 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffordBot: 3D Fine-grained Embodied Reasoning via Multimodal Large Language Models
Nov 13, 2025
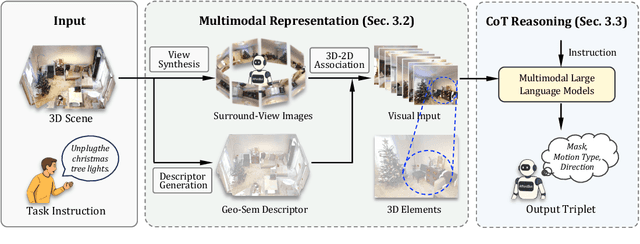


Effective human-agent collaboration in physical environments requires understanding not only what to act upon, but also where the actionable elements are and how to interact with them. Existing approaches often operate at the object level or disjointedly handle fine-grained affordance reasoning, lacking coherent, instruction-driven grounding and reasoning. In this work, we introduce a new task: Fine-grained 3D Embodied Reasoning, which requires an agent to predict, for each referenced affordance element in a 3D scene, a structured triplet comprising its spatial location, motion type, and motion axis, based on a task instruction. To solve this task, we propose AffordBot, a novel framework that integrates Multimodal Large Language Models (MLLMs) with a tailored chain-of-thought (CoT) reasoning paradigm. To bridge the gap between 3D input and 2D-compatible MLLMs, we render surround-view images of the scene and project 3D element candidates into these views, forming a rich visual representation aligned with the scene geometry. Our CoT pipeline begins with an active perception stage, prompting the MLLM to select the most informative viewpoint based on the instruction, before proceeding with step-by-step reasoning to localize affordance elements and infer plausible interaction motions. Evaluated on the SceneFun3D dataset, AffordBot achieves state-of-the-art performance, demonstrating strong generalization and physically grounded reasoning with only 3D point cloud input and MLLMs.
CMMLoc: Advancing Text-to-PointCloud Localization with Cauchy-Mixture-Model Based Framework
Mar 05, 2025



The goal of point cloud localization based on linguistic description is to identify a 3D position using textual description in large urban environments, which has potential applications in various fields, such as determining the location for vehicle pickup or goods delivery. Ideally, for a textual description and its corresponding 3D location, the objects around the 3D location should be fully described in the text description. However, in practical scenarios, e.g., vehicle pickup, passengers usually describe only the part of the most significant and nearby surroundings instead of the entire environment. In response to this $\textbf{partially relevant}$ challenge, we propose $\textbf{CMMLoc}$, an uncertainty-aware $\textbf{C}$auchy-$\textbf{M}$ixture-$\textbf{M}$odel ($\textbf{CMM}$) based framework for text-to-point-cloud $\textbf{Loc}$alization. To model the uncertain semantic relations between text and point cloud, we integrate CMM constraints as a prior during the interaction between the two modalities. We further design a spatial consolidation scheme to enable adaptive aggregation of different 3D objects with varying receptive fields. To achieve precise localization, we propose a cardinal direction integration module alongside a modality pre-alignment strategy, helping capture the spatial relationships among objects and bringing the 3D objects closer to the text modality. Comprehensive experiments validate that CMMLoc outperforms existing methods, achieving state-of-the-art results on the KITTI360Pose dataset. Codes are available in this GitHub repository https://github.com/kevin301342/CMMLoc.