 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pairwise to Ranking: Climbing the Ladder to Ideal Collaborative Filtering with Pseudo-Ranking
Dec 24, 2024



Intuitively, an ideal collaborative filtering (CF) model should learn from users' full rankings over all items to make optimal top-K recommendations. Due to the absence of such full rankings in practice, most CF models rely on pairwise loss functions to approximate full rankings, resulting in an immense performance gap. In this paper, we provide a novel analysis using the multiple ordinal classification concept to reveal the inevitable gap between a pairwise approximation and the ideal case. However, bridging the gap in practice encounters two formidable challenges: (1) none of the real-world datasets contains full ranking information; (2) there does not exist a loss function that is capable of consuming ranking information. To overcome these challenges, we propose a pseudo-ranking paradigm (PRP) that addresses the lack of ranking information by introducing pseudo-rankings supervised by an original noise injection mechanism. Additionally, we put forward a new ranking loss function designed to handle ranking information effectively. To ensure our method's robustness against potential inaccuracies in pseudo-rankings, we equip the ranking loss function with a gradient-based confidence mechanism to detect and mitigate abnormal gradients. Extensive experiments on four real-world datasets demonstrate that PRP significantly outperforms state-of-the-art methods.
Unlocking the Hidden Treasures: Enhancing Recommendations with Unlabeled Data
Dec 24, 2024



Collaborative filtering (CF) stands as a cornerstone in recommender systems, yet effectively leveraging the massive unlabeled data presents a significant challenge. Current research focuses on addressing the challenge of unlabeled data by extracting a subset that closely approximates negative samples. Regrettably, the remaining data are overlooked, failing to fully integrate this valuable information into the construction of user preferences. To address this gap, we introduce a novel positive-neutral-negative (PNN) learning paradigm. PNN introduces a neutral class, encompassing intricate items that are challenging to categorize directly as positive or negative samples. By training a model based on this triple-wise partial ranking, PNN offers a promising solution to learning complex user preferences. Through theoretical analysis, we connect PNN to one-way partial AUC (OPAUC) to validate its efficacy. Implementing the PNN paradigm is, however, technically challenging because: (1) it is difficult to classify unlabeled data into neutral or negative in the absence of supervised signals; (2) there does not exist any loss function that can handle set-level triple-wise ranking relationships. To address these challenges, we propose a semi-supervised learning method coupled with a user-aware attention model for knowledge acquisition and classification refinement. Additionally, a novel loss function with a two-step centroid ranking approach enables handling set-level rankings. Extensive experiments on four real-world datasets demonstrate that, when combined with PNN, a wide range of representative CF models can consistently and significantly boost their performance. Even with a simple matrix factorization, PNN can achieve comparable performance to sophisticated graph neutral networks.
SSDRec: Self-Augmented Sequence Denoising for Sequential Recommendation
Mar 07, 2024Traditional sequential recommendation methods assume that users' sequence data is clean enough to learn accurate sequence representations to reflect user preferences. In practice, users' sequences inevitably contain noise (e.g., accidental interactions), leading to incorrect reflections of user preferences. Consequently, some pioneer studies have explored modeling sequentiality and correlations in sequences to implicitly or explicitly reduce noise's influence. However, relying on only available intra-sequence information (i.e., sequentiality and correlations in a sequence) is insufficient and may result in over-denoising and under-denoising problems (OUPs), especially for short sequences. To improve reliability, we propose to augment sequences by inserting items before denoising. However, due to the data sparsity issue and computational costs, it is challenging to select proper items from the entire item universe to insert into proper positions in a target sequence. Motivated by the above observation, we propose a novel framework--Self-augmented Sequence Denoising for sequential Recommendation (SSDRec) with a three-stage learning paradigm to solve the above challenges. In the first stage, we empower SSDRec by a global relation encoder to learn multi-faceted inter-sequence relations in a data-driven manner. These relations serve as prior knowledge to guide subsequent stages. In the second stage, we devise a self-augmentation module to augment sequences to alleviate OUPs. Finally, we employ a hierarchical denoising module in the third stage to reduce the risk of false augmentations and pinpoint all noise in raw sequences. Extensive experiments on five real-world datasets demonstrate the superiority of \model over state-of-the-art denoising methods and its flexible applications to mainstream sequential recommendation models. The source code is available at https://github.com/zc-97/SSDRec.
Augmented Negative Sampling for Collaborative Filtering
Aug 11, 2023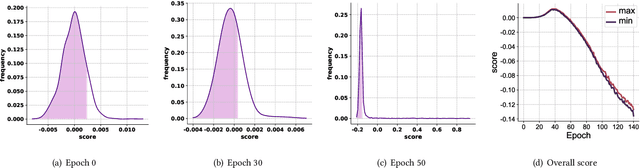
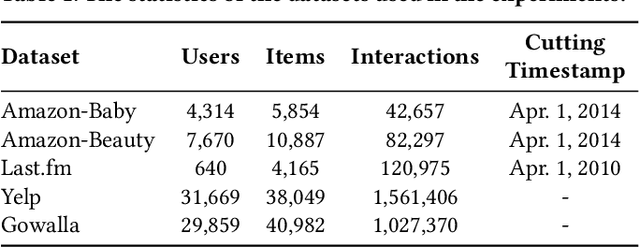
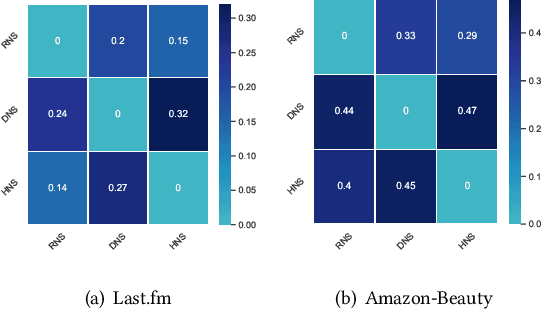
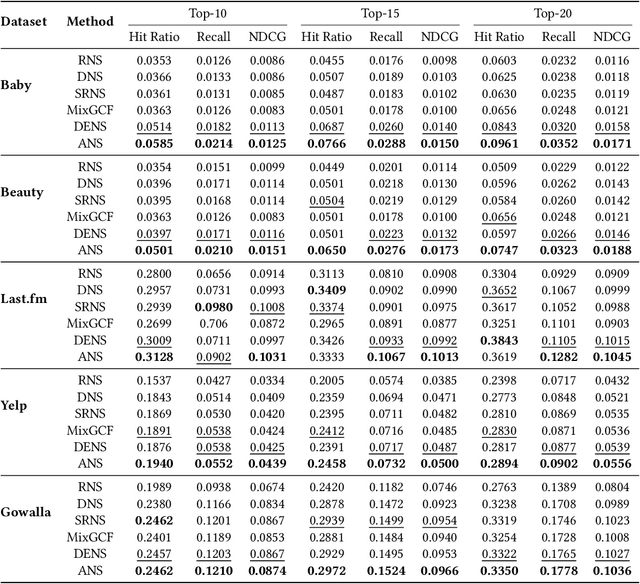
Negative sampling is essential for implicit-feedback-based collaborative filtering, which is used to constitute negative signals from massive unlabeled data to guide supervised learning. The state-of-the-art idea is to utilize hard negative samples that carry more useful information to form a better decision boundary. To balance efficiency and effectiveness, the vast majority of existing methods follow the two-pass approach, in which the first pass samples a fixed number of unobserved items by a simple static distribution and then the second pass selects the final negative items using a more sophisticated negative sampling strategy. However, selecting negative samples from the original items is inherently restricted, and thus may not be able to contrast positive samples well. In this paper, we confirm this observation via experiments and introduce two limitations of existing solutions: ambiguous trap and information discrimination. Our response to such limitations is to introduce augmented negative samples. This direction renders a substantial technical challenge because constructing unconstrained negative samples may introduce excessive noise that distorts the decision boundary. To this end, we introduce a novel generic augmented negative sampling paradigm and provide a concrete instantiation. First, we disentangle hard and easy factors of negative items. Next, we generate new candidate negative samples by augmenting only the easy factors in a regulated manner: the direction and magnitude of the augmentation are carefully calibrated. Finally, we design an advanced negative sampling strategy to identify the final augmented negative samples, which considers not only the score function used in existing methods but also a new metric called augmentation gain. Extensive experiments on real-world datasets demonstrate that our method significantly outperforms state-of-the-art baselines.