 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSTMotion: Training-free Scene-aware Text-to-motion Generation
May 05, 2025Text-to-motion generation has recently garnered significant research interest, primarily focusing on generating human motion sequences in blank backgrounds. However, human motions commonly occur within diverse 3D scenes, which has prompted exploration into scene-aware text-to-motion generation methods. Yet, existing scene-aware methods often rely on large-scale ground-truth motion sequences in diverse 3D scenes, which poses practical challenges due to the expensive cost. To mitigate this challenge, we are the first to propose a \textbf{T}raining-free \textbf{S}cene-aware \textbf{T}ext-to-\textbf{Motion} framework, dubbed as \textbf{TSTMotion}, that efficiently empowers pre-trained blank-background motion generators with the scene-aware capability. Specifically, conditioned on the given 3D scene and text description, we adopt foundation models together to reason, predict and validate a scene-aware motion guidance. Then, the motion guidance is incorporated into the blank-background motion generators with two modifications, resulting in scene-aware text-driven motion sequences. Extensive experiments demonstrate the efficacy and generalizability of our proposed framework. We release our code in \href{https://tstmotion.github.io/}{Project Page}.
MotionLab: Unified Human Motion Generation and Editing via the Motion-Condition-Motion Paradigm
Feb 06, 2025



Human motion generation and editing are key components of computer graphics and vision. However, current approaches in this field tend to offer isolated solutions tailored to specific tasks, which can be inefficient and impractical for real-world applications. While some efforts have aimed to unify motion-related tasks, these methods simply use different modalities as conditions to guide motion generation. Consequently, they lack editing capabilities, fine-grained control, and fail to facilitate knowledge sharing across tasks. To address these limitations and provide a versatile, unified framework capable of handling both human motion generation and editing, we introduce a novel paradigm: Motion-Condition-Motion, which enables the unified formulation of diverse tasks with three concepts: source motion, condition, and target motion. Based on this paradigm, we propose a unified framework, MotionLab, which incorporates rectified flows to learn the mapping from source motion to target motion, guided by the specified conditions. In MotionLab, we introduce the 1) MotionFlow Transformer to enhance conditional generation and editing without task-specific modules; 2) Aligned Rotational Position Encoding} to guarantee the time synchronization between source motion and target motion; 3) Task Specified Instruction Modulation; and 4) Motion Curriculum Learning for effective multi-task learning and knowledge sharing across tasks. Notably, our MotionLab demonstrates promising generalization capabilities and inference efficiency across multiple benchmarks for human motion. Our code and additional video results are available at: https://diouo.github.io/motionlab.github.io/.
GPT-Connect: Interaction between Text-Driven Human Motion Generator and 3D Scenes in a Training-free Manner
Mar 22, 2024
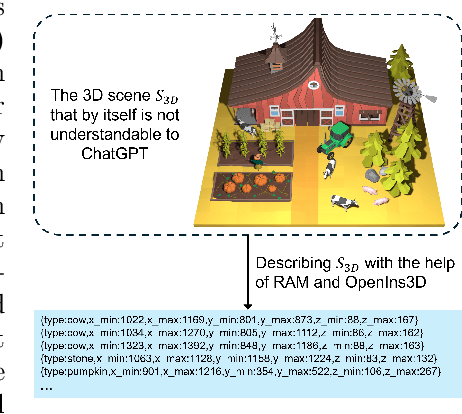
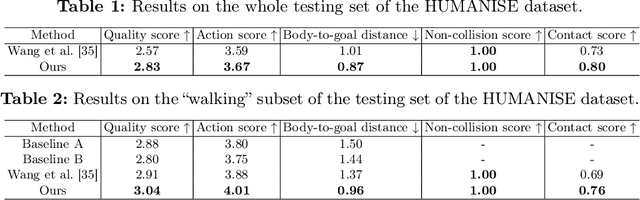
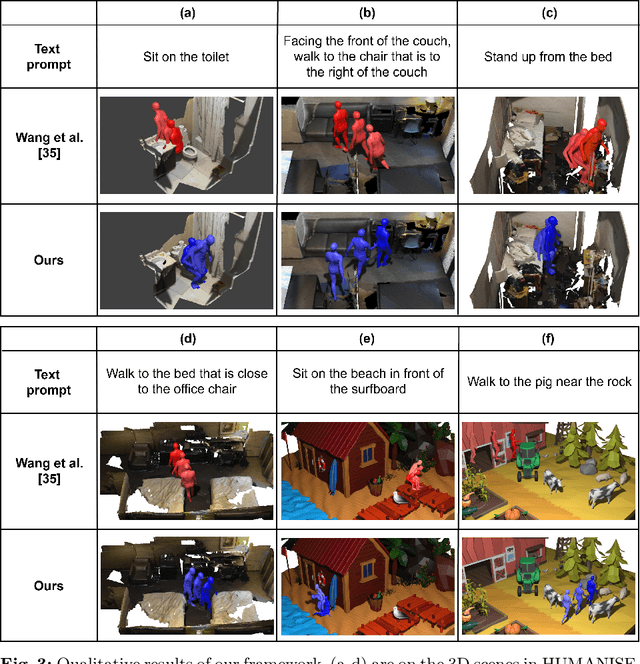
Recently, while text-driven human motion generation has received massive research attention, most existing text-driven motion generators are generally only designed to generate motion sequences in a blank background. While this is the case, in practice, human beings naturally perform their motions in 3D scenes, rather than in a blank background. Considering this, we here aim to perform scene-aware text-drive motion generation instead. Yet, intuitively training a separate scene-aware motion generator in a supervised way can require a large amount of motion samples to be troublesomely collected and annotated in a large scale of different 3D scenes. To handle this task rather in a relatively convenient manner, in this paper, we propose a novel GPT-connect framework. In GPT-connect, we enable scene-aware motion sequences to be generated directly utilizing the existing blank-background human motion generator, via leveraging ChatGPT to connect the existing motion generator with the 3D scene in a totally training-free manner. Extensive experiments demonstrate the efficacy and generalizability of our proposed framework.
Trustworthy Large Models in Vision: A Survey
Dec 01, 2023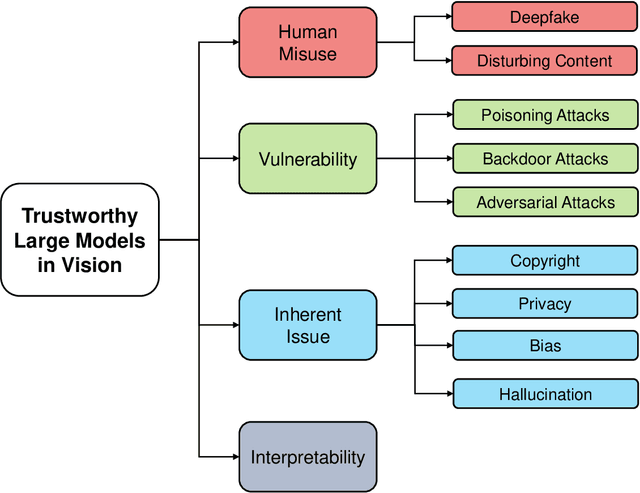



The rapid progress of Large Models (LMs) has recently revolutionized various fields of deep learning with remarkable grades, ranging from Natural Language Processing (NLP) to Computer Vision (CV). However, LMs are increasingly challenged and criticized by academia and industry due to their powerful performance but untrustworthy behavior, which urgently needs to be alleviated by reliable methods. Despite the abundance of literature on trustworthy LMs in NLP, a systematic survey specifically delving into the trustworthiness of LMs in CV remains absent. In order to mitigate this gap, we summarize four relevant concerns that obstruct the trustworthy usage in vision of LMs in this survey, including 1) human misuse, 2) vulnerability, 3) inherent issue and 4) interpretability. By highlighting corresponding challenge, countermeasures, and discussion in each topic, we hope this survey will facilitate readers' understanding of this field, promote alignment of LMs with human expectations and enable trustworthy LMs to serve as welfare rather than disaster for human society.