 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIRT: Vision Instructed Transformer for Robotic Manipulation
Paper and Code
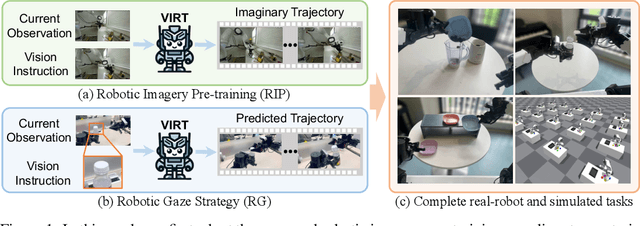

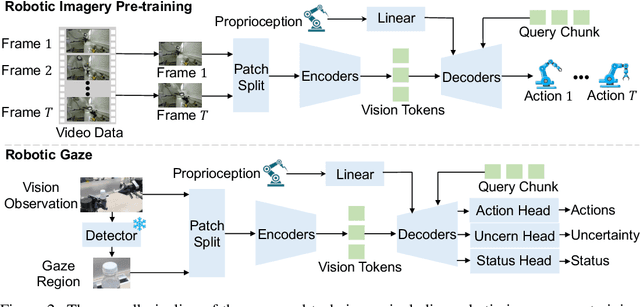
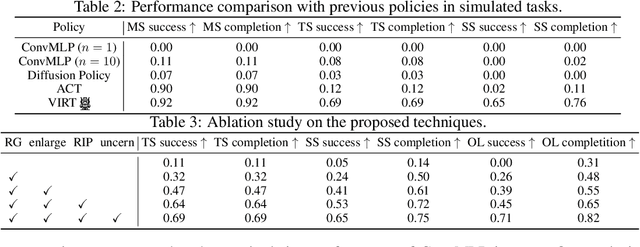
Robotic manipulation, owing to its multi-modal nature, often faces significant training ambiguity, necessitating explicit instructions to clearly delineate the manipulation details in tasks. In this work, we highlight that vision instruction is naturally more comprehensible to recent robotic policies than the commonly adopted text instruction, as these policies are born with some vision understanding ability like human infants. Building on this premise and drawing inspiration from cognitive science, we introduce the robotic imagery paradigm, which realizes large-scale robotic data pre-training without text annotations. Additionally, we propose the robotic gaze strategy that emulates the human eye gaze mechanism, thereby guiding subsequent actions and focusing the attention of the policy on the manipulated object. Leveraging these innovations, we develop VIRT, a fully Transformer-based policy. We design comprehensive tasks using both a physical robot and simulated environments to assess the efficacy of VIRT. The results indicate that VIRT can complete very competitive tasks like ``opening the lid of a tightly sealed bottle'', and the proposed techniques boost the success rates of the baseline policy on diverse challenging tasks from nearly 0% to more than 65%.