 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpaceTrack-TimeSeries: Time Series Dataset towards Satellite Orbit Analysis
Jun 16, 2025With the rapid advancement of aerospace technology and the large-scale deployment of low Earth orbit (LEO) satellite constellations, the challenges facing astronomical observations and deep space exploration have become increasingly pronounced. As a result, the demand for high-precision orbital data on space objects-along with comprehensive analyses of satellite positioning, constellation configurations, and deep space satellite dynamics-has grown more urgent. However, there remains a notable lack of publicly accessible, real-world datasets to support research in areas such as space object maneuver behavior prediction and collision risk assessment. This study seeks to address this gap by collecting and curating a representative dataset of maneuvering behavior from Starlink satellites. The dataset integrates Two-Line Element (TLE) catalog data with corresponding high-precision ephemeris data, thereby enabling a more realistic and multidimensional modeling of space object behavior. It provides valuable insights into practical deployment of maneuver detection methods and the evaluation of collision risks in increasingly congested orbital environments.
AceMap: Knowledge Discovery through Academic Graph
Mar 05, 2024
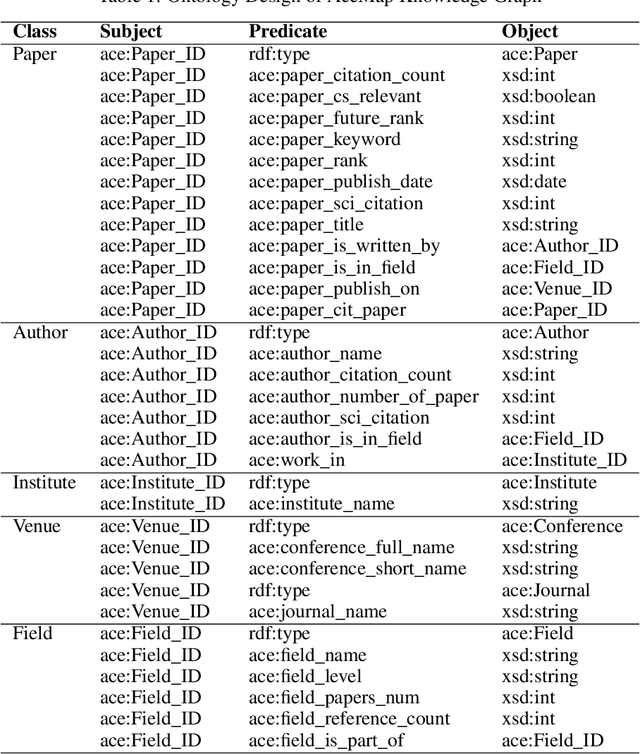
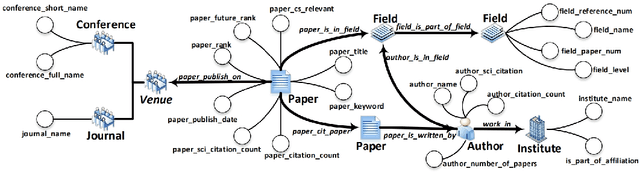
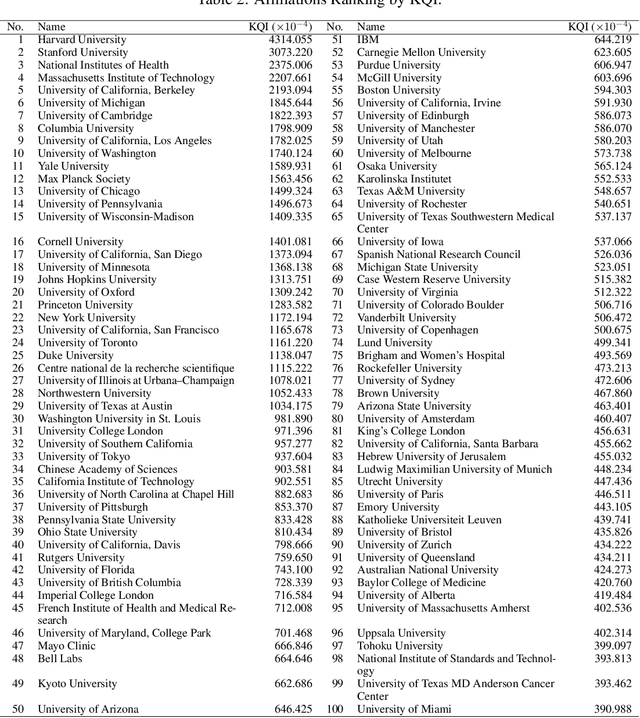
The exponential growth of scientific literature requires effective management and extraction of valuable insights. While existing scientific search engines excel at delivering search results based on relational databases, they often neglect the analysis of collaborations between scientific entities and the evolution of ideas, as well as the in-depth analysis of content within scientific publications. The representation of heterogeneous graphs and the effective measurement, analysis, and mining of such graphs pose significant challenges. To address these challenges, we present AceMap, an academic system designed for knowledge discovery through academic graph. We present advanced database construction techniques to build the comprehensive AceMap database with large-scale academic publications that contain rich visual, textual, and numerical information. AceMap also employs innovative visualization, quantification, and analysis methods to explore associations and logical relationships among academic entities. AceMap introduces large-scale academic network visualization techniques centered on nebular graphs, providing a comprehensive view of academic networks from multiple perspectives. In addition, AceMap proposes a unified metric based on structural entropy to quantitatively measure the knowledge content of different academic entities. Moreover, AceMap provides advanced analysis capabilities, including tracing the evolution of academic ideas through citation relationships and concept co-occurrence, and generating concise summaries informed by this evolutionary process. In addition, AceMap uses machine reading methods to generate potential new ideas at the intersection of different fields. Exploring the integration of large language models and knowledge graphs is a promising direction for future research in idea evolution. Please visit \url{https://www.acemap.info} for further exploration.
Towards Controlled Table-to-Text Generation with Scientific Reasoning
Dec 08, 2023The sheer volume of scientific experimental results and complex technical statements, often presented in tabular formats, presents a formidable barrier to individuals acquiring preferred information. The realms of scientific reasoning and content generation that adhere to user preferences encounter distinct challenges. In this work, we present a new task for generating fluent and logical descriptions that match user preferences over scientific tabular data, aiming to automate scientific document analysis. To facilitate research in this direction, we construct a new challenging dataset CTRLSciTab consisting of table-description pairs extracted from the scientific literature, with highlighted cells and corresponding domain-specific knowledge base. We evaluated popular pre-trained language models to establish a baseline and proposed a novel architecture outperforming competing approaches. The results showed that large models struggle to produce accurate content that aligns with user preferences. As the first of its kind, our work should motivate further research in scientific domains.
Few-Shot Table-to-Text Generation with Prompt-based Adapter
Feb 24, 2023



Pre-trained language models (PLMs) have made remarkable progress in table-to-text generation tasks. However, the topological gap between tabular data and text and the lack of domain-specific knowledge make it difficult for PLMs to produce faithful text, especially in real-world applications with limited resources. In this paper, we mitigate the above challenges by introducing a novel augmentation method: Prompt-based Adapter (PA), which targets table-to-text generation under few-shot conditions. The core insight design of the PA is to inject prompt templates for augmenting domain-specific knowledge and table-related representations into the model for bridging the structural gap between tabular data and descriptions through adapters. Such prompt-based knowledge augmentation method brings at least two benefits: (1) enables us to fully use the large amounts of unlabelled domain-specific knowledge, which can alleviate the PLMs' inherent shortcomings of lacking domain knowledge; (2) allows us to design different types of tasks supporting the generative challenge. Extensive experiments and analyses are conducted on three open-domain few-shot NLG datasets: Humans, Books, and Songs. Compared to previous state-of-the-art approaches, our model achieves superior performance in terms of both fluency and accuracy as judged by human and automatic evaluations.
Few-Shot Table-to-Text Generation with Prompt Planning and Knowledge Memorization
Feb 24, 2023



Pre-trained language models (PLM) have achieved remarkable advancement in table-to-text generation tasks. However, the lack of labeled domain-specific knowledge and the topology gap between tabular data and text make it difficult for PLMs to yield faithful text. Low-resource generation likewise faces unique challenges in this domain. Inspired by how humans descript tabular data with prior knowledge, we suggest a new framework: PromptMize, which targets table-to-text generation under few-shot settings. The design of our framework consists of two aspects: a prompt planner and a knowledge adapter. The prompt planner aims to generate a prompt signal that provides instance guidance for PLMs to bridge the topology gap between tabular data and text. Moreover, the knowledge adapter memorizes domain-specific knowledge from the unlabelled corpus to supply essential information during generation. Extensive experiments and analyses are investigated on three open domain few-shot NLG datasets: human, song, and book. Compared with previous state-of-the-art approaches, our model achieves remarkable performance in generating quality as judged by human and automatic evaluations.
Text Classification in the Wild: a Large-scale Long-tailed Name Normalization Dataset
Feb 19, 2023Real-world data usually exhibits a long-tailed distribution,with a few frequent labels and a lot of few-shot labels. The study of institution name normalization is a perfect application case showing this phenomenon. There are many institutions worldwide with enormous variations of their names in the publicly available literature. In this work, we first collect a large-scale institution name normalization dataset LoT-insts1, which contains over 25k classes that exhibit a naturally long-tailed distribution. In order to isolate the few-shot and zero-shot learning scenarios from the massive many-shot classes, we construct our test set from four different subsets: many-, medium-, and few-shot sets, as well as a zero-shot open set. We also replicate several important baseline methods on our data, covering a wide range from search-based methods to neural network methods that use the pretrained BERT model. Further, we propose our specially pretrained, BERT-based model that shows better out-of-distribution generalization on few-shot and zero-shot test sets. Compared to other datasets focusing on the long-tailed phenomenon, our dataset has one order of magnitude more training data than the largest existing long-tailed datasets and is naturally long-tailed rather than manually synthesized. We believe it provides an important and different scenario to study this problem. To our best knowledge, this is the first natural language dataset that focuses on long-tailed and open-set classification problems.