortest path from other paths? By innovatively proposing the concept of the dominant path (D-Path), the exact moment, named the transition point (T-Point), when the PPA finds the shortest path can be identified. Based on the D-Path and T-Point, a newly accelerated PPA named OPPA-D using the proposed termination criterion is developed which is superior to all other baseline algorithms according to the experiments conducted in this paper. The validity and the superiority of the proposed termination criterion is also demonstrated. Furthermore, an evaluation method is proposed to provide new insights for the comparison of different accelerated OPPAs. The breakthrough of this paper lies in using D-path and T-point to terminate the OPPA. The novel termination criterion reveals the actual performance of this OPPA. This OPPA is the fastest algorithm, outperforming some so-called accelerated OPPAs. Furthermore, we explain why some existing works inappropriately claim to be accelerated algorithms is in fact a product of inappropriate termination criterion, thus giving rise to the illusion that the method is accelerated.
The Capacity Constraint Physarum Solver
Oct 19, 2020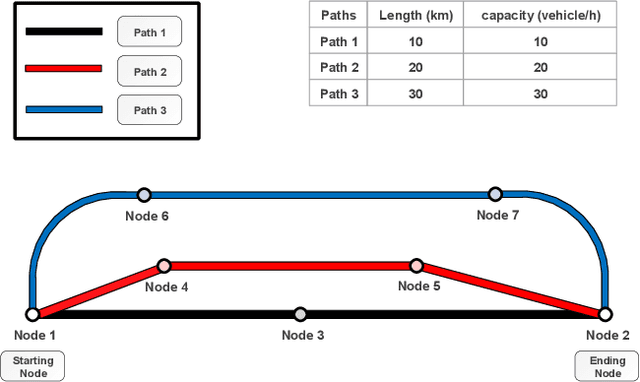

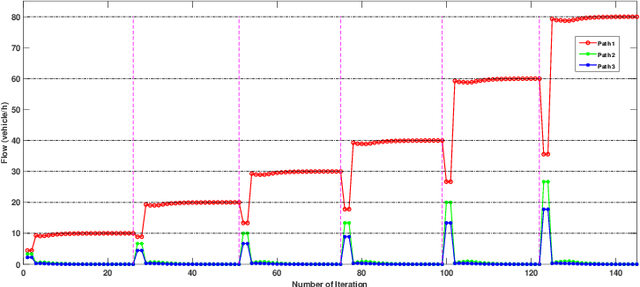
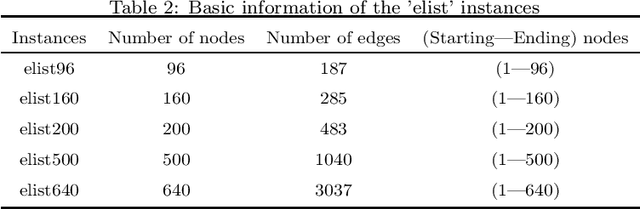
Physarum polycephalum inspired algorithm (PPA), also known as the Physarum Solver, has attracted great attention. By modelling real-world problems into a graph with network flow and adopting proper equations to calculate the distance between the nodes in the graph, PPA could be used to solve system optimization problems or user equilibrium problems. However, some problems such as the maximum flow (MF) problem, minimum-cost-maximum-flow (MCMF) problem, and link-capacitated traffic assignment problem (CTAP), require the flow flowing through links to follow capacity constraints. Motivated by the lack of related PPA-based research, a novel framework, the capacitated physarum polycephalum inspired algorithm (CPPA), is proposed to allow capacity constraints toward link flow in the PPA. To prove the validity of the CPPA, we developed three applications of the CPPA, i.e., the CPPA for the MF problem (CPPA-MF), the CPPA for the MCFC problem, and the CPPA for the link-capacitated traffic assignment problem (CPPA-CTAP). In the experiments, all the applications of the CPPA solve the problems successfully. Some of them demonstrate efficiency compared to the baseline algorithms. The experimental results prove the validation of using the CPPA framework to control link flow in the PPA is valid. The CPPA is also very robust and easy to implement since it could be successfully applied in three different scenarios. The proposed method shows that: having the ability to control the maximum among flow flowing through links in the PPA, the CPPA could tackle more complex real-world problems in the future.