 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToolFG: Towards Well-Grounded Fine-Grained Image Classification
Jun 01, 2026Fine-grained image classification (FGIC) has broad applications and has attracted significant research attention. In this paper, we explore a novel paradigm for solving FGIC by proposing \textbf{ToolFG}, the first tool-integrated MLLM-based framework tailored to FGIC. ToolFG enables MLLMs to autonomously and flexibly use external tools during the reasoning process, actively interact with images, and collect verifiable visual cues for distinguishing highly similar categories in a more \textit{reliable} and \textit{well-grounded} manner. To equip the model with such tool-use ability, we design a novel \textbf{MCTS-guided tool-use knowledge distillation mechanism}, which effectively mines tool-use- and FGIC-relevant knowledge from advanced proprietary MLLMs for model training. Furthermore, we propose a \textbf{model-tool co-evolution mechanism} that jointly refines the toolset and the model's tool-use policy, driving them toward a mutually adapted and FGIC-specialized state. Extensive experiments demonstrate the effectiveness of our framework.
XGRAG: A Graph-Native Framework for Explaining KG-based Retrieval-Augmented Generation
Apr 27, 2026Graph-based Retrieval-Augmented Generation (GraphRAG) extends traditional RAG by using knowledge graphs (KGs) to give large language models (LLMs) a structured, semantically coherent context, yielding more grounded answers. However, GraphRAG reasoning process remains a black-box, limiting our ability to understand how specific pieces of structured knowledge influence the final output. Existing explainability (XAI) methods for RAG systems, designed for text-based retrieval, are limited to interpreting an LLM response through the relational structures among knowledge components, creating a critical gap in transparency and trustworthiness. To address this, we introduce XGRAG, a novel framework that generates causally grounded explanations for GraphRAG systems by employing graph-based perturbation strategies, to quantify the contribution of individual graph components on the model answer. We conduct extensive experiments comparing XGRAG against RAG-Ex, an XAI baseline for standard RAG, and evaluate its robustness across various question types, narrative structures and LLMs. Our results demonstrate a 14.81% improvement in explanation quality over the baseline RAG-Ex across NarrativeQA, FairyTaleQA, and TriviaQA, evaluated by F1-score measuring alignment between generated explanations and original answers. Furthermore, XGRAG explanations exhibit a strong correlation with graph centrality measures, validating its ability to capture graph structure. XGRAG provides a scalable and generalizable approach towards trustworthy AI through transparent, graph-based explanations that enhance the interpretability of RAG systems.
DiffGraph: An Automated Agent-driven Model Merging Framework for In-the-Wild Text-to-Image Generation
Mar 20, 2026The rapid growth of the text-to-image (T2I) community has fostered a thriving online ecosystem of expert models, which are variants of pretrained diffusion models specialized for diverse generative abilities. Yet, existing model merging methods remain limited in fully leveraging abundant online expert resources and still struggle to meet diverse in-the-wild user needs. We present DiffGraph, a novel agent-driven graph-based model merging framework, which automatically harnesses online experts and flexibly merges them for diverse user needs. Our DiffGraph constructs a scalable graph and organizes ever-expanding online experts within it through node registration and calibration. Then, DiffGraph dynamically activates specific subgraphs based on user needs, enabling flexible combinations of different experts to achieve user-desired generation. Extensive experiments show the efficacy of our method.
Any3D-VLA: Enhancing VLA Robustness via Diverse Point Clouds
Jan 31, 2026Existing Vision-Language-Action (VLA) models typically take 2D images as visual input, which limits their spatial understanding in complex scenes. How can we incorporate 3D information to enhance VLA capabilities? We conduct a pilot study across different observation spaces and visual representations. The results show that explicitly lifting visual input into point clouds yields representations that better complement their corresponding 2D representations. To address the challenges of (1) scarce 3D data and (2) the domain gap induced by cross-environment differences and depth-scale biases, we propose Any3D-VLA. It unifies the simulator, sensor, and model-estimated point clouds within a training pipeline, constructs diverse inputs, and learns domain-agnostic 3D representations that are fused with the corresponding 2D representations. Simulation and real-world experiments demonstrate Any3D-VLA's advantages in improving performance and mitigating the domain gap. Our project homepage is available at https://xianzhefan.github.io/Any3D-VLA.github.io.
Train Once, Deploy Anywhere: Realize Data-Efficient Dynamic Object Manipulation
Aug 19, 2025Realizing generalizable dynamic object manipulation is important for enhancing manufacturing efficiency, as it eliminates specialized engineering for various scenarios. To this end, imitation learning emerges as a promising paradigm, leveraging expert demonstrations to teach a policy manipulation skills. Although the generalization of an imitation learning policy can be improved by increasing demonstrations, demonstration collection is labor-intensive. To address this problem, this paper investigates whether strong generalization in dynamic object manipulation is achievable with only a few demonstrations. Specifically, we develop an entropy-based theoretical framework to quantify the optimization of imitation learning. Based on this framework, we propose a system named Generalizable Entropy-based Manipulation (GEM). Extensive experiments in simulated and real tasks demonstrate that GEM can generalize across diverse environment backgrounds, robot embodiments, motion dynamics, and object geometries. Notably, GEM has been deployed in a real canteen for tableware collection. Without any in-scene demonstration, it achieves a success rate of over 97% across more than 10,000 operations.
Bootstrapping Imitation Learning for Long-horizon Manipulation via Hierarchical Data Collection Space
May 23, 2025Imitation learning (IL) with human demonstrations is a promising method for robotic manipulation tasks. While minimal demonstrations enable robotic action execution, achieving high success rates and generalization requires high cost, e.g., continuously adding data or incrementally conducting human-in-loop processes with complex hardware/software systems. In this paper, we rethink the state/action space of the data collection pipeline as well as the underlying factors responsible for the prediction of non-robust actions. To this end, we introduce a Hierarchical Data Collection Space (HD-Space) for robotic imitation learning, a simple data collection scheme, endowing the model to train with proactive and high-quality data. Specifically, We segment the fine manipulation task into multiple key atomic tasks from a high-level perspective and design atomic state/action spaces for human demonstrations, aiming to generate robust IL data. We conduct empirical evaluations across two simulated and five real-world long-horizon manipulation tasks and demonstrate that IL policy training with HD-Space-based data can achieve significantly enhanced policy performance. HD-Space allows the use of a small amount of demonstration data to train a more powerful policy, particularly for long-horizon manipulation tasks. We aim for HD-Space to offer insights into optimizing data quality and guiding data scaling. project page: https://hd-space-robotics.github.io.
SceneLLM: Implicit Language Reasoning in LLM for Dynamic Scene Graph Generation
Dec 15, 2024


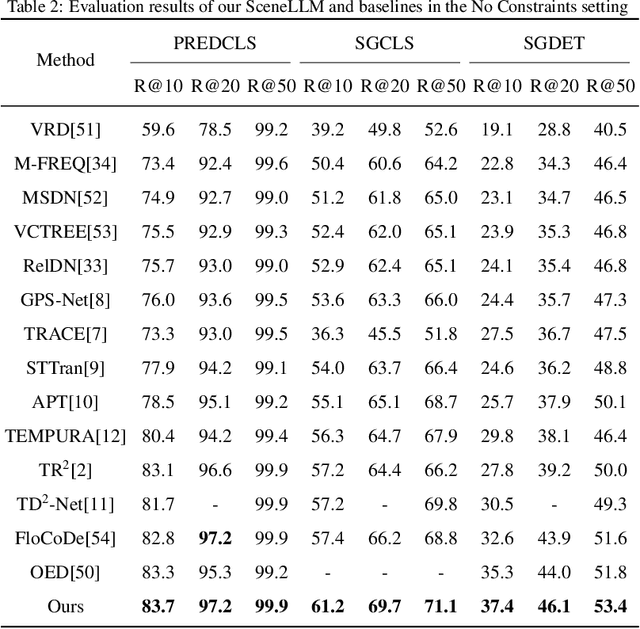
Dynamic scenes contain intricate spatio-temporal information, crucial for mobile robots, UAVs, and autonomous driving systems to make informed decisions. Parsing these scenes into semantic triplets <Subject-Predicate-Object> for accurate Scene Graph Generation (SGG) is highly challenging due to the fluctuating spatio-temporal complexity. Inspired by the reasoning capabilities of Large Language Models (LLMs), we propose SceneLLM, a novel framework that leverages LLMs as powerful scene analyzers for dynamic SGG. Our framework introduces a Video-to-Language (V2L) mapping module that transforms video frames into linguistic signals (scene tokens), making the input more comprehensible for LLMs. To better encode spatial information, we devise a Spatial Information Aggregation (SIA) scheme, inspired by the structure of Chinese characters, which encodes spatial data into tokens. Using Optimal Transport (OT), we generate an implicit language signal from the frame-level token sequence that captures the video's spatio-temporal information. To further improve the LLM's ability to process this implicit linguistic input, we apply Low-Rank Adaptation (LoRA) to fine-tune the model. Finally, we use a transformer-based SGG predictor to decode the LLM's reasoning and predict semantic triplets. Our method achieves state-of-the-art results on the Action Genome (AG) benchmark, and extensive experiments show the effectiveness of SceneLLM in understanding and generating accurate dynamic scene graphs.
VIRT: Vision Instructed Transformer for Robotic Manipulation
Oct 09, 2024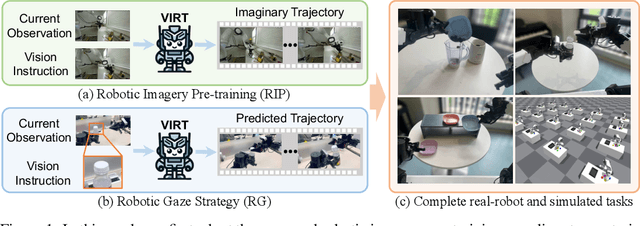

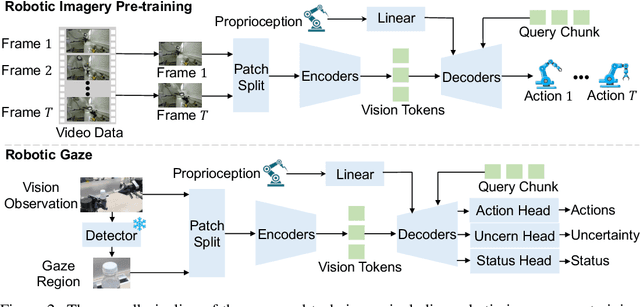
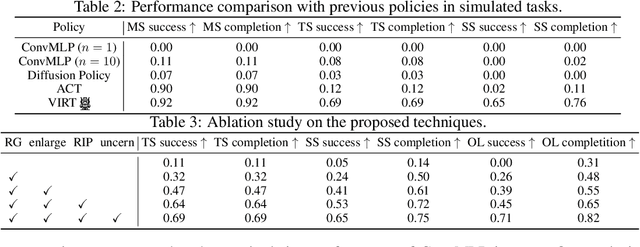
Robotic manipulation, owing to its multi-modal nature, often faces significant training ambiguity, necessitating explicit instructions to clearly delineate the manipulation details in tasks. In this work, we highlight that vision instruction is naturally more comprehensible to recent robotic policies than the commonly adopted text instruction, as these policies are born with some vision understanding ability like human infants. Building on this premise and drawing inspiration from cognitive science, we introduce the robotic imagery paradigm, which realizes large-scale robotic data pre-training without text annotations. Additionally, we propose the robotic gaze strategy that emulates the human eye gaze mechanism, thereby guiding subsequent actions and focusing the attention of the policy on the manipulated object. Leveraging these innovations, we develop VIRT, a fully Transformer-based policy. We design comprehensive tasks using both a physical robot and simulated environments to assess the efficacy of VIRT. The results indicate that VIRT can complete very competitive tasks like ``opening the lid of a tightly sealed bottle'', and the proposed techniques boost the success rates of the baseline policy on diverse challenging tasks from nearly 0% to more than 65%.
TranSplat: Generalizable 3D Gaussian Splatting from Sparse Multi-View Images with Transformers
Aug 25, 2024



Compared with previous 3D reconstruction methods like Nerf, recent Generalizable 3D Gaussian Splatting (G-3DGS) methods demonstrate impressive efficiency even in the sparse-view setting. However, the promising reconstruction performance of existing G-3DGS methods relies heavily on accurate multi-view feature matching, which is quite challenging. Especially for the scenes that have many non-overlapping areas between various views and contain numerous similar regions, the matching performance of existing methods is poor and the reconstruction precision is limited. To address this problem, we develop a strategy that utilizes a predicted depth confidence map to guide accurate local feature matching. In addition, we propose to utilize the knowledge of existing monocular depth estimation models as prior to boost the depth estimation precision in non-overlapping areas between views. Combining the proposed strategies, we present a novel G-3DGS method named TranSplat, which obtains the best performance on both the RealEstate10K and ACID benchmarks while maintaining competitive speed and presenting strong cross-dataset generalization ability. Our code, and demos will be available at: https://xingyoujun.github.io/transplat.
LARM: Large Auto-Regressive Model for Long-Horizon Embodied Intelligence
May 27, 2024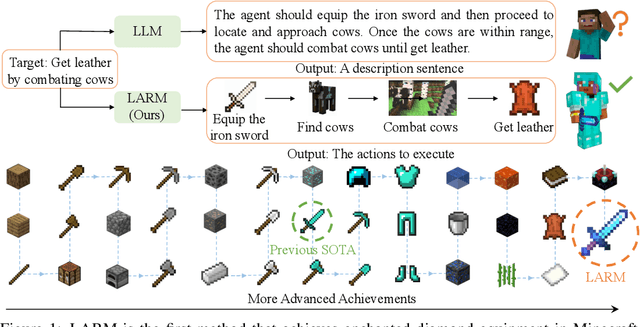
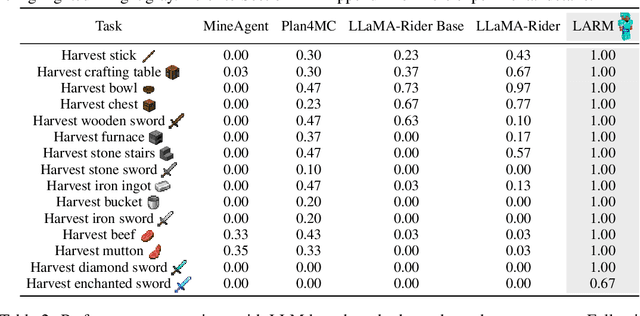
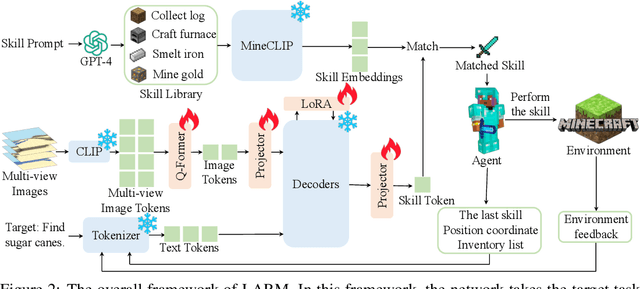

Due to the need to interact with the real world, embodied agents are required to possess comprehensive prior knowledge, long-horizon planning capability, and a swift response speed. Despite recent large language model (LLM) based agents achieving promising performance, they still exhibit several limitations. For instance, the output of LLMs is a descriptive sentence, which is ambiguous when determining specific actions. To address these limitations, we introduce the large auto-regressive model (LARM). LARM leverages both text and multi-view images as input and predicts subsequent actions in an auto-regressive manner. To train LARM, we develop a novel data format named auto-regressive node transmission structure and assemble a corresponding dataset. Adopting a two-phase training regimen, LARM successfully harvests enchanted equipment in Minecraft, which demands significantly more complex decision-making chains than the highest achievements of prior best methods. Besides, the speed of LARM is 6.8x faster.