 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
FastBEV++: Fast by Algorithm, Deployable by Design
Dec 09, 2025The advancement of camera-only Bird's-Eye-View(BEV) perception is currently impeded by a fundamental tension between state-of-the-art performance and on-vehicle deployment tractability. This bottleneck stems from a deep-rooted dependency on computationally prohibitive view transformations and bespoke, platform-specific kernels. This paper introduces FastBEV++, a framework engineered to reconcile this tension, demonstrating that high performance and deployment efficiency can be achieved in unison via two guiding principles: Fast by Algorithm and Deployable by Design. We realize the "Deployable by Design" principle through a novel view transformation paradigm that decomposes the monolithic projection into a standard Index-Gather-Reshape pipeline. Enabled by a deterministic pre-sorting strategy, this transformation is executed entirely with elementary, operator native primitives (e.g Gather, Matrix Multiplication), which eliminates the need for specialized CUDA kernels and ensures fully TensorRT-native portability. Concurrently, our framework is "Fast by Algorithm", leveraging this decomposed structure to seamlessly integrate an end-to-end, depth-aware fusion mechanism. This jointly learned depth modulation, further bolstered by temporal aggregation and robust data augmentation, significantly enhances the geometric fidelity of the BEV representation.Empirical validation on the nuScenes benchmark corroborates the efficacy of our approach. FastBEV++ establishes a new state-of-the-art 0.359 NDS while maintaining exceptional real-time performance, exceeding 134 FPS on automotive-grade hardware (e.g Tesla T4). By offering a solution that is free of custom plugins yet highly accurate, FastBEV++ presents a mature and scalable design philosophy for production autonomous systems. The code is released at: https://github.com/ymlab/advanced-fastbev
AI-Driven Segmentation and Analysis of Microbial Cells
May 05, 2025



Studying the growth and metabolism of microbes provides critical insights into their evolutionary adaptations to harsh environments, which are essential for microbial research and biotechnology applications. In this study, we developed an AI-driven image analysis system to efficiently segment individual cells and quantitatively analyze key cellular features. This system is comprised of four main modules. First, a denoising algorithm enhances contrast and suppresses noise while preserving fine cellular details. Second, the Segment Anything Model (SAM) enables accurate, zero-shot segmentation of cells without additional training. Third, post-processing is applied to refine segmentation results by removing over-segmented masks. Finally, quantitative analysis algorithms extract essential cellular features, including average intensity, length, width, and volume. The results show that denoising and post-processing significantly improved the segmentation accuracy of SAM in this new domain. Without human annotations, the AI-driven pipeline automatically and efficiently outlines cellular boundaries, indexes them, and calculates key cellular parameters with high accuracy. This framework will enable efficient and automated quantitative analysis of high-resolution fluorescence microscopy images to advance research into microbial adaptations to grow and metabolism that allow extremophiles to thrive in their harsh habitats.
AI-Driven High-Resolution Cell Segmentation and Quantitative Analysis
May 01, 2025Studying the growth and metabolism of microbes provides critical insights into their evolutionary adaptations to harsh environments, which are essential for microbial research and biotechnology applications. In this study, we developed an AI-driven image analysis system to efficiently segment individual cells and quantitatively analyze key cellular features. This system is comprised of four main modules. First, a denoising algorithm enhances contrast and suppresses noise while preserving fine cellular details. Second, the Segment Anything Model (SAM) enables accurate, zero-shot segmentation of cells without additional training. Third, post-processing is applied to refine segmentation results by removing over-segmented masks. Finally, quantitative analysis algorithms extract essential cellular features, including average intensity, length, width, and volume. The results show that denoising and post-processing significantly improved the segmentation accuracy of SAM in this new domain. Without human annotations, the AI-driven pipeline automatically and efficiently outlines cellular boundaries, indexes them, and calculates key cellular parameters with high accuracy. This framework will enable efficient and automated quantitative analysis of high-resolution fluorescence microscopy images to advance research into microbial adaptations to grow and metabolism that allow extremophiles to thrive in their harsh habitats.
From Pairwise to Ranking: Climbing the Ladder to Ideal Collaborative Filtering with Pseudo-Ranking
Dec 24, 2024



Intuitively, an ideal collaborative filtering (CF) model should learn from users' full rankings over all items to make optimal top-K recommendations. Due to the absence of such full rankings in practice, most CF models rely on pairwise loss functions to approximate full rankings, resulting in an immense performance gap. In this paper, we provide a novel analysis using the multiple ordinal classification concept to reveal the inevitable gap between a pairwise approximation and the ideal case. However, bridging the gap in practice encounters two formidable challenges: (1) none of the real-world datasets contains full ranking information; (2) there does not exist a loss function that is capable of consuming ranking information. To overcome these challenges, we propose a pseudo-ranking paradigm (PRP) that addresses the lack of ranking information by introducing pseudo-rankings supervised by an original noise injection mechanism. Additionally, we put forward a new ranking loss function designed to handle ranking information effectively. To ensure our method's robustness against potential inaccuracies in pseudo-rankings, we equip the ranking loss function with a gradient-based confidence mechanism to detect and mitigate abnormal gradients. Extensive experiments on four real-world datasets demonstrate that PRP significantly outperforms state-of-the-art methods.
AI-driven emergence of frequency information non-uniform distribution via THz metasurface spectrum prediction
Dec 05, 2023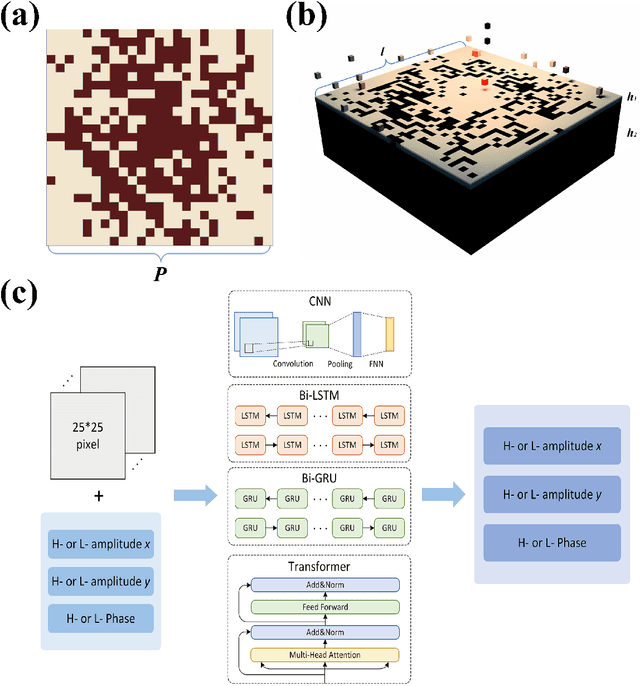
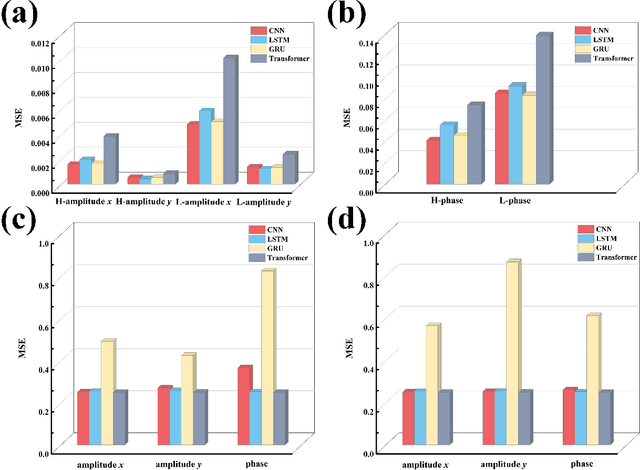
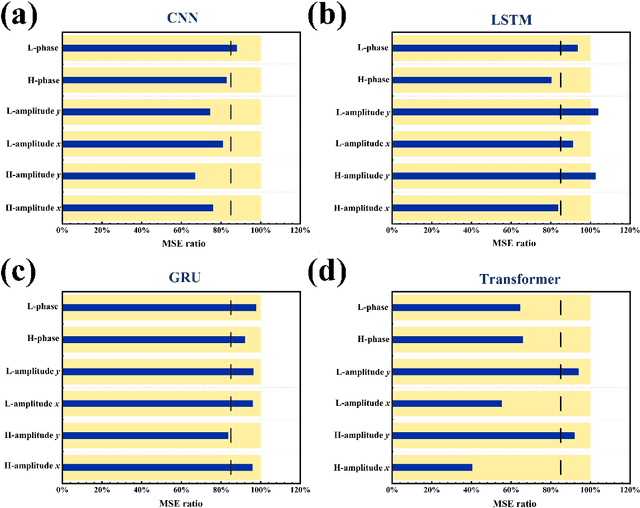
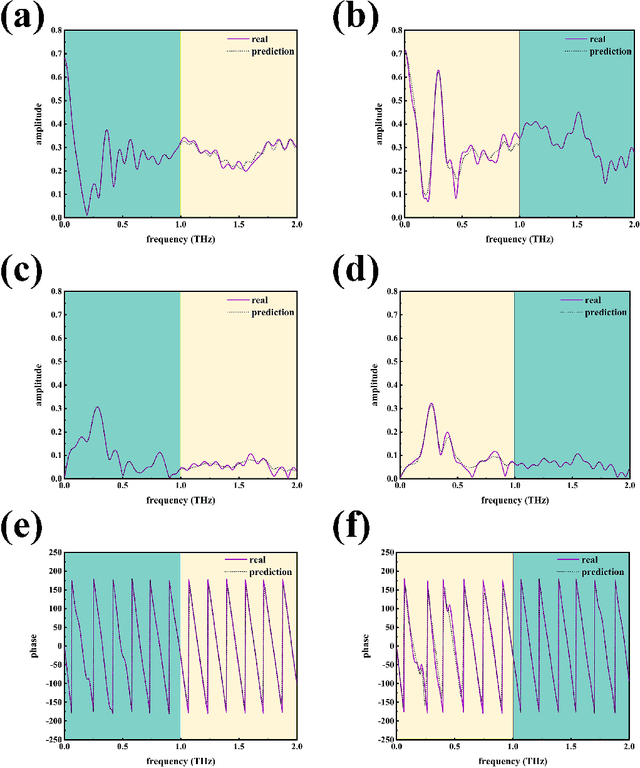
Recently, artificial intelligence has been extensively deployed across various scientific disciplines, optimizing and guiding the progression of experiments through the integration of abundant datasets, whilst continuously probing the vast theoretical space encapsulated within the data. Particularly, deep learning models, due to their end-to-end adaptive learning capabilities, are capable of autonomously learning intrinsic data features, thereby transcending the limitations of traditional experience to a certain extent. Here, we unveil previously unreported information characteristics pertaining to different frequencies emerged during our work on predicting the terahertz spectral modulation effects of metasurfaces based on AI-prediction. Moreover, we have substantiated that our proposed methodology of simply adding supplementary multi-frequency inputs to the existing dataset during the target spectral prediction process can significantly enhance the predictive accuracy of the network. This approach effectively optimizes the utilization of existing datasets and paves the way for interdisciplinary research and applications in artificial intelligence, chemistry, composite material design, biomedicine, and other fields.
MLatom 3: Platform for machine learning-enhanced computational chemistry simulations and workflows
Oct 31, 2023
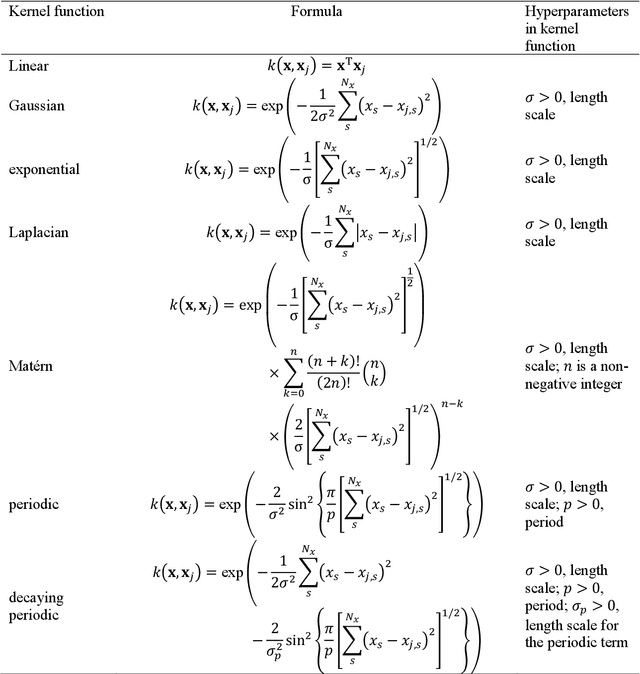
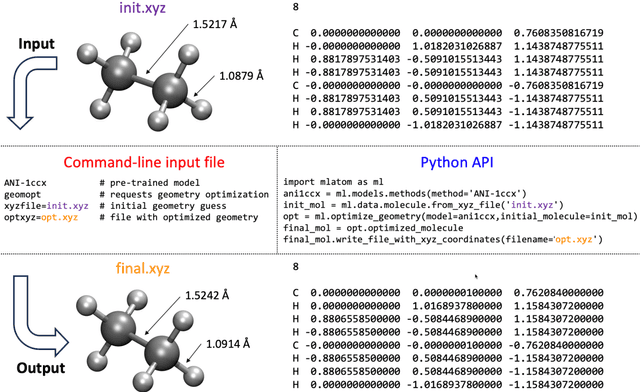
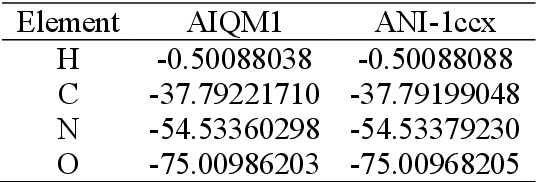
Machine learning (ML) is increasingly becoming a common tool in computational chemistry. At the same time, the rapid development of ML methods requires a flexible software framework for designing custom workflows. MLatom 3 is a program package designed to leverage the power of ML to enhance typical computational chemistry simulations and to create complex workflows. This open-source package provides plenty of choice to the users who can run simulations with the command line options, input files, or with scripts using MLatom as a Python package, both on their computers and on the online XACS cloud computing at XACScloud.com. Computational chemists can calculate energies and thermochemical properties, optimize geometries, run molecular and quantum dynamics, and simulate (ro)vibrational, one-photon UV/vis absorption, and two-photon absorption spectra with ML, quantum mechanical, and combined models. The users can choose from an extensive library of methods containing pre-trained ML models and quantum mechanical approximations such as AIQM1 approaching coupled-cluster accuracy. The developers can build their own models using various ML algorithms. The great flexibility of MLatom is largely due to the extensive use of the interfaces to many state-of-the-art software packages and libraries.
Joint Beamforming Optimization for Active STAR-RIS Assisted ISAC systems
Aug 11, 2023



In this paper, we investigate an active simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) assisted integrated sensing and communications (ISAC) system, in which a dual-function base station (DFBS) equipped with multiple antennas provides communication services for multiple users with the assistance of an active STARRIS and performs target sensing simultaneously. Through optimizing both the DFBS and STAR-RIS beamforming jointly under different work modes, our purpose is to achieve the maximized communication sum rate, subject to the minimum radar signal-to-noise ratio (SNR) constraint, active STAR-RIS hardware constraints, and total power constraint of DFBS and active STAR-RIS. To solve the non-convex optimization problem formulated, an efficient alternating optimization algorithm is proposed. Specifically, the fractional programming scheme is first leveraged to turn the original problem into a structure with more tractable, and subsequently the transformed problem is decomposed into multiple sub-problems. Next, we develop a derivation method to obtain the closed expression of the radar receiving beamforming, and then the DFBS transmit beamforming is optimized under the radar SNR requirement and total power constraint. After that, the active STAR-RIS reflection and transmission beamforming are optimized by majorization minimiation, complex circle manifold and convex optimization techniques. Finally, the proposed schemes are conducted through numerical simulations to show their benefits and efficiency.
The RoboDepth Challenge: Methods and Advancements Towards Robust Depth Estimation
Jul 27, 2023



Accurate depth estimation under out-of-distribution (OoD) scenarios, such as adverse weather conditions, sensor failure, and noise contamination, is desirable for safety-critical applications. Existing depth estimation systems, however, suffer inevitably from real-world corruptions and perturbations and are struggled to provide reliable depth predictions under such cases. In this paper, we summarize the winning solutions from the RoboDepth Challenge -- an academic competition designed to facilitate and advance robust OoD depth estimation. This challenge was developed based on the newly established KITTI-C and NYUDepth2-C benchmarks. We hosted two stand-alone tracks, with an emphasis on robust self-supervised and robust fully-supervised depth estimation, respectively. Out of more than two hundred participants, nine unique and top-performing solutions have appeared, with novel designs ranging from the following aspects: spatial- and frequency-domain augmentations, masked image modeling, image restoration and super-resolution, adversarial training, diffusion-based noise suppression, vision-language pre-training, learned model ensembling, and hierarchical feature enhancement. Extensive experimental analyses along with insightful observations are drawn to better understand the rationale behind each design. We hope this challenge could lay a solid foundation for future research on robust and reliable depth estimation and beyond. The datasets, competition toolkit, workshop recordings, and source code from the winning teams are publicly available on the challenge website.
Improvements in Micro-CT Method for Characterizing X-ray Monocapillary Optics
Jun 28, 2021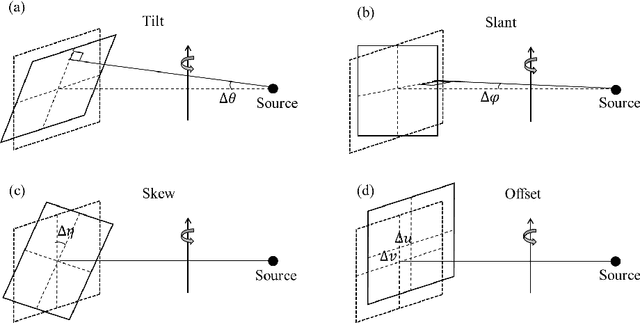
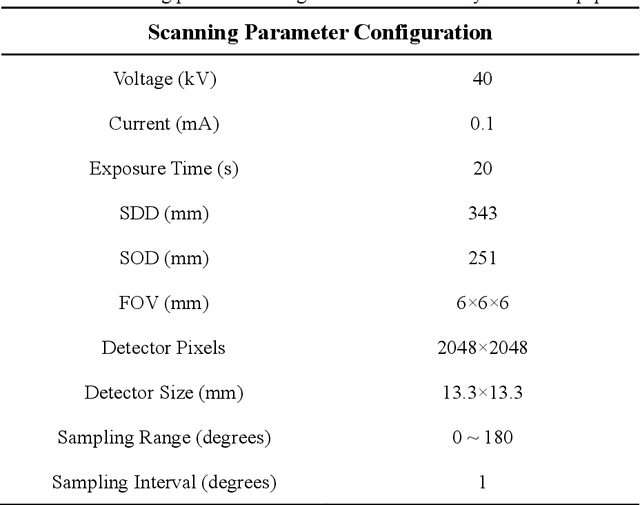
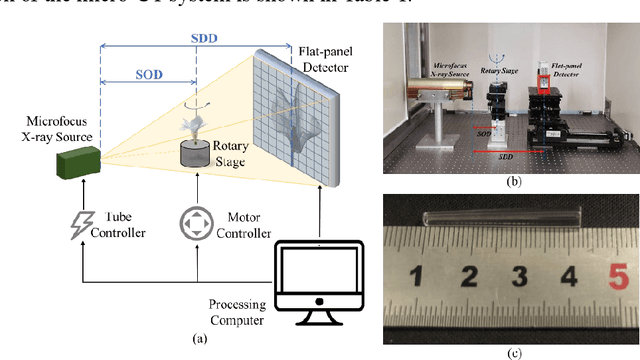

Accurate characterization of the inner surface of X-ray monocapillary optics (XMCO) is of great significance in X-ray optics research. Compared with other characterization methods, the micro computed tomography (micro-CT) method has its unique advantages but also has some disadvantages, such as a long scanning time, long image reconstruction time, and inconvenient scanning process. In this paper, sparse sampling was proposed to shorten the scanning time, GPU acceleration technology was used to improve the speed of image reconstruction, and a simple geometric calibration algorithm was proposed to avoid the calibration phantom and simplify the scanning process. These methodologies will popularize the use of the micro-CT method in XMCO characterization.