 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better Dental AI: A Multimodal Benchmark and Instruction Dataset for Panoramic X-ray Analysis
Sep 11, 2025



Recent advances in large vision-language models (LVLMs) have demonstrated strong performance on general-purpose medical tasks. However, their effectiveness in specialized domains such as dentistry remains underexplored. In particular, panoramic X-rays, a widely used imaging modality in oral radiology, pose interpretative challenges due to dense anatomical structures and subtle pathological cues, which are not captured by existing medical benchmarks or instruction datasets. To this end, we introduce MMOral, the first large-scale multimodal instruction dataset and benchmark tailored for panoramic X-ray interpretation. MMOral consists of 20,563 annotated images paired with 1.3 million instruction-following instances across diverse task types, including attribute extraction, report generation, visual question answering, and image-grounded dialogue. In addition, we present MMOral-Bench, a comprehensive evaluation suite covering five key diagnostic dimensions in dentistry. We evaluate 64 LVLMs on MMOral-Bench and find that even the best-performing model, i.e., GPT-4o, only achieves 41.45% accuracy, revealing significant limitations of current models in this domain. To promote the progress of this specific domain, we also propose OralGPT, which conducts supervised fine-tuning (SFT) upon Qwen2.5-VL-7B with our meticulously curated MMOral instruction dataset. Remarkably, a single epoch of SFT yields substantial performance enhancements for LVLMs, e.g., OralGPT demonstrates a 24.73% improvement. Both MMOral and OralGPT hold significant potential as a critical foundation for intelligent dentistry and enable more clinically impactful multimodal AI systems in the dental field. The dataset, model, benchmark, and evaluation suite are available at https://github.com/isbrycee/OralGPT.
Bootstrapping Imitation Learning for Long-horizon Manipulation via Hierarchical Data Collection Space
May 23, 2025Imitation learning (IL) with human demonstrations is a promising method for robotic manipulation tasks. While minimal demonstrations enable robotic action execution, achieving high success rates and generalization requires high cost, e.g., continuously adding data or incrementally conducting human-in-loop processes with complex hardware/software systems. In this paper, we rethink the state/action space of the data collection pipeline as well as the underlying factors responsible for the prediction of non-robust actions. To this end, we introduce a Hierarchical Data Collection Space (HD-Space) for robotic imitation learning, a simple data collection scheme, endowing the model to train with proactive and high-quality data. Specifically, We segment the fine manipulation task into multiple key atomic tasks from a high-level perspective and design atomic state/action spaces for human demonstrations, aiming to generate robust IL data. We conduct empirical evaluations across two simulated and five real-world long-horizon manipulation tasks and demonstrate that IL policy training with HD-Space-based data can achieve significantly enhanced policy performance. HD-Space allows the use of a small amount of demonstration data to train a more powerful policy, particularly for long-horizon manipulation tasks. We aim for HD-Space to offer insights into optimizing data quality and guiding data scaling. project page: https://hd-space-robotics.github.io.
VIRT: Vision Instructed Transformer for Robotic Manipulation
Oct 09, 2024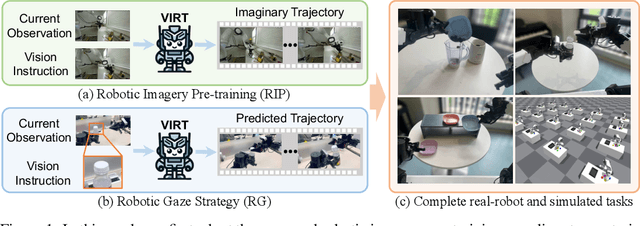

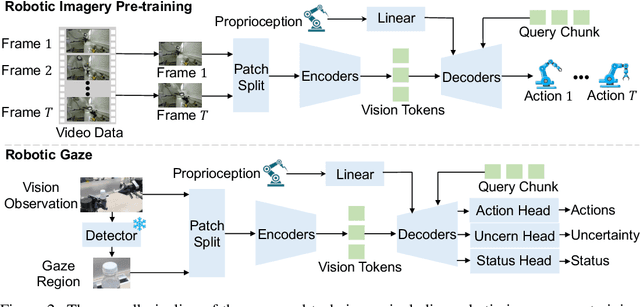
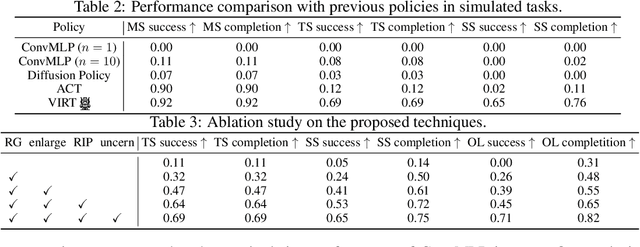
Robotic manipulation, owing to its multi-modal nature, often faces significant training ambiguity, necessitating explicit instructions to clearly delineate the manipulation details in tasks. In this work, we highlight that vision instruction is naturally more comprehensible to recent robotic policies than the commonly adopted text instruction, as these policies are born with some vision understanding ability like human infants. Building on this premise and drawing inspiration from cognitive science, we introduce the robotic imagery paradigm, which realizes large-scale robotic data pre-training without text annotations. Additionally, we propose the robotic gaze strategy that emulates the human eye gaze mechanism, thereby guiding subsequent actions and focusing the attention of the policy on the manipulated object. Leveraging these innovations, we develop VIRT, a fully Transformer-based policy. We design comprehensive tasks using both a physical robot and simulated environments to assess the efficacy of VIRT. The results indicate that VIRT can complete very competitive tasks like ``opening the lid of a tightly sealed bottle'', and the proposed techniques boost the success rates of the baseline policy on diverse challenging tasks from nearly 0% to more than 65%.
Self-supervised Pre-training for Transferable Multi-modal Perception
May 28, 2024In autonomous driving, multi-modal perception models leveraging inputs from multiple sensors exhibit strong robustness in degraded environments. However, these models face challenges in efficiently and effectively transferring learned representations across different modalities and tasks. This paper presents NeRF-Supervised Masked Auto Encoder (NS-MAE), a self-supervised pre-training paradigm for transferable multi-modal representation learning. NS-MAE is designed to provide pre-trained model initializations for efficient and high-performance fine-tuning. Our approach uses masked multi-modal reconstruction in neural radiance fields (NeRF), training the model to reconstruct missing or corrupted input data across multiple modalities. Specifically, multi-modal embeddings are extracted from corrupted LiDAR point clouds and images, conditioned on specific view directions and locations. These embeddings are then rendered into projected multi-modal feature maps using neural rendering techniques. The original multi-modal signals serve as reconstruction targets for the rendered feature maps, facilitating self-supervised representation learning. Extensive experiments demonstrate the promising transferability of NS-MAE representations across diverse multi-modal and single-modal perception models. This transferability is evaluated on various 3D perception downstream tasks, such as 3D object detection and BEV map segmentation, using different amounts of fine-tuning labeled data. Our code will be released to support the community.
Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models
Dec 11, 2023



Modern Large Vision-Language Models (LVLMs) enjoy the same vision vocabulary -- CLIP, which can cover most common vision tasks. However, for some special vision task that needs dense and fine-grained vision perception, e.g., document-level OCR or chart understanding, especially in non-English scenarios, the CLIP-style vocabulary may encounter low efficiency in tokenizing the vision knowledge and even suffer out-of-vocabulary problem. Accordingly, we propose Vary, an efficient and effective method to scale up the vision vocabulary of LVLMs. The procedures of Vary are naturally divided into two folds: the generation and integration of a new vision vocabulary. In the first phase, we devise a vocabulary network along with a tiny decoder-only transformer to produce the desired vocabulary via autoregression. In the next, we scale up the vanilla vision vocabulary by merging the new one with the original one (CLIP), enabling the LVLMs can quickly garner new features. Compared to the popular BLIP-2, MiniGPT4, and LLaVA, Vary can maintain its vanilla capabilities while enjoying more excellent fine-grained perception and understanding ability. Specifically, Vary is competent in new document parsing features (OCR or markdown conversion) while achieving 78.2% ANLS in DocVQA and 36.2% in MMVet. Our code will be publicly available on the homepage.
Merlin:Empowering Multimodal LLMs with Foresight Minds
Nov 30, 2023Humans possess the remarkable ability to foresee the future to a certain extent based on present observations, a skill we term as foresight minds. However, this capability remains largely under explored within existing Multimodal Large Language Models (MLLMs), hindering their capacity to learn the fundamental principles of how things operate and the intentions behind the observed subjects. To address this issue, we introduce the integration of future modeling into the existing learning frameworks of MLLMs. By utilizing the subject trajectory, a highly structured representation of a consecutive frame sequence, as a learning objective, we aim to bridge the gap between the past and the future. We propose two innovative methods to empower MLLMs with foresight minds, Foresight Pre-Training (FPT) and Foresight Instruction-Tuning (FIT), which are inspired by the modern learning paradigm of LLMs. Specifically, FPT jointly training various tasks centered on trajectories, enabling MLLMs to learn how to attend and predict entire trajectories from a given initial observation. Then, FIT requires MLLMs to first predict trajectories of related objects and then reason about potential future events based on them. Aided by FPT and FIT, we build a novel and unified MLLM named Merlin that supports multi-images input and analysis about potential actions of multiple objects for the future reasoning. Experimental results show Merlin powerful foresight minds with impressive performance on both future reasoning and visual comprehension tasks.
DreamLLM: Synergistic Multimodal Comprehension and Creation
Sep 20, 2023This paper presents DreamLLM, a learning framework that first achieves versatile Multimodal Large Language Models (MLLMs) empowered with frequently overlooked synergy between multimodal comprehension and creation. DreamLLM operates on two fundamental principles. The first focuses on the generative modeling of both language and image posteriors by direct sampling in the raw multimodal space. This approach circumvents the limitations and information loss inherent to external feature extractors like CLIP, and a more thorough multimodal understanding is obtained. Second, DreamLLM fosters the generation of raw, interleaved documents, modeling both text and image contents, along with unstructured layouts. This allows DreamLLM to learn all conditional, marginal, and joint multimodal distributions effectively. As a result, DreamLLM is the first MLLM capable of generating free-form interleaved content. Comprehensive experiments highlight DreamLLM's superior performance as a zero-shot multimodal generalist, reaping from the enhanced learning synergy.
ChatSpot: Bootstrapping Multimodal LLMs via Precise Referring Instruction Tuning
Jul 18, 2023Human-AI interactivity is a critical aspect that reflects the usability of multimodal large language models (MLLMs). However, existing end-to-end MLLMs only allow users to interact with them through language instructions, leading to the limitation of the interactive accuracy and efficiency. In this study, we present precise referring instructions that utilize diverse reference representations such as points and boxes as referring prompts to refer to the special region. This enables MLLMs to focus on the region of interest and achieve finer-grained interaction. Based on precise referring instruction, we propose ChatSpot, a unified end-to-end multimodal large language model that supports diverse forms of interactivity including mouse clicks, drag-and-drop, and drawing boxes, which provides a more flexible and seamless interactive experience. We also construct a multi-grained vision-language instruction-following dataset based on existing datasets and GPT-4 generating. Furthermore, we design a series of evaluation tasks to assess the effectiveness of region recognition and interaction. Experimental results showcase ChatSpot's promising performance.
GroupLane: End-to-End 3D Lane Detection with Channel-wise Grouping
Jul 18, 2023Efficiency is quite important for 3D lane detection due to practical deployment demand. In this work, we propose a simple, fast, and end-to-end detector that still maintains high detection precision. Specifically, we devise a set of fully convolutional heads based on row-wise classification. In contrast to previous counterparts, ours supports recognizing both vertical and horizontal lanes. Besides, our method is the first one to perform row-wise classification in bird-eye-view. In the heads, we split feature into multiple groups and every group of feature corresponds to a lane instance. During training, the predictions are associated with lane labels using the proposed single-win one-to-one matching to compute loss, and no post-processing operation is demanded for inference. In this way, our proposed fully convolutional detector, GroupLane, realizes end-to-end detection like DETR. Evaluated on 3 real world 3D lane benchmarks, OpenLane, Once-3DLanes, and OpenLane-Huawei, GroupLane adopting ConvNext-Base as the backbone outperforms the published state-of-the-art PersFormer by 13.6% F1 score in the OpenLane validation set. Besides, GroupLane with ResNet18 still surpasses PersFormer by 4.9% F1 score, while the inference speed is nearly 7x faster and the FLOPs is only 13.3% of it.
GMM: Delving into Gradient Aware and Model Perceive Depth Mining for Monocular 3D Detection
Jun 30, 2023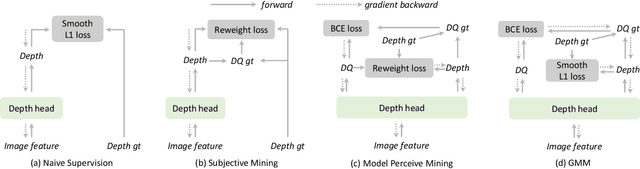
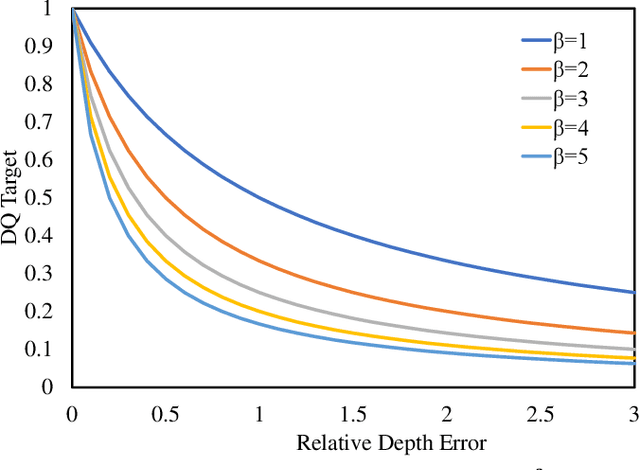
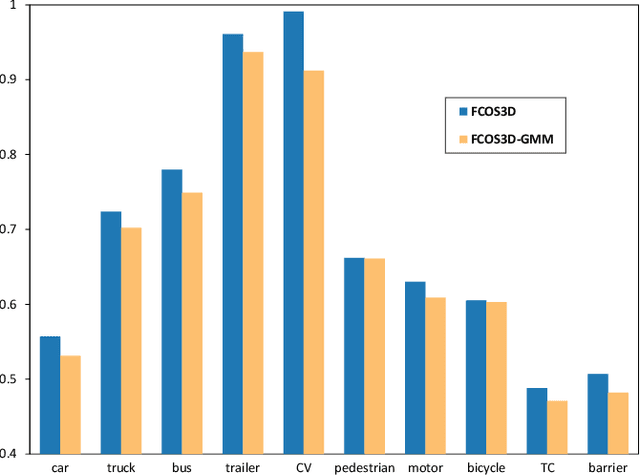
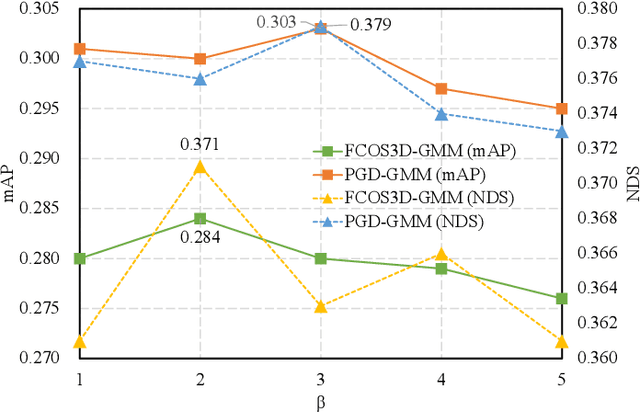
Depth perception is a crucial component of monoc-ular 3D detection tasks that typically involve ill-posed problems. In light of the success of sample mining techniques in 2D object detection, we propose a simple yet effective mining strategy for improving depth perception in 3D object detection. Concretely, we introduce a plain metric to evaluate the quality of depth predictions, which chooses the mined sample for the model. Moreover, we propose a Gradient-aware and Model-perceive Mining strategy (GMM) for depth learning, which exploits the predicted depth quality for better depth learning through easy mining. GMM is a general strategy that can be readily applied to several state-of-the-art monocular 3D detectors, improving the accuracy of depth prediction. Extensive experiments on the nuScenes dataset demonstrate that the proposed methods significantly improve the performance of 3D object detection while outperforming other state-of-the-art sample mining techniques by a considerable margin. On the nuScenes benchmark, GMM achieved the state-of-the-art (42.1% mAP and 47.3% NDS) performance in monocular object detection.