 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedTopo: Topology-Informed Representation Alignment in Federated Learning under Non-I.I.D. Conditions
Nov 16, 2025Current federated-learning models deteriorate under heterogeneous (non-I.I.D.) client data, as their feature representations diverge and pixel- or patch-level objectives fail to capture the global topology which is essential for high-dimensional visual tasks. We propose FedTopo, a framework that integrates Topological-Guided Block Screening (TGBS) and Topological Embedding (TE) to leverage topological information, yielding coherently aligned cross-client representations by Topological Alignment Loss (TAL). First, Topology-Guided Block Screening (TGBS) automatically selects the most topology-informative block, i.e., the one with maximal topological separability, whose persistence-based signatures best distinguish within- versus between-class pairs, ensuring that subsequent analysis focuses on topology-rich features. Next, this block yields a compact Topological Embedding, which quantifies the topological information for each client. Finally, a Topological Alignment Loss (TAL) guides clients to maintain topological consistency with the global model during optimization, reducing representation drift across rounds. Experiments on Fashion-MNIST, CIFAR-10, and CIFAR-100 under four non-I.I.D. partitions show that FedTopo accelerates convergence and improves accuracy over strong baselines.
PVMark: Enabling Public Verifiability for LLM Watermarking Schemes
Oct 30, 2025Watermarking schemes for large language models (LLMs) have been proposed to identify the source of the generated text, mitigating the potential threats emerged from model theft. However, current watermarking solutions hardly resolve the trust issue: the non-public watermark detection cannot prove itself faithfully conducting the detection. We observe that it is attributed to the secret key mostly used in the watermark detection -- it cannot be public, or the adversary may launch removal attacks provided the key; nor can it be private, or the watermarking detection is opaque to the public. To resolve the dilemma, we propose PVMark, a plugin based on zero-knowledge proof (ZKP), enabling the watermark detection process to be publicly verifiable by third parties without disclosing any secret key. PVMark hinges upon the proof of `correct execution' of watermark detection on which a set of ZKP constraints are built, including mapping, random number generation, comparison, and summation. We implement multiple variants of PVMark in Python, Rust and Circom, covering combinations of three watermarking schemes, three hash functions, and four ZKP protocols, to show our approach effectively works under a variety of circumstances. By experimental results, PVMark efficiently enables public verifiability on the state-of-the-art LLM watermarking schemes yet without compromising the watermarking performance, promising to be deployed in practice.
Weights Shuffling for Improving DPSGD in Transformer-based Models
Jul 22, 2024Differential Privacy (DP) mechanisms, especially in high-dimensional settings, often face the challenge of maintaining privacy without compromising the data utility. This work introduces an innovative shuffling mechanism in Differentially-Private Stochastic Gradient Descent (DPSGD) to enhance the utility of large models at the same privacy guarantee of the unshuffled case. Specifically, we reveal that random shuffling brings additional randomness to the trajectory of gradient descent while not impacting the model accuracy by the permutation invariance property -- the model can be equivalently computed in both forward and backward propagations under permutation. We show that permutation indeed improves the privacy guarantee of DPSGD in theory, but tracking the exact privacy loss on shuffled model is particularly challenging. Hence we exploit the approximation on sum of lognormal distributions to derive the condition for the shuffled DPSGD to meet the DP guarantee. Auditing results show that our condition offers a DP guarantee quite close to the audited privacy level, demonstrating our approach an effective estimation in practice. Experimental results have verified our theoretical derivation and illustrate that our mechanism improves the accuracy of DPSGD over the state-of-the-art baselines on a variety of models and tasks.
Entity Alignment with Unlabeled Dangling Cases
Mar 16, 2024



We investigate the entity alignment problem with unlabeled dangling cases, meaning that there are entities in the source or target graph having no counterparts in the other, and those entities remain unlabeled. The problem arises when the source and target graphs are of different scales, and it is much cheaper to label the matchable pairs than the dangling entities. To solve the issue, we propose a novel GNN-based dangling detection and entity alignment framework. While the two tasks share the same GNN and are trained together, the detected dangling entities are removed in the alignment. Our framework is featured by a designed entity and relation attention mechanism for selective neighborhood aggregation in representation learning, as well as a positive-unlabeled learning loss for an unbiased estimation of dangling entities. Experimental results have shown that each component of our design contributes to the overall alignment performance which is comparable or superior to baselines, even if the baselines additionally have 30\% of the dangling entities labeled as training data.
Hufu: A Modality-Agnositc Watermarking System for Pre-Trained Transformers via Permutation Equivariance
Mar 09, 2024



With the blossom of deep learning models and services, it has become an imperative concern to safeguard the valuable model parameters from being stolen. Watermarking is considered an important tool for ownership verification. However, current watermarking schemes are customized for different models and tasks, hard to be integrated as an integrated intellectual protection service. We propose Hufu, a modality-agnostic watermarking system for pre-trained Transformer-based models, relying on the permutation equivariance property of Transformers. Hufu embeds watermark by fine-tuning the pre-trained model on a set of data samples specifically permuted, and the embedded model essentially contains two sets of weights -- one for normal use and the other for watermark extraction which is triggered on permuted inputs. The permutation equivariance ensures minimal interference between these two sets of model weights and thus high fidelity on downstream tasks. Since our method only depends on the model itself, it is naturally modality-agnostic, task-independent, and trigger-sample-free. Extensive experiments on the state-of-the-art vision Transformers, BERT, and GPT2 have demonstrated Hufu's superiority in meeting watermarking requirements including effectiveness, efficiency, fidelity, and robustness, showing its great potential to be deployed as a uniform ownership verification service for various Transformers.
AceMap: Knowledge Discovery through Academic Graph
Mar 05, 2024
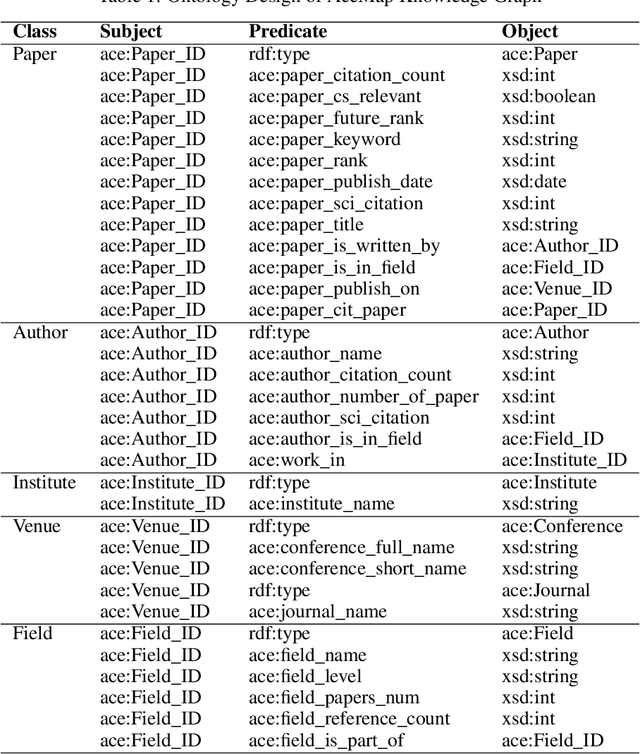
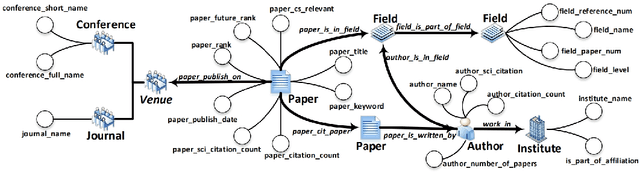
The exponential growth of scientific literature requires effective management and extraction of valuable insights. While existing scientific search engines excel at delivering search results based on relational databases, they often neglect the analysis of collaborations between scientific entities and the evolution of ideas, as well as the in-depth analysis of content within scientific publications. The representation of heterogeneous graphs and the effective measurement, analysis, and mining of such graphs pose significant challenges. To address these challenges, we present AceMap, an academic system designed for knowledge discovery through academic graph. We present advanced database construction techniques to build the comprehensive AceMap database with large-scale academic publications that contain rich visual, textual, and numerical information. AceMap also employs innovative visualization, quantification, and analysis methods to explore associations and logical relationships among academic entities. AceMap introduces large-scale academic network visualization techniques centered on nebular graphs, providing a comprehensive view of academic networks from multiple perspectives. In addition, AceMap proposes a unified metric based on structural entropy to quantitatively measure the knowledge content of different academic entities. Moreover, AceMap provides advanced analysis capabilities, including tracing the evolution of academic ideas through citation relationships and concept co-occurrence, and generating concise summaries informed by this evolutionary process. In addition, AceMap uses machine reading methods to generate potential new ideas at the intersection of different fields. Exploring the integration of large language models and knowledge graphs is a promising direction for future research in idea evolution. Please visit \url{https://www.acemap.info} for further exploration.
Crafter: Facial Feature Crafting against Inversion-based Identity Theft on Deep Models
Jan 14, 2024



With the increased capabilities at the edge (e.g., mobile device) and more stringent privacy requirement, it becomes a recent trend for deep learning-enabled applications to pre-process sensitive raw data at the edge and transmit the features to the backend cloud for further processing. A typical application is to run machine learning (ML) services on facial images collected from different individuals. To prevent identity theft, conventional methods commonly rely on an adversarial game-based approach to shed the identity information from the feature. However, such methods can not defend against adaptive attacks, in which an attacker takes a countermove against a known defence strategy. We propose Crafter, a feature crafting mechanism deployed at the edge, to protect the identity information from adaptive model inversion attacks while ensuring the ML tasks are properly carried out in the cloud. The key defence strategy is to mislead the attacker to a non-private prior from which the attacker gains little about the private identity. In this case, the crafted features act like poison training samples for attackers with adaptive model updates. Experimental results indicate that Crafter successfully defends both basic and possible adaptive attacks, which can not be achieved by state-of-the-art adversarial game-based methods.
Crossword: A Semantic Approach to Data Compression via Masking
Apr 03, 2023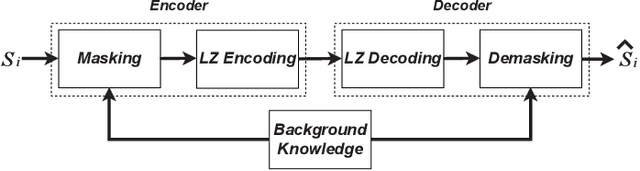
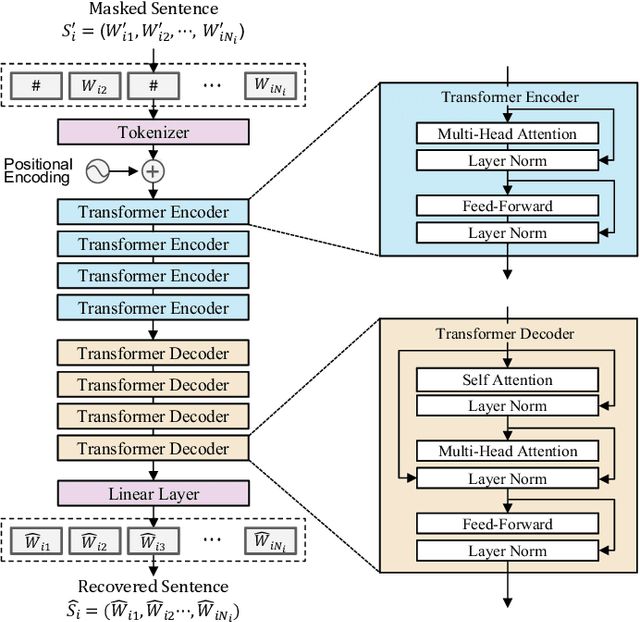
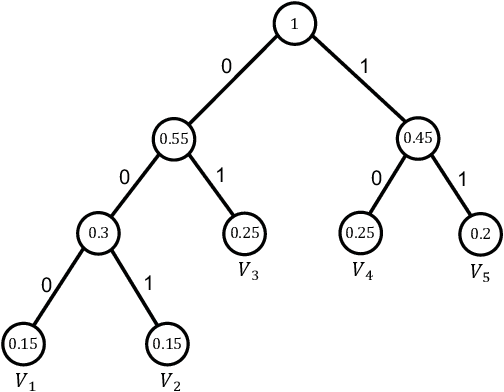
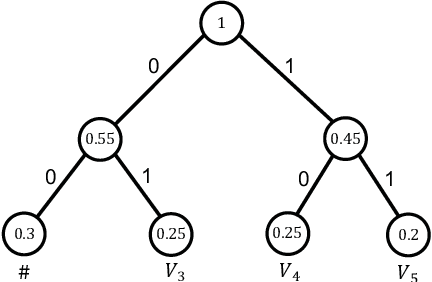
The traditional methods for data compression are typically based on the symbol-level statistics, with the information source modeled as a long sequence of i.i.d. random variables or a stochastic process, thus establishing the fundamental limit as entropy for lossless compression and as mutual information for lossy compression. However, the source (including text, music, and speech) in the real world is often statistically ill-defined because of its close connection to human perception, and thus the model-driven approach can be quite suboptimal. This study places careful emphasis on English text and exploits its semantic aspect to enhance the compression efficiency further. The main idea stems from the puzzle crossword, observing that the hidden words can still be precisely reconstructed so long as some key letters are provided. The proposed masking-based strategy resembles the above game. In a nutshell, the encoder evaluates the semantic importance of each word according to the semantic loss and then masks the minor ones, while the decoder aims to recover the masked words from the semantic context by means of the Transformer. Our experiments show that the proposed semantic approach can achieve much higher compression efficiency than the traditional methods such as Huffman code and UTF-8 code, while preserving the meaning in the target text to a great extent.
Decentralized Multi-AGV Task Allocation based on Multi-Agent Reinforcement Learning with Information Potential Field Rewards
Aug 16, 2021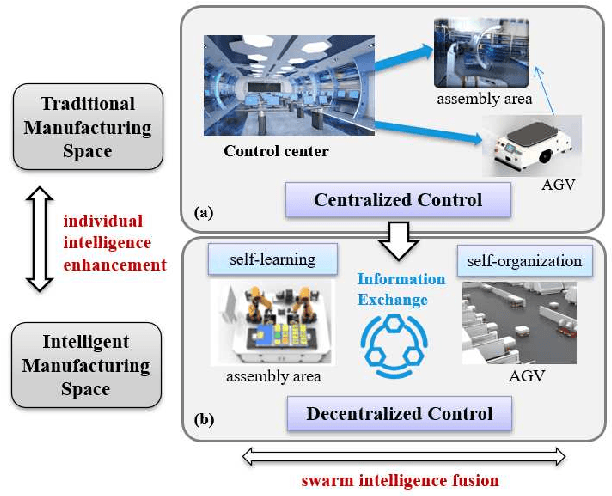
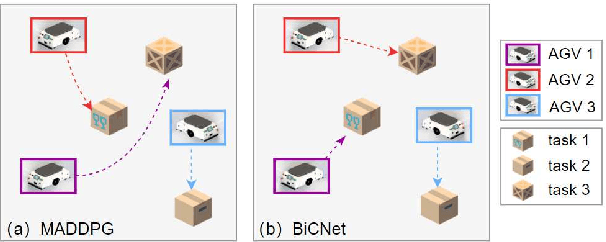
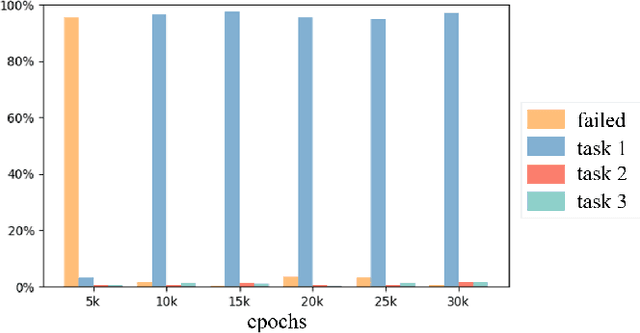
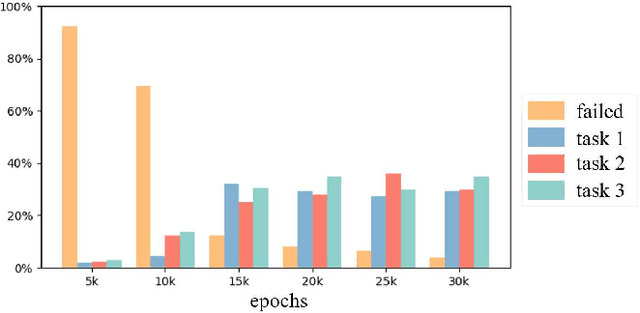
Automated Guided Vehicles (AGVs) have been widely used for material handling in flexible shop floors. Each product requires various raw materials to complete the assembly in production process. AGVs are used to realize the automatic handling of raw materials in different locations. Efficient AGVs task allocation strategy can reduce transportation costs and improve distribution efficiency. However, the traditional centralized approaches make high demands on the control center's computing power and real-time capability. In this paper, we present decentralized solutions to achieve flexible and self-organized AGVs task allocation. In particular, we propose two improved multi-agent reinforcement learning algorithms, MADDPG-IPF (Information Potential Field) and BiCNet-IPF, to realize the coordination among AGVs adapting to different scenarios. To address the reward-sparsity issue, we propose a reward shaping strategy based on information potential field, which provides stepwise rewards and implicitly guides the AGVs to different material targets. We conduct experiments under different settings (3 AGVs and 6 AGVs), and the experiment results indicate that, compared with baseline methods, our work obtains up to 47\% task response improvement and 22\% training iterations reduction.
Privacy Threats Analysis to Secure Federated Learning
Jun 24, 2021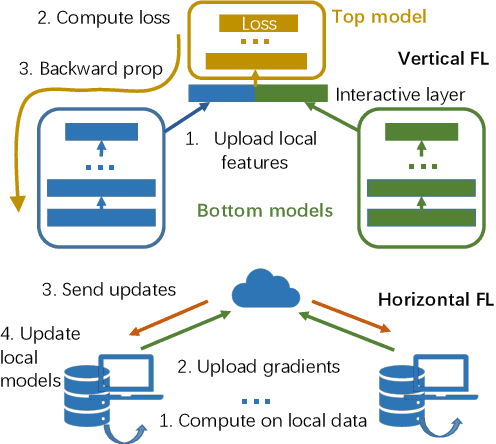
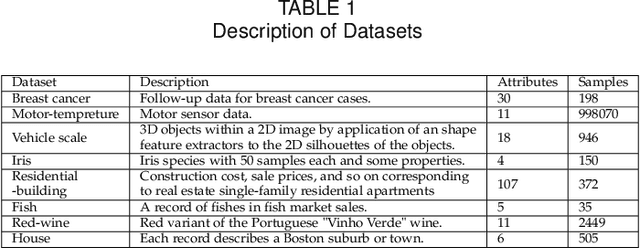
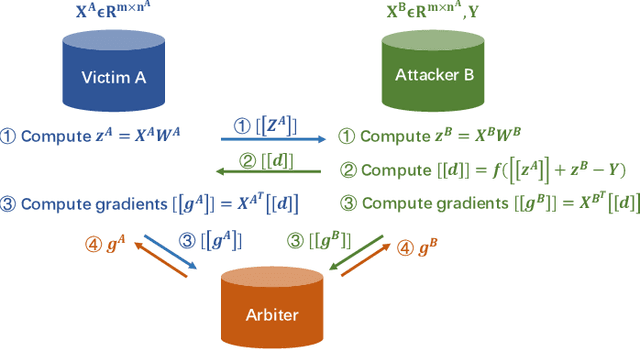
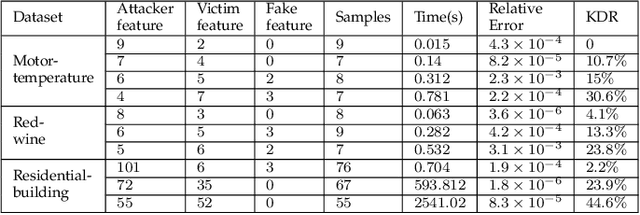
Federated learning is emerging as a machine learning technique that trains a model across multiple decentralized parties. It is renowned for preserving privacy as the data never leaves the computational devices, and recent approaches further enhance its privacy by hiding messages transferred in encryption. However, we found that despite the efforts, federated learning remains privacy-threatening, due to its interactive nature across different parties. In this paper, we analyze the privacy threats in industrial-level federated learning frameworks with secure computation, and reveal such threats widely exist in typical machine learning models such as linear regression, logistic regression and decision tree. For the linear and logistic regression, we show through theoretical analysis that it is possible for the attacker to invert the entire private input of the victim, given very few information. For the decision tree model, we launch an attack to infer the range of victim's private inputs. All attacks are evaluated on popular federated learning frameworks and real-world datasets.