 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Monitoring Enough? Strategic Agent Selection For Stealthy Attack in Multi-Agent Discussions
Mar 22, 2026Multi-agent discussions have been widely adopted, motivating growing efforts to develop attacks that expose their vulnerabilities. In this work, we study a practical yet largely unexplored attack scenario, the discussion-monitored scenario, where anomaly detectors continuously monitor inter-agent communications and block detected adversarial messages. Although existing attacks are effective without discussion monitoring, we show that they exhibit detectable patterns and largely fail under such monitoring constraints. But does this imply that monitoring alone is sufficient to secure multi-agent discussions? To answer this question, we develop a novel attack method explicitly tailored to the discussion-monitored scenario. Extensive experiments demonstrate that effective attacks remain possible even under continuous monitoring, indicating that monitoring alone does not eliminate adversarial risks.
When Visual Privacy Protection Meets Multimodal Large Language Models
Mar 14, 2026The emergence of Multimodal Large Language Models (MLLMs) and the widespread usage of MLLM cloud services such as GPT-4V raised great concerns about privacy leakage in visual data. As these models are typically deployed in cloud services, users are required to submit their images and videos, posing serious privacy risks. However, how to tackle such privacy concerns is an under-explored problem. Thus, in this paper, we aim to conduct a new investigation to protect visual privacy when enjoying the convenience brought by MLLM services. We address the practical case where the MLLM is a "black box", i.e., we only have access to its input and output without knowing its internal model information. To tackle such a challenging yet demanding problem, we propose a novel framework, in which we carefully design the learning objective with Pareto optimality to seek a better trade-off between visual privacy and MLLM's performance, and propose critical-history enhanced optimization to effectively optimize the framework with the black-box MLLM. Our experiments show that our method is effective on different benchmarks.
Decentralized Autoregressive Generation
Jan 06, 2026We present a theoretical analysis of decentralization of autoregressive generation. We define the Decentralized Discrete Flow Matching objective, by expressing probability generating velocity as a linear combination of expert flows. We also conduct experiments demonstrating the equivalence between decentralized and centralized training settings for multimodal language models across diverse set of benchmarks. Specifically, we compare two distinct paradigms: LLaVA and InternVL 2.5-1B, which uses a fixed CLIP vision encoder and performs full-parameter fine-tuning (ViT+MLP+LLM) during the instruction tuning stage.
Learning to Generate Cross-Task Unexploitable Examples
Dec 15, 2025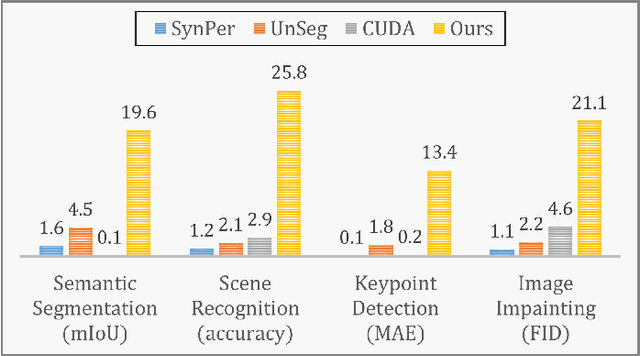
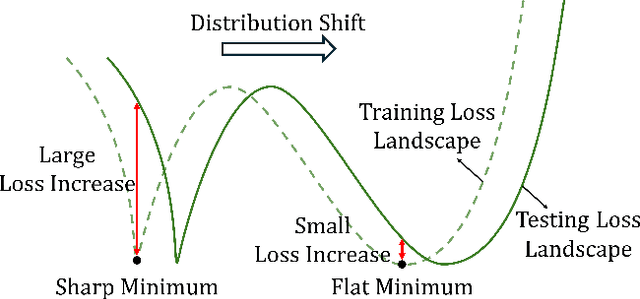

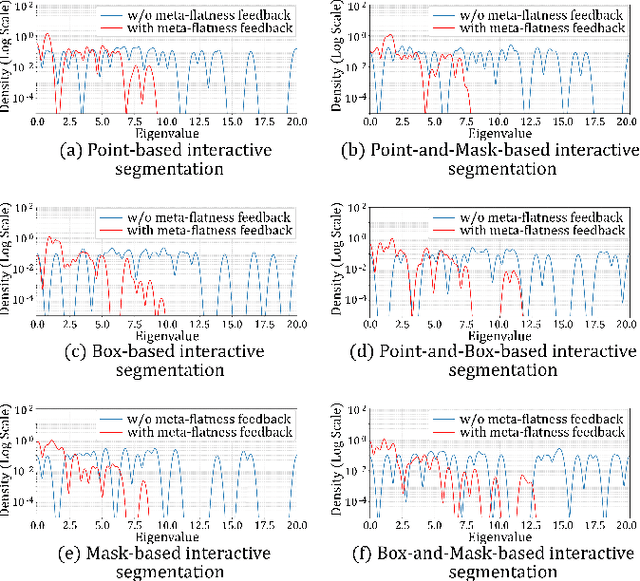
Unexploitable example generation aims to transform personal images into their unexploitable (unlearnable) versions before they are uploaded online, thereby preventing unauthorized exploitation of online personal images. Recently, this task has garnered significant research attention due to its critical relevance to personal data privacy. Yet, despite recent progress, existing methods for this task can still suffer from limited practical applicability, as they can fail to generate examples that are broadly unexploitable across different real-world computer vision tasks. To deal with this problem, in this work, we propose a novel Meta Cross-Task Unexploitable Example Generation (MCT-UEG) framework. At the core of our framework, to optimize the unexploitable example generator for effectively producing broadly unexploitable examples, we design a flat-minima-oriented meta training and testing scheme. Extensive experiments show the efficacy of our framework.
TSTMotion: Training-free Scene-aware Text-to-motion Generation
May 05, 2025



Text-to-motion generation has recently garnered significant research interest, primarily focusing on generating human motion sequences in blank backgrounds. However, human motions commonly occur within diverse 3D scenes, which has prompted exploration into scene-aware text-to-motion generation methods. Yet, existing scene-aware methods often rely on large-scale ground-truth motion sequences in diverse 3D scenes, which poses practical challenges due to the expensive cost. To mitigate this challenge, we are the first to propose a \textbf{T}raining-free \textbf{S}cene-aware \textbf{T}ext-to-\textbf{Motion} framework, dubbed as \textbf{TSTMotion}, that efficiently empowers pre-trained blank-background motion generators with the scene-aware capability. Specifically, conditioned on the given 3D scene and text description, we adopt foundation models together to reason, predict and validate a scene-aware motion guidance. Then, the motion guidance is incorporated into the blank-background motion generators with two modifications, resulting in scene-aware text-driven motion sequences. Extensive experiments demonstrate the efficacy and generalizability of our proposed framework. We release our code in \href{https://tstmotion.github.io/}{Project Page}.
CMMLoc: Advancing Text-to-PointCloud Localization with Cauchy-Mixture-Model Based Framework
Mar 05, 2025



The goal of point cloud localization based on linguistic description is to identify a 3D position using textual description in large urban environments, which has potential applications in various fields, such as determining the location for vehicle pickup or goods delivery. Ideally, for a textual description and its corresponding 3D location, the objects around the 3D location should be fully described in the text description. However, in practical scenarios, e.g., vehicle pickup, passengers usually describe only the part of the most significant and nearby surroundings instead of the entire environment. In response to this $\textbf{partially relevant}$ challenge, we propose $\textbf{CMMLoc}$, an uncertainty-aware $\textbf{C}$auchy-$\textbf{M}$ixture-$\textbf{M}$odel ($\textbf{CMM}$) based framework for text-to-point-cloud $\textbf{Loc}$alization. To model the uncertain semantic relations between text and point cloud, we integrate CMM constraints as a prior during the interaction between the two modalities. We further design a spatial consolidation scheme to enable adaptive aggregation of different 3D objects with varying receptive fields. To achieve precise localization, we propose a cardinal direction integration module alongside a modality pre-alignment strategy, helping capture the spatial relationships among objects and bringing the 3D objects closer to the text modality. Comprehensive experiments validate that CMMLoc outperforms existing methods, achieving state-of-the-art results on the KITTI360Pose dataset. Codes are available in this GitHub repository https://github.com/kevin301342/CMMLoc.
HyLiFormer: Hyperbolic Linear Attention for Skeleton-based Human Action Recognition
Feb 09, 2025



Transformers have demonstrated remarkable performance in skeleton-based human action recognition, yet their quadratic computational complexity remains a bottleneck for real-world applications. To mitigate this, linear attention mechanisms have been explored but struggle to capture the hierarchical structure of skeleton data. Meanwhile, the Poincar\'e model, as a typical hyperbolic geometry, offers a powerful framework for modeling hierarchical structures but lacks well-defined operations for existing mainstream linear attention. In this paper, we propose HyLiFormer, a novel hyperbolic linear attention Transformer tailored for skeleton-based action recognition. Our approach incorporates a Hyperbolic Transformation with Curvatures (HTC) module to map skeleton data into hyperbolic space and a Hyperbolic Linear Attention (HLA) module for efficient long-range dependency modeling. Theoretical analysis and extensive experiments on NTU RGB+D and NTU RGB+D 120 datasets demonstrate that HyLiFormer significantly reduces computational complexity while preserving model accuracy, making it a promising solution for efficiency-critical applications.
DisC-GS: Discontinuity-aware Gaussian Splatting
May 24, 2024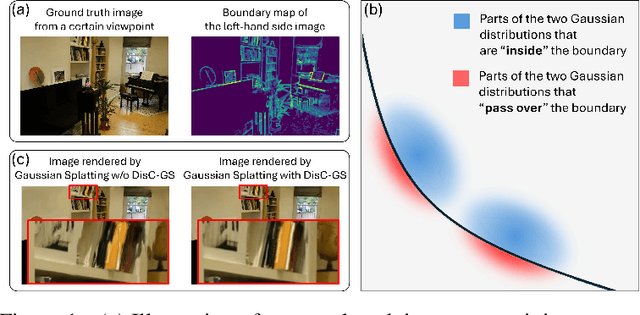
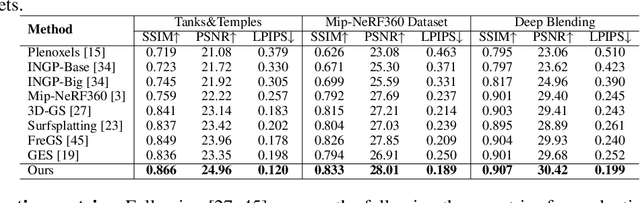
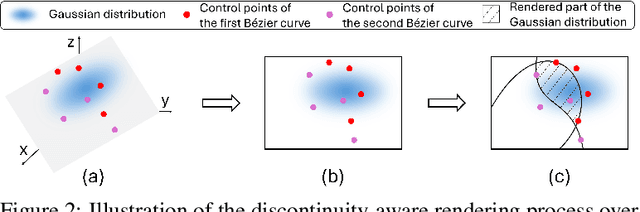
Recently, Gaussian Splatting, a method that represents a 3D scene as a collection of Gaussian distributions, has gained significant attention in addressing the task of novel view synthesis. In this paper, we highlight a fundamental limitation of Gaussian Splatting: its inability to accurately render discontinuities and boundaries in images due to the continuous nature of Gaussian distributions. To address this issue, we propose a novel framework enabling Gaussian Splatting to perform discontinuity-aware image rendering. Additionally, we introduce a B\'ezier-boundary gradient approximation strategy within our framework to keep the ``differentiability'' of the proposed discontinuity-aware rendering process. Extensive experiments demonstrate the efficacy of our framework.
Off-the-shelf ChatGPT is a Good Few-shot Human Motion Predictor
May 24, 2024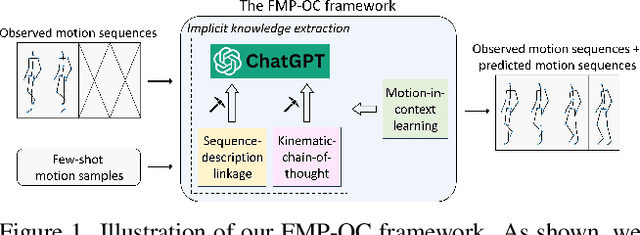
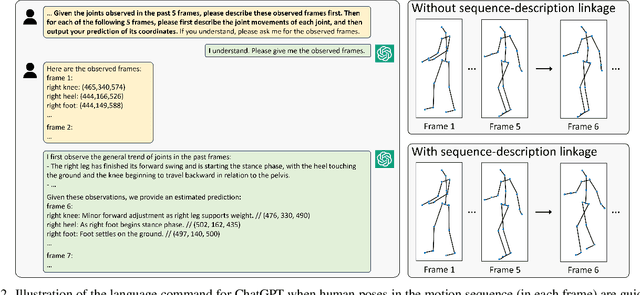
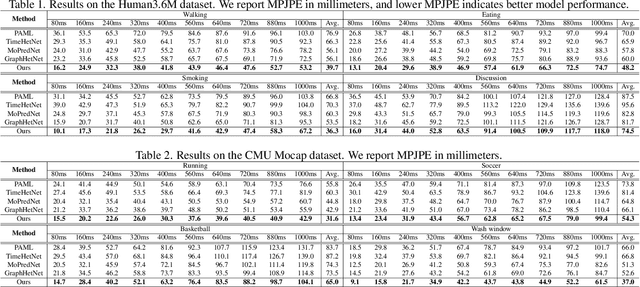
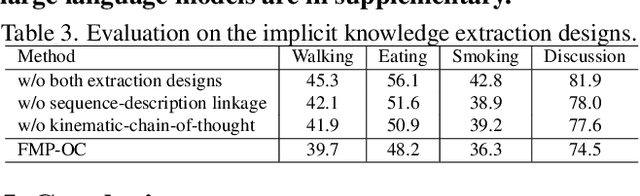
To facilitate the application of motion prediction in practice, recently, the few-shot motion prediction task has attracted increasing research attention. Yet, in existing few-shot motion prediction works, a specific model that is dedicatedly trained over human motions is generally required. In this work, rather than tackling this task through training a specific human motion prediction model, we instead propose a novel FMP-OC framework. In FMP-OC, in a totally training-free manner, we enable Few-shot Motion Prediction, which is a non-language task, to be performed directly via utilizing the Off-the-shelf language model ChatGPT. Specifically, to lead ChatGPT as a language model to become an accurate motion predictor, in FMP-OC, we first introduce several novel designs to facilitate extracting implicit knowledge from ChatGPT. Moreover, we also incorporate our framework with a motion-in-context learning mechanism. Extensive experiments demonstrate the efficacy of our proposed framework.
LLMs are Good Action Recognizers
Mar 31, 2024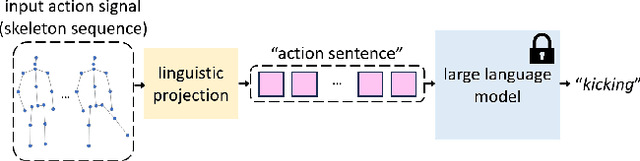
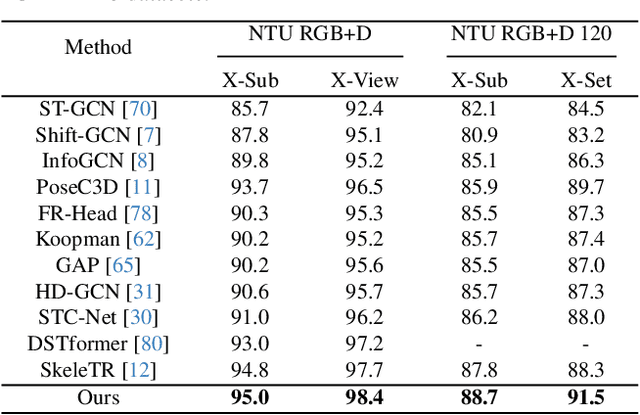
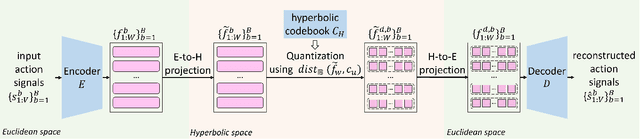
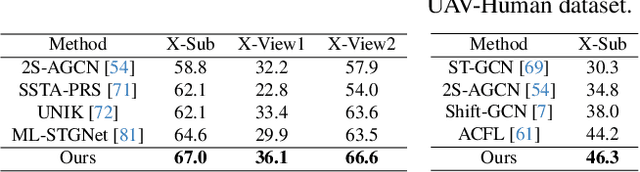
Skeleton-based action recognition has attracted lots of research attention. Recently, to build an accurate skeleton-based action recognizer, a variety of works have been proposed. Among them, some works use large model architectures as backbones of their recognizers to boost the skeleton data representation capability, while some other works pre-train their recognizers on external data to enrich the knowledge. In this work, we observe that large language models which have been extensively used in various natural language processing tasks generally hold both large model architectures and rich implicit knowledge. Motivated by this, we propose a novel LLM-AR framework, in which we investigate treating the Large Language Model as an Action Recognizer. In our framework, we propose a linguistic projection process to project each input action signal (i.e., each skeleton sequence) into its ``sentence format'' (i.e., an ``action sentence''). Moreover, we also incorporate our framework with several designs to further facilitate this linguistic projection process. Extensive experiments demonstrate the efficacy of our proposed framework.