 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatryoshka Representation Learning for Recommendation
Jun 11, 2024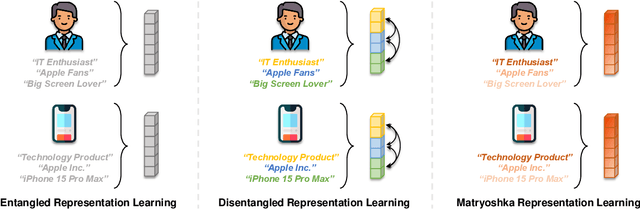
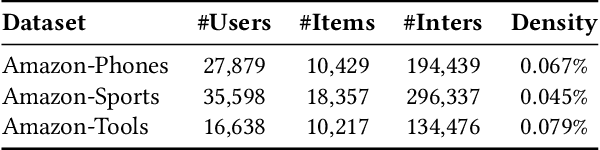
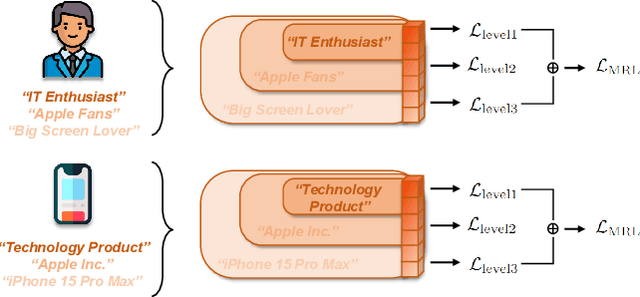
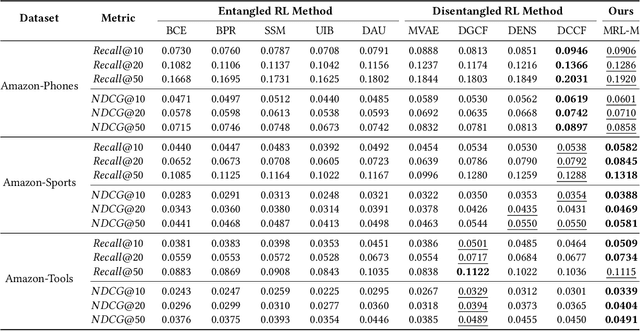
Representation learning is essential for deep-neural-network-based recommender systems to capture user preferences and item features within fixed-dimensional user and item vectors. Unlike existing representation learning methods that either treat each user preference and item feature uniformly or categorize them into discrete clusters, we argue that in the real world, user preferences and item features are naturally expressed and organized in a hierarchical manner, leading to a new direction for representation learning. In this paper, we introduce a novel matryoshka representation learning method for recommendation (MRL4Rec), by which we restructure user and item vectors into matryoshka representations with incrementally dimensional and overlapping vector spaces to explicitly represent user preferences and item features at different hierarchical levels. We theoretically establish that constructing training triplets specific to each level is pivotal in guaranteeing accurate matryoshka representation learning. Subsequently, we propose the matryoshka negative sampling mechanism to construct training triplets, which further ensures the effectiveness of the matryoshka representation learning in capturing hierarchical user preferences and item features. The experiments demonstrate that MRL4Rec can consistently and substantially outperform a number of state-of-the-art competitors on several real-life datasets. Our code is publicly available at https://github.com/Riwei-HEU/MRL.
A Survey on Data-Centric Recommender Systems
Feb 02, 2024
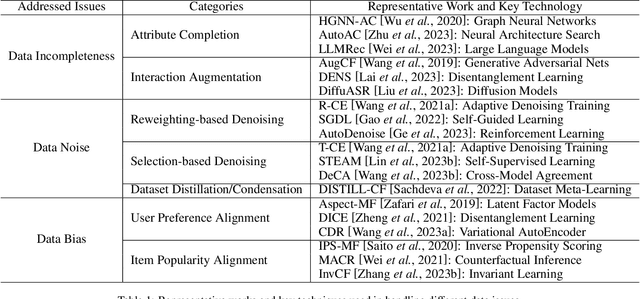
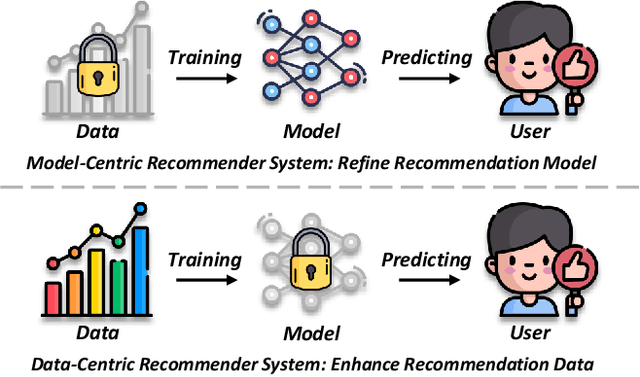
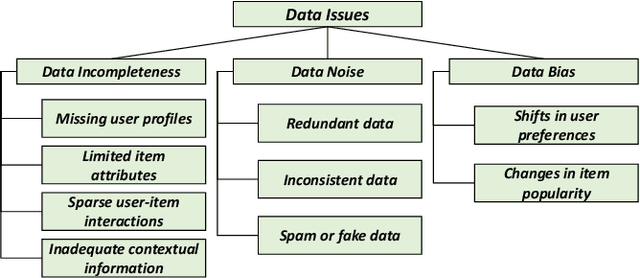
Recommender systems (RSs) have become an essential tool for mitigating information overload in a range of real-world applications. Recent trends in RSs have revealed a major paradigm shift, moving the spotlight from model-centric innovations to data-centric efforts (e.g., improving data quality and quantity). This evolution has given rise to the concept of data-centric recommender systems (Data-Centric RSs), marking a significant development in the field. This survey provides the first systematic overview of Data-Centric RSs, covering 1) the foundational concepts of recommendation data and Data-Centric RSs; 2) three primary issues of recommendation data; 3) recent research developed to address these issues; and 4) several potential future directions of Data-Centric RSs.
Adaptive Hardness Negative Sampling for Collaborative Filtering
Jan 10, 2024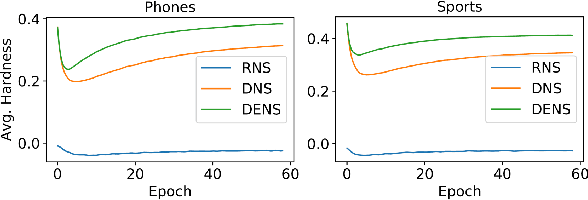
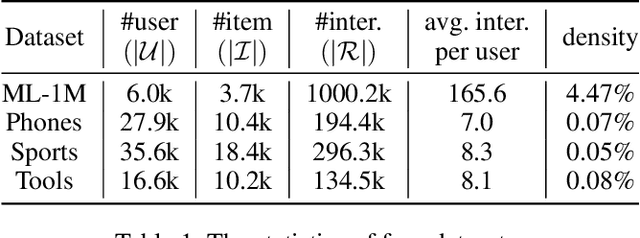
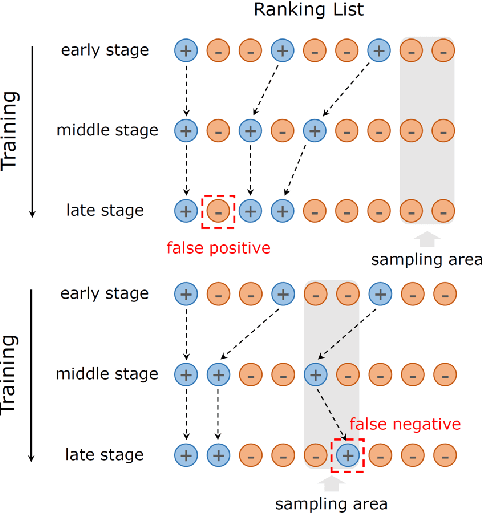
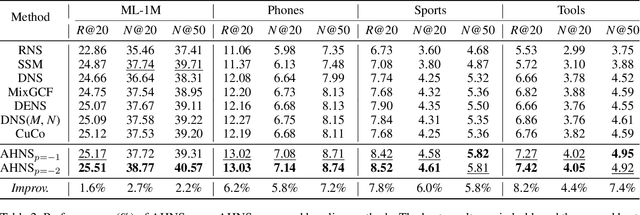
Negative sampling is essential for implicit collaborative filtering to provide proper negative training signals so as to achieve desirable performance. We experimentally unveil a common limitation of all existing negative sampling methods that they can only select negative samples of a fixed hardness level, leading to the false positive problem (FPP) and false negative problem (FNP). We then propose a new paradigm called adaptive hardness negative sampling (AHNS) and discuss its three key criteria. By adaptively selecting negative samples with appropriate hardnesses during the training process, AHNS can well mitigate the impacts of FPP and FNP. Next, we present a concrete instantiation of AHNS called AHNS_{p<0}, and theoretically demonstrate that AHNS_{p<0} can fit the three criteria of AHNS well and achieve a larger lower bound of normalized discounted cumulative gain. Besides, we note that existing negative sampling methods can be regarded as more relaxed cases of AHNS. Finally, we conduct comprehensive experiments, and the results show that AHNS_{p<0} can consistently and substantially outperform several state-of-the-art competitors on multiple datasets.
Augmented Negative Sampling for Collaborative Filtering
Aug 11, 2023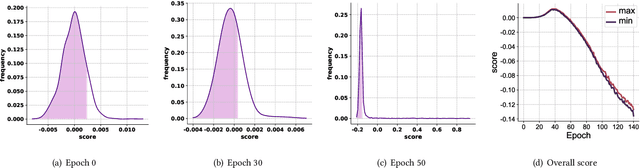
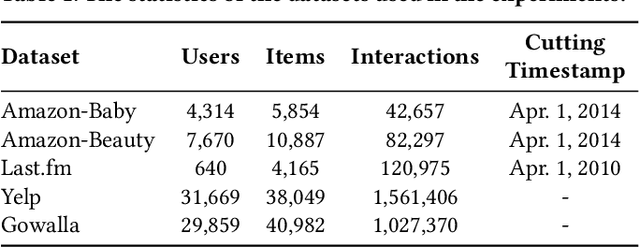
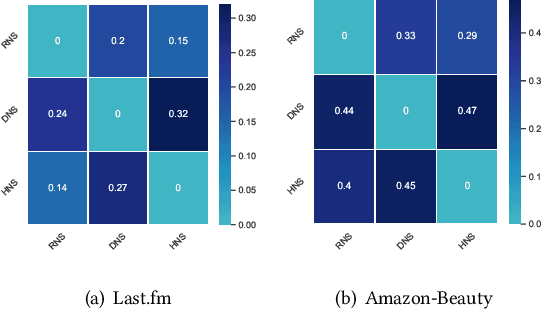
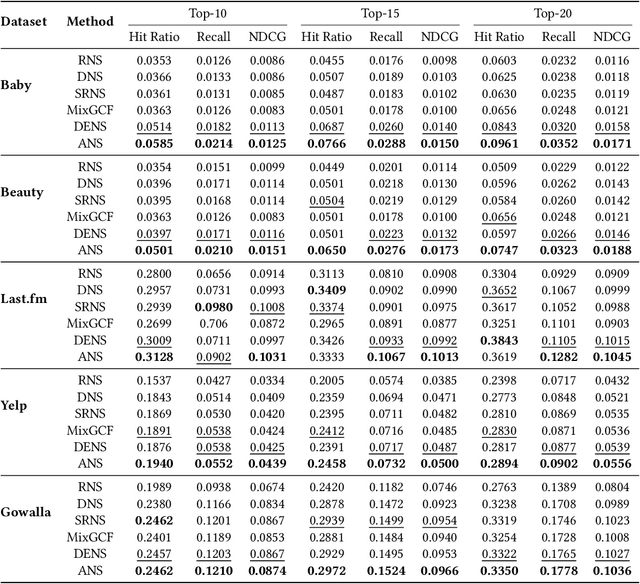
Negative sampling is essential for implicit-feedback-based collaborative filtering, which is used to constitute negative signals from massive unlabeled data to guide supervised learning. The state-of-the-art idea is to utilize hard negative samples that carry more useful information to form a better decision boundary. To balance efficiency and effectiveness, the vast majority of existing methods follow the two-pass approach, in which the first pass samples a fixed number of unobserved items by a simple static distribution and then the second pass selects the final negative items using a more sophisticated negative sampling strategy. However, selecting negative samples from the original items is inherently restricted, and thus may not be able to contrast positive samples well. In this paper, we confirm this observation via experiments and introduce two limitations of existing solutions: ambiguous trap and information discrimination. Our response to such limitations is to introduce augmented negative samples. This direction renders a substantial technical challenge because constructing unconstrained negative samples may introduce excessive noise that distorts the decision boundary. To this end, we introduce a novel generic augmented negative sampling paradigm and provide a concrete instantiation. First, we disentangle hard and easy factors of negative items. Next, we generate new candidate negative samples by augmenting only the easy factors in a regulated manner: the direction and magnitude of the augmentation are carefully calibrated. Finally, we design an advanced negative sampling strategy to identify the final augmented negative samples, which considers not only the score function used in existing methods but also a new metric called augmentation gain. Extensive experiments on real-world datasets demonstrate that our method significantly outperforms state-of-the-art baselines.