 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTSCI: A Conditional Diffusion Model for Multivariate Time Series Consistent Imputation
Aug 11, 2024



Missing values are prevalent in multivariate time series, compromising the integrity of analyses and degrading the performance of downstream tasks. Consequently, research has focused on multivariate time series imputation, aiming to accurately impute the missing values based on available observations. A key research question is how to ensure imputation consistency, i.e., intra-consistency between observed and imputed values, and inter-consistency between adjacent windows after imputation. However, previous methods rely solely on the inductive bias of the imputation targets to guide the learning process, ignoring imputation consistency and ultimately resulting in poor performance. Diffusion models, known for their powerful generative abilities, prefer to generate consistent results based on available observations. Therefore, we propose a conditional diffusion model for Multivariate Time Series Consistent Imputation (MTSCI). Specifically, MTSCI employs a contrastive complementary mask to generate dual views during the forward noising process. Then, the intra contrastive loss is calculated to ensure intra-consistency between the imputed and observed values. Meanwhile, MTSCI utilizes a mixup mechanism to incorporate conditional information from adjacent windows during the denoising process, facilitating the inter-consistency between imputed samples. Extensive experiments on multiple real-world datasets demonstrate that our method achieves the state-of-the-art performance on multivariate time series imputation task under different missing scenarios. Code is available at https://github.com/JeremyChou28/MTSCI.
MagiNet: Mask-Aware Graph Imputation Network for Incomplete Traffic Data
Jun 05, 2024



Due to detector malfunctions and communication failures, missing data is ubiquitous during the collection of traffic data. Therefore, it is of vital importance to impute the missing values to facilitate data analysis and decision-making for Intelligent Transportation System (ITS). However, existing imputation methods generally perform zero pre-filling techniques to initialize missing values, introducing inevitable noises. Moreover, we observe prevalent over-smoothing interpolations, falling short in revealing the intrinsic spatio-temporal correlations of incomplete traffic data. To this end, we propose Mask-Aware Graph imputation Network: MagiNet. Our method designs an adaptive mask spatio-temporal encoder to learn the latent representations of incomplete data, eliminating the reliance on pre-filling missing values. Furthermore, we devise a spatio-temporal decoder that stacks multiple blocks to capture the inherent spatial and temporal dependencies within incomplete traffic data, alleviating over-smoothing imputation. Extensive experiments demonstrate that our method outperforms state-of-the-art imputation methods on five real-world traffic datasets, yielding an average improvement of 4.31% in RMSE and 3.72% in MAPE.
AceMap: Knowledge Discovery through Academic Graph
Mar 05, 2024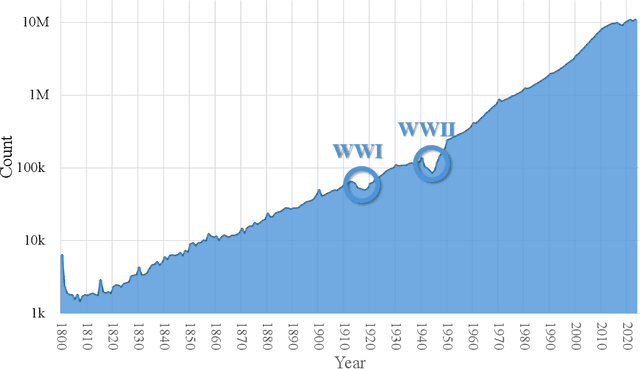
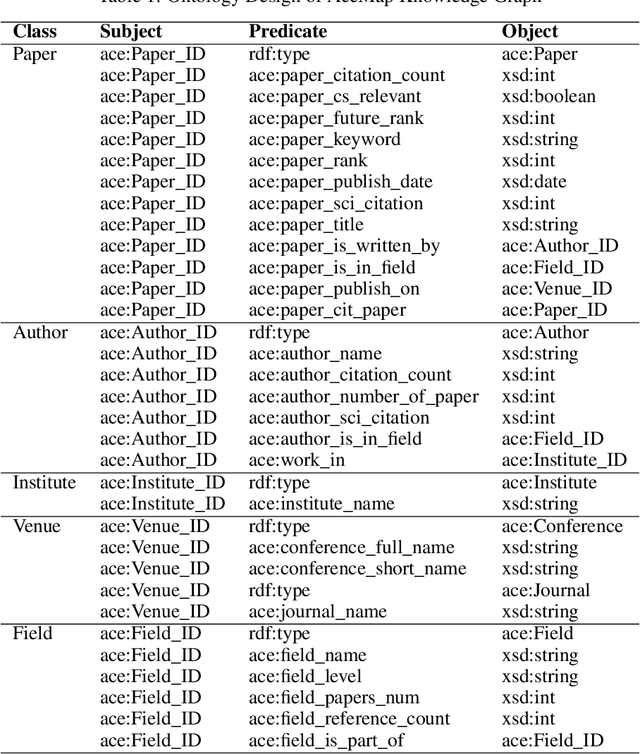
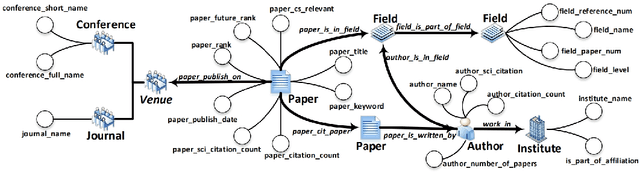
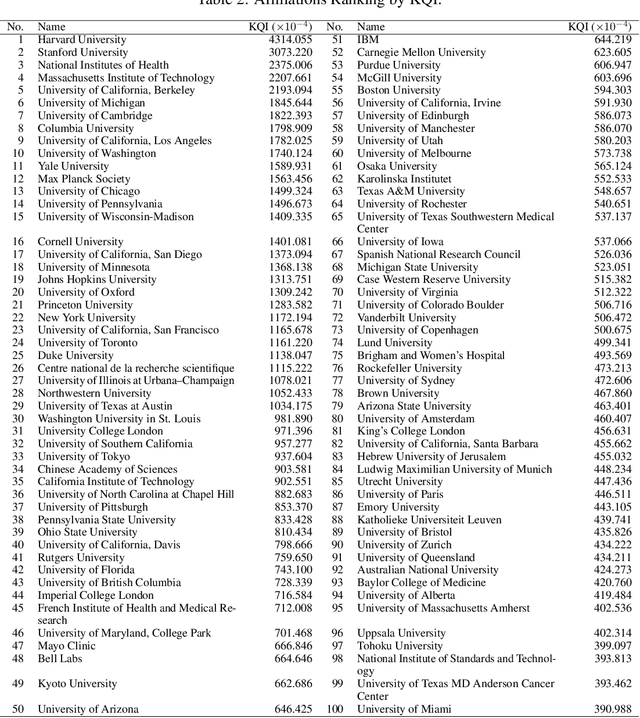
The exponential growth of scientific literature requires effective management and extraction of valuable insights. While existing scientific search engines excel at delivering search results based on relational databases, they often neglect the analysis of collaborations between scientific entities and the evolution of ideas, as well as the in-depth analysis of content within scientific publications. The representation of heterogeneous graphs and the effective measurement, analysis, and mining of such graphs pose significant challenges. To address these challenges, we present AceMap, an academic system designed for knowledge discovery through academic graph. We present advanced database construction techniques to build the comprehensive AceMap database with large-scale academic publications that contain rich visual, textual, and numerical information. AceMap also employs innovative visualization, quantification, and analysis methods to explore associations and logical relationships among academic entities. AceMap introduces large-scale academic network visualization techniques centered on nebular graphs, providing a comprehensive view of academic networks from multiple perspectives. In addition, AceMap proposes a unified metric based on structural entropy to quantitatively measure the knowledge content of different academic entities. Moreover, AceMap provides advanced analysis capabilities, including tracing the evolution of academic ideas through citation relationships and concept co-occurrence, and generating concise summaries informed by this evolutionary process. In addition, AceMap uses machine reading methods to generate potential new ideas at the intersection of different fields. Exploring the integration of large language models and knowledge graphs is a promising direction for future research in idea evolution. Please visit \url{https://www.acemap.info} for further exploration.
Towards Controlled Table-to-Text Generation with Scientific Reasoning
Dec 08, 2023The sheer volume of scientific experimental results and complex technical statements, often presented in tabular formats, presents a formidable barrier to individuals acquiring preferred information. The realms of scientific reasoning and content generation that adhere to user preferences encounter distinct challenges. In this work, we present a new task for generating fluent and logical descriptions that match user preferences over scientific tabular data, aiming to automate scientific document analysis. To facilitate research in this direction, we construct a new challenging dataset CTRLSciTab consisting of table-description pairs extracted from the scientific literature, with highlighted cells and corresponding domain-specific knowledge base. We evaluated popular pre-trained language models to establish a baseline and proposed a novel architecture outperforming competing approaches. The results showed that large models struggle to produce accurate content that aligns with user preferences. As the first of its kind, our work should motivate further research in scientific domains.
Few-Shot Table-to-Text Generation with Prompt-based Adapter
Feb 24, 2023



Pre-trained language models (PLMs) have made remarkable progress in table-to-text generation tasks. However, the topological gap between tabular data and text and the lack of domain-specific knowledge make it difficult for PLMs to produce faithful text, especially in real-world applications with limited resources. In this paper, we mitigate the above challenges by introducing a novel augmentation method: Prompt-based Adapter (PA), which targets table-to-text generation under few-shot conditions. The core insight design of the PA is to inject prompt templates for augmenting domain-specific knowledge and table-related representations into the model for bridging the structural gap between tabular data and descriptions through adapters. Such prompt-based knowledge augmentation method brings at least two benefits: (1) enables us to fully use the large amounts of unlabelled domain-specific knowledge, which can alleviate the PLMs' inherent shortcomings of lacking domain knowledge; (2) allows us to design different types of tasks supporting the generative challenge. Extensive experiments and analyses are conducted on three open-domain few-shot NLG datasets: Humans, Books, and Songs. Compared to previous state-of-the-art approaches, our model achieves superior performance in terms of both fluency and accuracy as judged by human and automatic evaluations.
Few-Shot Table-to-Text Generation with Prompt Planning and Knowledge Memorization
Feb 24, 2023



Pre-trained language models (PLM) have achieved remarkable advancement in table-to-text generation tasks. However, the lack of labeled domain-specific knowledge and the topology gap between tabular data and text make it difficult for PLMs to yield faithful text. Low-resource generation likewise faces unique challenges in this domain. Inspired by how humans descript tabular data with prior knowledge, we suggest a new framework: PromptMize, which targets table-to-text generation under few-shot settings. The design of our framework consists of two aspects: a prompt planner and a knowledge adapter. The prompt planner aims to generate a prompt signal that provides instance guidance for PLMs to bridge the topology gap between tabular data and text. Moreover, the knowledge adapter memorizes domain-specific knowledge from the unlabelled corpus to supply essential information during generation. Extensive experiments and analyses are investigated on three open domain few-shot NLG datasets: human, song, and book. Compared with previous state-of-the-art approaches, our model achieves remarkable performance in generating quality as judged by human and automatic evaluations.