 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Be Trusted as Black-Box Evolutionary Optimizers for Combinatorial Problems?
Paper and Code
Jan 25, 2025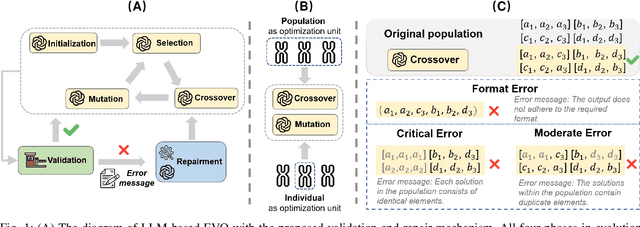
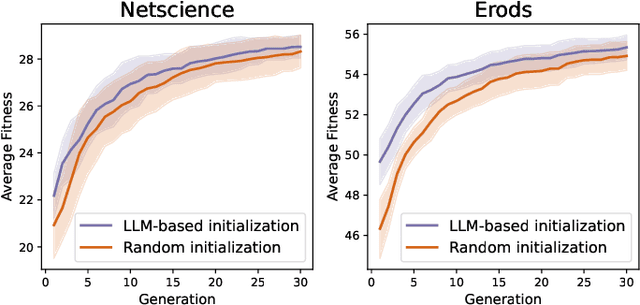


Evolutionary computation excels in complex optimization but demands deep domain knowledge, restricting its accessibility. Large Language Models (LLMs) offer a game-changing solution with their extensive knowledge and could democratize the optimization paradigm. Although LLMs possess significant capabilities, they may not be universally effective, particularly since evolutionary optimization encompasses multiple stages. It is therefore imperative to evaluate the suitability of LLMs as evolutionary optimizer (EVO). Thus, we establish a series of rigid standards to thoroughly examine the fidelity of LLM-based EVO output in different stages of evolutionary optimization and then introduce a robust error-correction mechanism to mitigate the output uncertainty. Furthermore, we explore a cost-efficient method that directly operates on entire populations with excellent effectiveness in contrast to individual-level optimization. Through extensive experiments, we rigorously validate the performance of LLMs as operators targeted for combinatorial problems. Our findings provide critical insights and valuable observations, advancing the understanding and application of LLM-based optimization.