 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Grammar Induction for Language Understanding and Generation
Oct 07, 2024



Grammar induction has made significant progress in recent years. However, it is not clear how the application of induced grammar could enhance practical performance in downstream tasks. In this work, we introduce an unsupervised grammar induction method for language understanding and generation. We construct a grammar parser to induce constituency structures and dependency relations, which is simultaneously trained on downstream tasks without additional syntax annotations. The induced grammar features are subsequently incorporated into Transformer as a syntactic mask to guide self-attention. We evaluate and apply our method to multiple machine translation tasks and natural language understanding tasks. Our method demonstrates superior performance compared to the original Transformer and other models enhanced with external parsers. Experimental results indicate that our method is effective in both from-scratch and pre-trained scenarios. Additionally, our research highlights the contribution of explicitly modeling the grammatical structure of texts to neural network models.
Linear-time online visibility graph transformation algorithm: for both natural and horizontal visibility criteria
Nov 21, 2023Visibility graph (VG) transformation is a technique used to convert a time series into a graph based on specific visibility criteria. It has attracted increasing interest in the fields of time series analysis, forecasting, and classification. Optimizing the VG transformation algorithm to accelerate the process is a critical aspect of VG-related research, as it enhances the applicability of VG transformation in latency-sensitive areas and conserves computational resources. In the real world, many time series are presented in the form of data streams. Despite the proposal of the concept of VG's online functionality, previous studies have not thoroughly explored the acceleration of VG transformation by leveraging the characteristics of data streams. In this paper, we propose that an efficient online VG algorithm should adhere to two criteria and develop a linear-time method, termed the LOT framework, for both natural and horizontal visibility graph transformations in data stream scenarios. Experiments are conducted on two datasets, comparing our approach with five existing methods as baselines. The results demonstrate the validity and promising computational efficiency of our framework.
I2SRM: Intra- and Inter-Sample Relationship Modeling for Multimodal Information Extraction
Oct 10, 2023Multimodal information extraction is attracting research attention nowadays, which requires aggregating representations from different modalities. In this paper, we present the Intra- and Inter-Sample Relationship Modeling (I2SRM) method for this task, which contains two modules. Firstly, the intra-sample relationship modeling module operates on a single sample and aims to learn effective representations. Embeddings from textual and visual modalities are shifted to bridge the modality gap caused by distinct pre-trained language and image models. Secondly, the inter-sample relationship modeling module considers relationships among multiple samples and focuses on capturing the interactions. An AttnMixup strategy is proposed, which not only enables collaboration among samples but also augments data to improve generalization. We conduct extensive experiments on the multimodal named entity recognition datasets Twitter-2015 and Twitter-2017, and the multimodal relation extraction dataset MNRE. Our proposed method I2SRM achieves competitive results, 77.12% F1-score on Twitter-2015, 88.40% F1-score on Twitter-2017, and 84.12% F1-score on MNRE.
Asymmetric Polynomial Loss For Multi-Label Classification
Apr 10, 2023



Various tasks are reformulated as multi-label classification problems, in which the binary cross-entropy (BCE) loss is frequently utilized for optimizing well-designed models. However, the vanilla BCE loss cannot be tailored for diverse tasks, resulting in a suboptimal performance for different models. Besides, the imbalance between redundant negative samples and rare positive samples could degrade the model performance. In this paper, we propose an effective Asymmetric Polynomial Loss (APL) to mitigate the above issues. Specifically, we first perform Taylor expansion on BCE loss. Then we ameliorate the coefficients of polynomial functions. We further employ the asymmetric focusing mechanism to decouple the gradient contribution from the negative and positive samples. Moreover, we validate that the polynomial coefficients can recalibrate the asymmetric focusing hyperparameters. Experiments on relation extraction, text classification, and image classification show that our APL loss can consistently improve performance without extra training burden.
Text Classification in the Wild: a Large-scale Long-tailed Name Normalization Dataset
Feb 19, 2023Real-world data usually exhibits a long-tailed distribution,with a few frequent labels and a lot of few-shot labels. The study of institution name normalization is a perfect application case showing this phenomenon. There are many institutions worldwide with enormous variations of their names in the publicly available literature. In this work, we first collect a large-scale institution name normalization dataset LoT-insts1, which contains over 25k classes that exhibit a naturally long-tailed distribution. In order to isolate the few-shot and zero-shot learning scenarios from the massive many-shot classes, we construct our test set from four different subsets: many-, medium-, and few-shot sets, as well as a zero-shot open set. We also replicate several important baseline methods on our data, covering a wide range from search-based methods to neural network methods that use the pretrained BERT model. Further, we propose our specially pretrained, BERT-based model that shows better out-of-distribution generalization on few-shot and zero-shot test sets. Compared to other datasets focusing on the long-tailed phenomenon, our dataset has one order of magnitude more training data than the largest existing long-tailed datasets and is naturally long-tailed rather than manually synthesized. We believe it provides an important and different scenario to study this problem. To our best knowledge, this is the first natural language dataset that focuses on long-tailed and open-set classification problems.
Belief Evolution Network: Probability Transformation of Basic Belief Assignment and Fusion Conflict Probability
Oct 07, 2021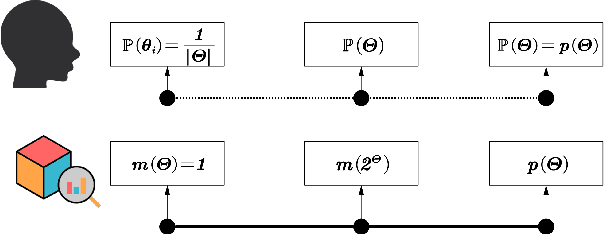
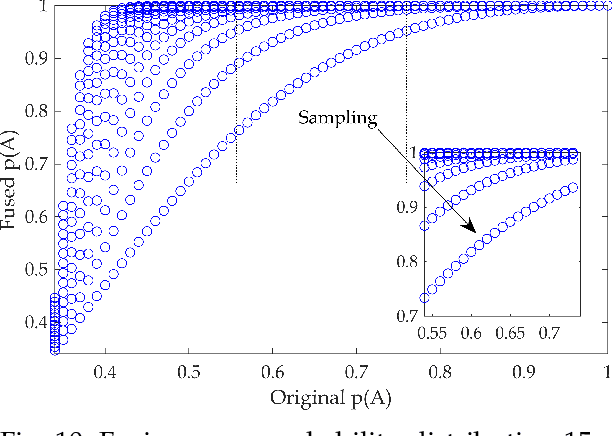
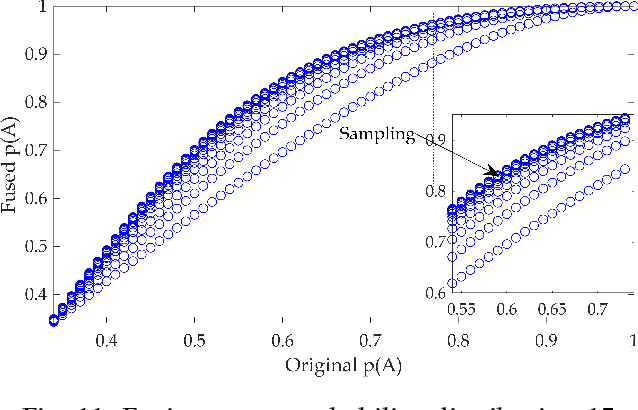
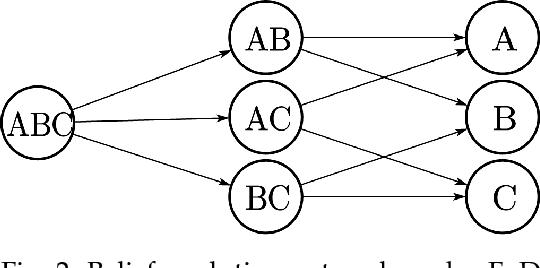
We give a new interpretation of basic belief assignment transformation into probability distribution, and use directed acyclic network called belief evolution network to describe the causality between the focal elements of a BBA. On this basis, a new probability transformations method called full causality probability transformation is proposed, and this method is superior to all previous method after verification from the process and the result. In addition, using this method combined with disjunctive combination rule, we propose a new probabilistic combination rule called disjunctive transformation combination rule. It has an excellent ability to merge conflicts and an interesting pseudo-Matthew effect, which offer a new idea to information fusion besides the combination rule of Dempster.
When does the Physarum Solver Distinguish the Shortest Path from other Paths: the Transition Point and its Applications
Jan 08, 2021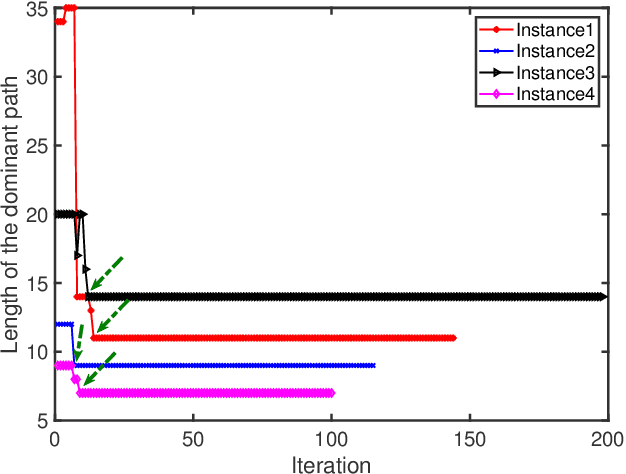
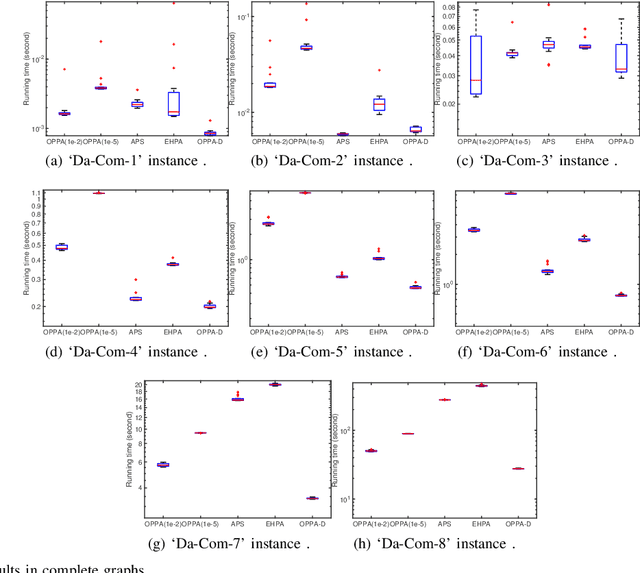
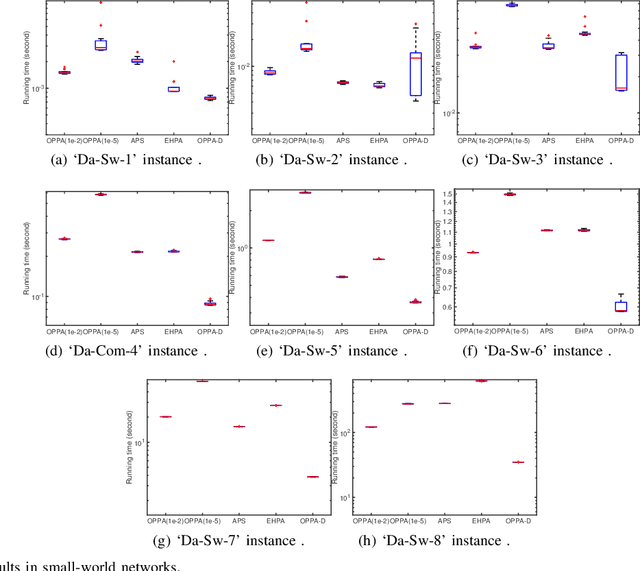
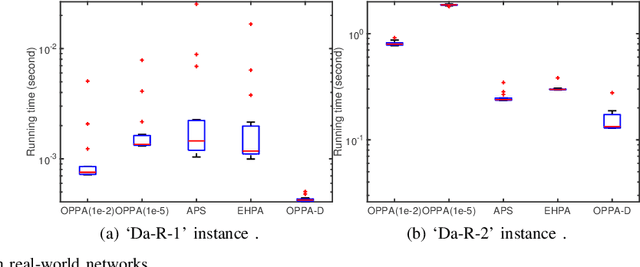
Physarum solver, also called the physarum polycephalum inspired algorithm (PPA), is a newly developed bio-inspired algorithm that has an inherent ability to find the shortest path in a given graph. Recent research has proposed methods to develop this algorithm further by accelerating the original PPA (OPPA)'s path-finding process. However, when does the PPA ascertain that the shortest path has been found? Is there a point after which the PPA could distinguish the shortest path from other paths? By innovatively proposing the concept of the dominant path (D-Path), the exact moment, named the transition point (T-Point), when the PPA finds the shortest path can be identified. Based on the D-Path and T-Point, a newly accelerated PPA named OPPA-D using the proposed termination criterion is developed which is superior to all other baseline algorithms according to the experiments conducted in this paper. The validity and the superiority of the proposed termination criterion is also demonstrated. Furthermore, an evaluation method is proposed to provide new insights for the comparison of different accelerated OPPAs. The breakthrough of this paper lies in using D-path and T-point to terminate the OPPA. The novel termination criterion reveals the actual performance of this OPPA. This OPPA is the fastest algorithm, outperforming some so-called accelerated OPPAs. Furthermore, we explain why some existing works inappropriately claim to be accelerated algorithms is in fact a product of inappropriate termination criterion, thus giving rise to the illusion that the method is accelerated.
The Capacity Constraint Physarum Solver
Oct 19, 2020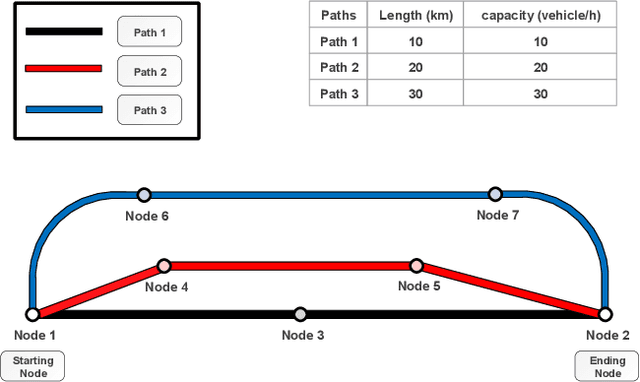

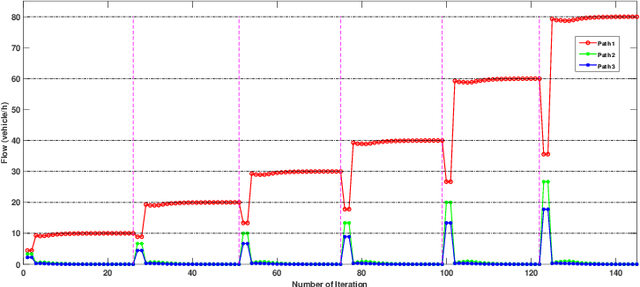
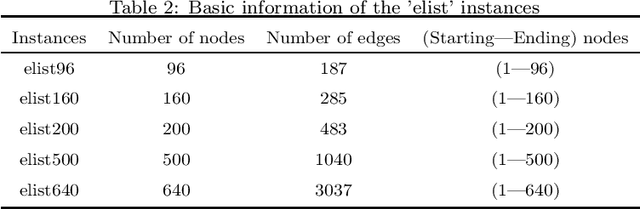
Physarum polycephalum inspired algorithm (PPA), also known as the Physarum Solver, has attracted great attention. By modelling real-world problems into a graph with network flow and adopting proper equations to calculate the distance between the nodes in the graph, PPA could be used to solve system optimization problems or user equilibrium problems. However, some problems such as the maximum flow (MF) problem, minimum-cost-maximum-flow (MCMF) problem, and link-capacitated traffic assignment problem (CTAP), require the flow flowing through links to follow capacity constraints. Motivated by the lack of related PPA-based research, a novel framework, the capacitated physarum polycephalum inspired algorithm (CPPA), is proposed to allow capacity constraints toward link flow in the PPA. To prove the validity of the CPPA, we developed three applications of the CPPA, i.e., the CPPA for the MF problem (CPPA-MF), the CPPA for the MCFC problem, and the CPPA for the link-capacitated traffic assignment problem (CPPA-CTAP). In the experiments, all the applications of the CPPA solve the problems successfully. Some of them demonstrate efficiency compared to the baseline algorithms. The experimental results prove the validation of using the CPPA framework to control link flow in the PPA is valid. The CPPA is also very robust and easy to implement since it could be successfully applied in three different scenarios. The proposed method shows that: having the ability to control the maximum among flow flowing through links in the PPA, the CPPA could tackle more complex real-world problems in the future.