 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs are Good Action Recognizers
Paper and Code
Mar 31, 2024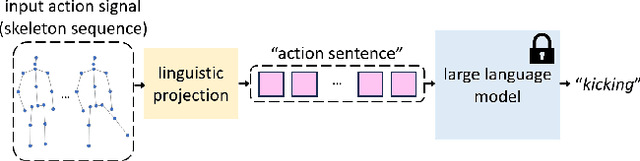
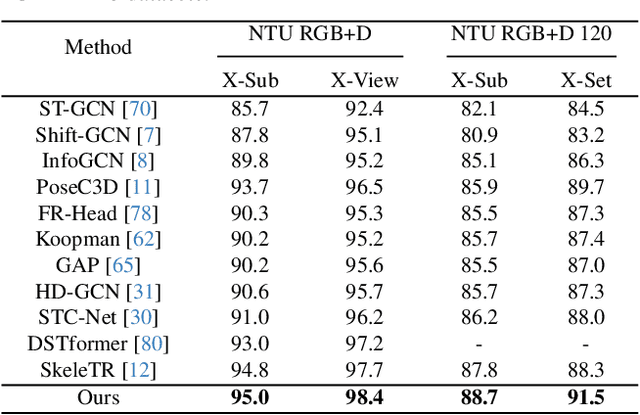
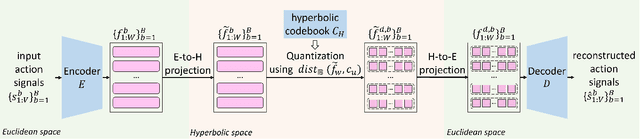
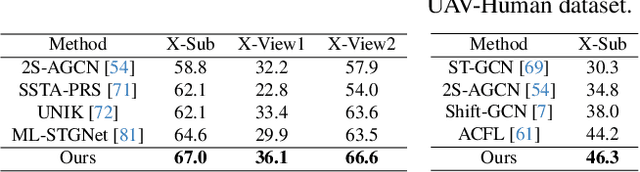
Skeleton-based action recognition has attracted lots of research attention. Recently, to build an accurate skeleton-based action recognizer, a variety of works have been proposed. Among them, some works use large model architectures as backbones of their recognizers to boost the skeleton data representation capability, while some other works pre-train their recognizers on external data to enrich the knowledge. In this work, we observe that large language models which have been extensively used in various natural language processing tasks generally hold both large model architectures and rich implicit knowledge. Motivated by this, we propose a novel LLM-AR framework, in which we investigate treating the Large Language Model as an Action Recognizer. In our framework, we propose a linguistic projection process to project each input action signal (i.e., each skeleton sequence) into its ``sentence format'' (i.e., an ``action sentence''). Moreover, we also incorporate our framework with several designs to further facilitate this linguistic projection process. Extensive experiments demonstrate the efficacy of our proposed framework.