 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan VLMs Reason Robustly? A Neuro-Symbolic Investigation
Mar 25, 2026Vision-Language Models (VLMs) have been applied to a wide range of reasoning tasks, yet it remains unclear whether they can reason robustly under distribution shifts. In this paper, we study covariate shifts in which the perceptual input distribution changes while the underlying prediction rules do not. To investigate this question, we consider visual deductive reasoning tasks, where a model is required to answer a query given an image and logical rules defined over the object concepts in the image. Empirically, we find that VLMs fine-tuned through gradient-based end-to-end training can achieve high in-distribution accuracy but fail to generalize under such shifts, suggesting that fine-tuning does not reliably induce the underlying reasoning function. This motivates a neuro-symbolic perspective that decouples perception from reasoning. However, we further observe that recent neuro-symbolic approaches that rely on black-box components for reasoning can still exhibit inconsistent robustness across tasks. To address this issue, we propose VLC, a neuro-symbolic method that combines VLM-based concept recognition with circuit-based symbolic reasoning. In particular, task rules are compiled into a symbolic program, specifically a circuit, which executes the rules exactly over the object concepts recognized by the VLM. Experiments on three visual deductive reasoning tasks with distinct rule sets show that VLC consistently achieves strong performance under covariate shifts, highlighting its ability to support robust reasoning.
Causal Neural Probabilistic Circuits
Mar 02, 2026Concept Bottleneck Models (CBMs) enhance the interpretability of end-to-end neural networks by introducing a layer of concepts and predicting the class label from the concept predictions. A key property of CBMs is that they support interventions, i.e., domain experts can correct mispredicted concept values at test time to improve the final accuracy. However, typical CBMs apply interventions by overwriting only the corrected concept while leaving other concept predictions unchanged, which ignores causal dependencies among concepts. To address this, we propose the Causal Neural Probabilistic Circuit (CNPC), which combines a neural attribute predictor with a causal probabilistic circuit compiled from a causal graph. This circuit supports exact, tractable causal inference that inherently respects causal dependencies. Under interventions, CNPC models the class distribution based on a Product of Experts (PoE) that fuses the attribute predictor's predictive distribution with the interventional marginals computed by the circuit. We theoretically characterize the compositional interventional error of CNPC w.r.t. its modules and identify conditions under which CNPC closely matches the ground-truth interventional class distribution. Experiments on five benchmark datasets in both in-distribution and out-of-distribution settings show that, compared with five baseline models, CNPC achieves higher task accuracy across different numbers of intervened attributes.
The Double-Edged Sword of Knowledge Transfer: Diagnosing and Curing Fairness Pathologies in Cross-Domain Recommendation
Jan 29, 2026Cross-domain recommendation (CDR) offers an effective strategy for improving recommendation quality in a target domain by leveraging auxiliary signals from source domains. Nonetheless, emerging evidence shows that CDR can inadvertently heighten group-level unfairness. In this work, we conduct a comprehensive theoretical and empirical analysis to uncover why these fairness issues arise. Specifically, we identify two key challenges: (i) Cross-Domain Disparity Transfer, wherein existing group-level disparities in the source domain are systematically propagated to the target domain; and (ii) Unfairness from Cross-Domain Information Gain, where the benefits derived from cross-domain knowledge are unevenly allocated among distinct groups. To address these two challenges, we propose a Cross-Domain Fairness Augmentation (CDFA) framework composed of two key components. Firstly, it mitigates cross-domain disparity transfer by adaptively integrating unlabeled data to equilibrate the informativeness of training signals across groups. Secondly, it redistributes cross-domain information gains via an information-theoretic approach to ensure equitable benefit allocation across groups. Extensive experiments on multiple datasets and baselines demonstrate that our framework significantly reduces unfairness in CDR without sacrificing overall recommendation performance, while even enhancing it.
Post-Training Fairness Control: A Single-Train Framework for Dynamic Fairness in Recommendation
Jan 28, 2026Despite growing efforts to mitigate unfairness in recommender systems, existing fairness-aware methods typically fix the fairness requirement at training time and provide limited post-training flexibility. However, in real-world scenarios, diverse stakeholders may demand differing fairness requirements over time, so retraining for different fairness requirements becomes prohibitive. To address this limitation, we propose Cofair, a single-train framework that enables post-training fairness control in recommendation. Specifically, Cofair introduces a shared representation layer with fairness-conditioned adapter modules to produce user embeddings specialized for varied fairness levels, along with a user-level regularization term that guarantees user-wise monotonic fairness improvements across these levels. We theoretically establish that the adversarial objective of Cofair upper bounds demographic parity and the regularization term enforces progressive fairness at user level. Comprehensive experiments on multiple datasets and backbone models demonstrate that our framework provides dynamic fairness at different levels, delivering comparable or better fairness-accuracy curves than state-of-the-art baselines, without the need to retrain for each new fairness requirement. Our code is publicly available at https://github.com/weixinchen98/Cofair.
MemRec: Collaborative Memory-Augmented Agentic Recommender System
Jan 13, 2026The evolution of recommender systems has shifted preference storage from rating matrices and dense embeddings to semantic memory in the agentic era. Yet existing agents rely on isolated memory, overlooking crucial collaborative signals. Bridging this gap is hindered by the dual challenges of distilling vast graph contexts without overwhelming reasoning agents with cognitive load, and evolving the collaborative memory efficiently without incurring prohibitive computational costs. To address this, we propose MemRec, a framework that architecturally decouples reasoning from memory management to enable efficient collaborative augmentation. MemRec introduces a dedicated, cost-effective LM_Mem to manage a dynamic collaborative memory graph, serving synthesized, high-signal context to a downstream LLM_Rec. The framework operates via a practical pipeline featuring efficient retrieval and cost-effective asynchronous graph propagation that evolves memory in the background. Extensive experiments on four benchmarks demonstrate that MemRec achieves state-of-the-art performance. Furthermore, architectural analysis confirms its flexibility, establishing a new Pareto frontier that balances reasoning quality, cost, and privacy through support for diverse deployments, including local open-source models. Code:https://github.com/rutgerswiselab/memrec and Homepage: https://memrec.weixinchen.com
Leave No One Behind: Fairness-Aware Cross-Domain Recommender Systems for Non-Overlapping Users
Jul 23, 2025Cross-domain recommendation (CDR) methods predominantly leverage overlapping users to transfer knowledge from a source domain to a target domain. However, through empirical studies, we uncover a critical bias inherent in these approaches: while overlapping users experience significant enhancements in recommendation quality, non-overlapping users benefit minimally and even face performance degradation. This unfairness may erode user trust, and, consequently, negatively impact business engagement and revenue. To address this issue, we propose a novel solution that generates virtual source-domain users for non-overlapping target-domain users. Our method utilizes a dual attention mechanism to discern similarities between overlapping and non-overlapping users, thereby synthesizing realistic virtual user embeddings. We further introduce a limiter component that ensures the generated virtual users align with real-data distributions while preserving each user's unique characteristics. Notably, our method is model-agnostic and can be seamlessly integrated into any CDR model. Comprehensive experiments conducted on three public datasets with five CDR baselines demonstrate that our method effectively mitigates the CDR non-overlapping user bias, without loss of overall accuracy. Our code is publicly available at https://github.com/WeixinChen98/VUG.
Neural Probabilistic Circuits: Enabling Compositional and Interpretable Predictions through Logical Reasoning
Jan 13, 2025



End-to-end deep neural networks have achieved remarkable success across various domains but are often criticized for their lack of interpretability. While post hoc explanation methods attempt to address this issue, they often fail to accurately represent these black-box models, resulting in misleading or incomplete explanations. To overcome these challenges, we propose an inherently transparent model architecture called Neural Probabilistic Circuits (NPCs), which enable compositional and interpretable predictions through logical reasoning. In particular, an NPC consists of two modules: an attribute recognition model, which predicts probabilities for various attributes, and a task predictor built on a probabilistic circuit, which enables logical reasoning over recognized attributes to make class predictions. To train NPCs, we introduce a three-stage training algorithm comprising attribute recognition, circuit construction, and joint optimization. Moreover, we theoretically demonstrate that an NPC's error is upper-bounded by a linear combination of the errors from its modules. To further demonstrate the interpretability of NPC, we provide both the most probable explanations and the counterfactual explanations. Empirical results on four benchmark datasets show that NPCs strike a balance between interpretability and performance, achieving results competitive even with those of end-to-end black-box models while providing enhanced interpretability.
Political-LLM: Large Language Models in Political Science
Dec 09, 2024



In recent years, large language models (LLMs) have been widely adopted in political science tasks such as election prediction, sentiment analysis, policy impact assessment, and misinformation detection. Meanwhile, the need to systematically understand how LLMs can further revolutionize the field also becomes urgent. In this work, we--a multidisciplinary team of researchers spanning computer science and political science--present the first principled framework termed Political-LLM to advance the comprehensive understanding of integrating LLMs into computational political science. Specifically, we first introduce a fundamental taxonomy classifying the existing explorations into two perspectives: political science and computational methodologies. In particular, from the political science perspective, we highlight the role of LLMs in automating predictive and generative tasks, simulating behavior dynamics, and improving causal inference through tools like counterfactual generation; from a computational perspective, we introduce advancements in data preparation, fine-tuning, and evaluation methods for LLMs that are tailored to political contexts. We identify key challenges and future directions, emphasizing the development of domain-specific datasets, addressing issues of bias and fairness, incorporating human expertise, and redefining evaluation criteria to align with the unique requirements of computational political science. Political-LLM seeks to serve as a guidebook for researchers to foster an informed, ethical, and impactful use of Artificial Intelligence in political science. Our online resource is available at: http://political-llm.org/.
Matryoshka Representation Learning for Recommendation
Jun 11, 2024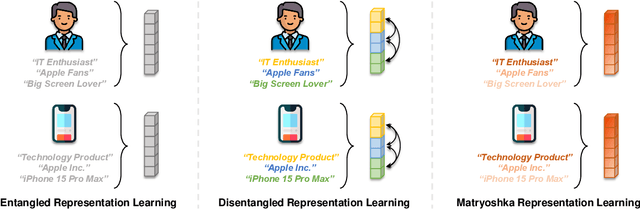
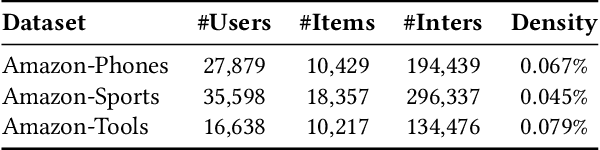
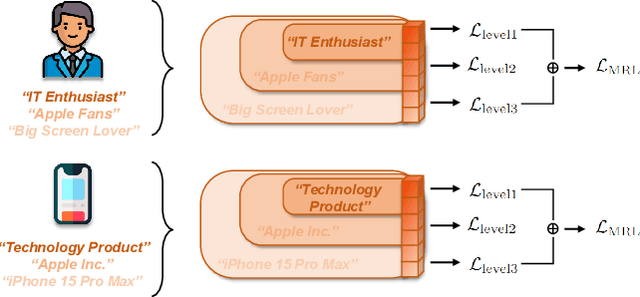
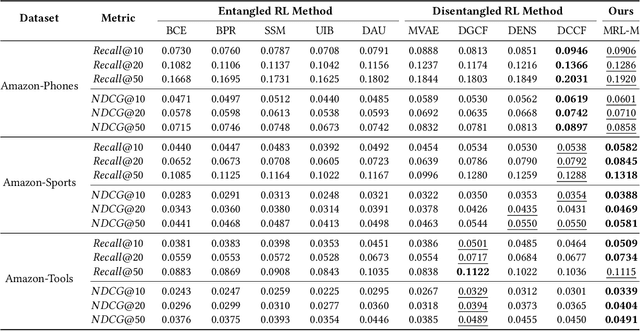
Representation learning is essential for deep-neural-network-based recommender systems to capture user preferences and item features within fixed-dimensional user and item vectors. Unlike existing representation learning methods that either treat each user preference and item feature uniformly or categorize them into discrete clusters, we argue that in the real world, user preferences and item features are naturally expressed and organized in a hierarchical manner, leading to a new direction for representation learning. In this paper, we introduce a novel matryoshka representation learning method for recommendation (MRL4Rec), by which we restructure user and item vectors into matryoshka representations with incrementally dimensional and overlapping vector spaces to explicitly represent user preferences and item features at different hierarchical levels. We theoretically establish that constructing training triplets specific to each level is pivotal in guaranteeing accurate matryoshka representation learning. Subsequently, we propose the matryoshka negative sampling mechanism to construct training triplets, which further ensures the effectiveness of the matryoshka representation learning in capturing hierarchical user preferences and item features. The experiments demonstrate that MRL4Rec can consistently and substantially outperform a number of state-of-the-art competitors on several real-life datasets. Our code is publicly available at https://github.com/Riwei-HEU/MRL.
GRATH: Gradual Self-Truthifying for Large Language Models
Jan 31, 2024Truthfulness is paramount for large language models (LLMs) as they are increasingly deployed in real-world applications. However, existing LLMs still struggle with generating truthful content, as evidenced by their modest performance on benchmarks like TruthfulQA. To address this issue, we propose GRAdual self-truTHifying (GRATH), a novel post-processing method to enhance truthfulness of LLMs. GRATH utilizes out-of-domain question prompts to generate pairwise truthfulness training data with each pair containing a question and its correct and incorrect answers, and then optimizes the model via direct preference optimization (DPO) to learn from the truthfulness difference between answer pairs. GRATH iteratively refines truthfulness data and updates the model, leading to a gradual improvement in model truthfulness in a self-supervised manner. Empirically, we evaluate GRATH using different 7B-LLMs and compare with LLMs with similar or even larger sizes on benchmark datasets. Our results show that GRATH effectively improves LLMs' truthfulness without compromising other core capabilities. Notably, GRATH achieves state-of-the-art performance on TruthfulQA, with MC1 accuracy of 54.71% and MC2 accuracy of 69.10%, which even surpass those on 70B-LLMs.