 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-Connect: Interaction between Text-Driven Human Motion Generator and 3D Scenes in a Training-free Manner
Paper and Code
Mar 22, 2024
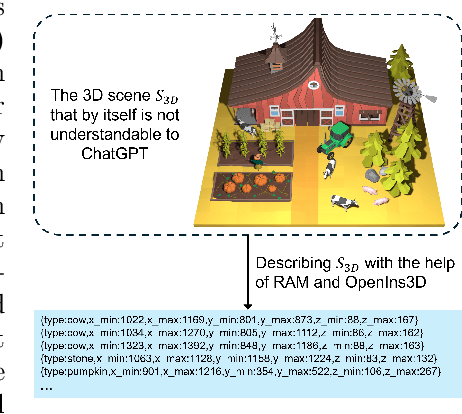
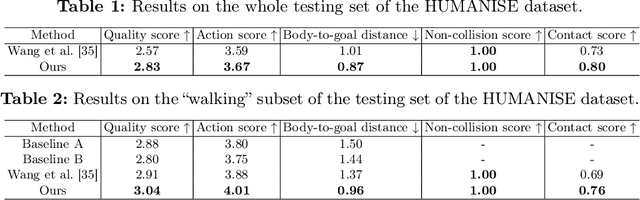
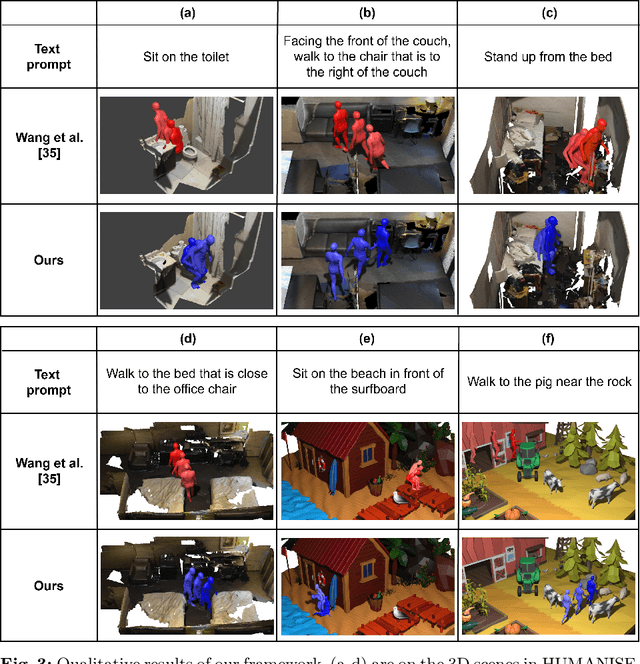
Recently, while text-driven human motion generation has received massive research attention, most existing text-driven motion generators are generally only designed to generate motion sequences in a blank background. While this is the case, in practice, human beings naturally perform their motions in 3D scenes, rather than in a blank background. Considering this, we here aim to perform scene-aware text-drive motion generation instead. Yet, intuitively training a separate scene-aware motion generator in a supervised way can require a large amount of motion samples to be troublesomely collected and annotated in a large scale of different 3D scenes. To handle this task rather in a relatively convenient manner, in this paper, we propose a novel GPT-connect framework. In GPT-connect, we enable scene-aware motion sequences to be generated directly utilizing the existing blank-background human motion generator, via leveraging ChatGPT to connect the existing motion generator with the 3D scene in a totally training-free manner. Extensive experiments demonstrate the efficacy and generalizability of our proposed framework.