 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
Incremental Human-Object Interaction Detection with Invariant Relation Representation Learning
Oct 30, 2025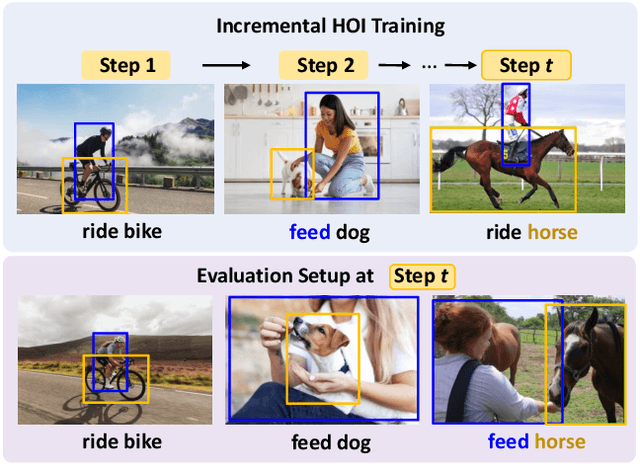
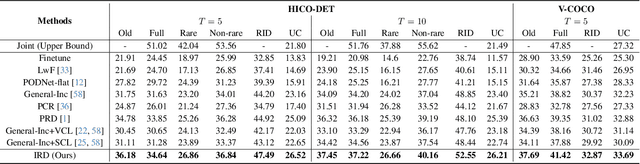
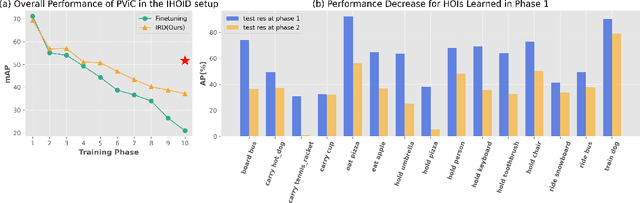
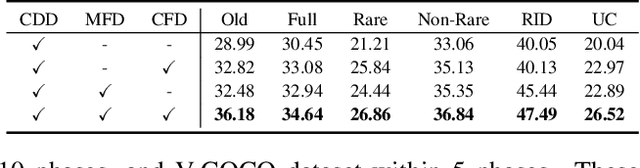
In open-world environments, human-object interactions (HOIs) evolve continuously, challenging conventional closed-world HOI detection models. Inspired by humans' ability to progressively acquire knowledge, we explore incremental HOI detection (IHOID) to develop agents capable of discerning human-object relations in such dynamic environments. This setup confronts not only the common issue of catastrophic forgetting in incremental learning but also distinct challenges posed by interaction drift and detecting zero-shot HOI combinations with sequentially arriving data. Therefore, we propose a novel exemplar-free incremental relation distillation (IRD) framework. IRD decouples the learning of objects and relations, and introduces two unique distillation losses for learning invariant relation features across different HOI combinations that share the same relation. Extensive experiments on HICO-DET and V-COCO datasets demonstrate the superiority of our method over state-of-the-art baselines in mitigating forgetting, strengthening robustness against interaction drift, and generalization on zero-shot HOIs. Code is available at \href{https://github.com/weiyana/ContinualHOI}{this HTTP URL}
Perception-R1: Pioneering Perception Policy with Reinforcement Learning
Apr 10, 2025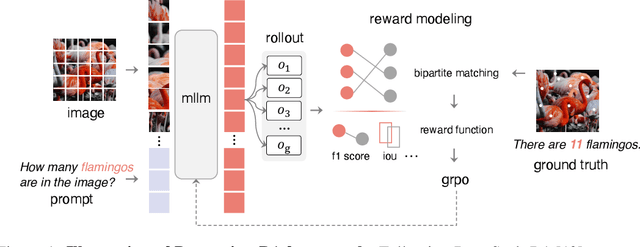
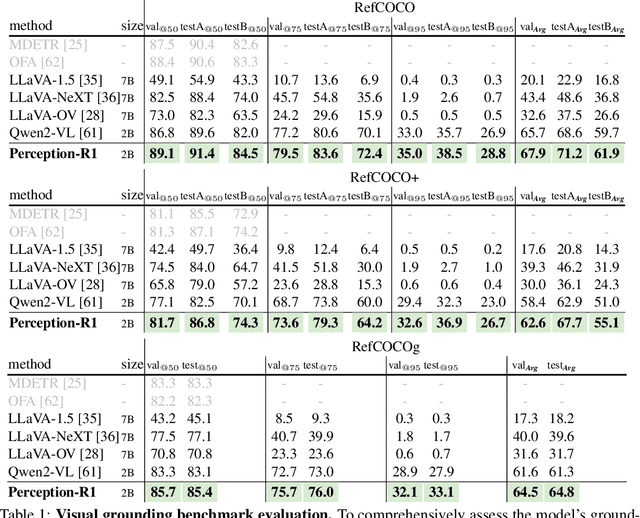
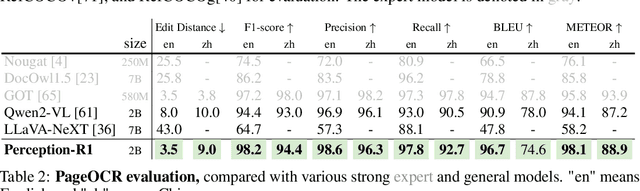
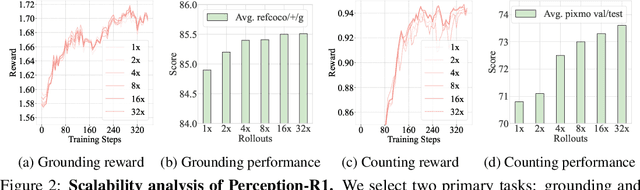
Inspired by the success of DeepSeek-R1, we explore the potential of rule-based reinforcement learning (RL) in MLLM post-training for perception policy learning. While promising, our initial experiments reveal that incorporating a thinking process through RL does not consistently lead to performance gains across all visual perception tasks. This leads us to delve into the essential role of RL in the context of visual perception. In this work, we return to the fundamentals and explore the effects of RL on different perception tasks. We observe that the perceptual complexity is a major factor in determining the effectiveness of RL. We also observe that reward design plays a crucial role in further approching the upper limit of model perception. To leverage these findings, we propose Perception-R1, a scalable RL framework using GRPO during MLLM post-training. With a standard Qwen2.5-VL-3B-Instruct, Perception-R1 achieves +4.2% on RefCOCO+, +17.9% on PixMo-Count, +4.2% on PageOCR, and notably, 31.9% AP on COCO2017 val for the first time, establishing a strong baseline for perception policy learning.
Perception in Reflection
Apr 09, 2025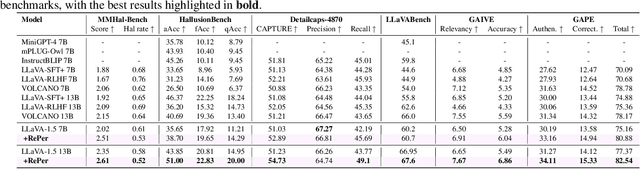



We present a perception in reflection paradigm designed to transcend the limitations of current large vision-language models (LVLMs), which are expected yet often fail to achieve perfect perception initially. Specifically, we propose Reflective Perception (RePer), a dual-model reflection mechanism that systematically alternates between policy and critic models, enables iterative refinement of visual perception. This framework is powered by Reflective Perceptual Learning (RPL), which reinforces intrinsic reflective capabilities through a methodically constructed visual reflection dataset and reflective unlikelihood training. Comprehensive experimental evaluation demonstrates RePer's quantifiable improvements in image understanding, captioning precision, and hallucination reduction. Notably, RePer achieves strong alignment between model attention patterns and human visual focus, while RPL optimizes fine-grained and free-form preference alignment. These advancements establish perception in reflection as a robust paradigm for future multimodal agents, particularly in tasks requiring complex reasoning and multi-step manipulation.
Unhackable Temporal Rewarding for Scalable Video MLLMs
Feb 17, 2025



In the pursuit of superior video-processing MLLMs, we have encountered a perplexing paradox: the "anti-scaling law", where more data and larger models lead to worse performance. This study unmasks the culprit: "temporal hacking", a phenomenon where models shortcut by fixating on select frames, missing the full video narrative. In this work, we systematically establish a comprehensive theory of temporal hacking, defining it from a reinforcement learning perspective, introducing the Temporal Perplexity (TPL) score to assess this misalignment, and proposing the Unhackable Temporal Rewarding (UTR) framework to mitigate the temporal hacking. Both theoretically and empirically, TPL proves to be a reliable indicator of temporal modeling quality, correlating strongly with frame activation patterns. Extensive experiments reveal that UTR not only counters temporal hacking but significantly elevates video comprehension capabilities. This work not only advances video-AI systems but also illuminates the critical importance of aligning proxy rewards with true objectives in MLLM development.
Merlin:Empowering Multimodal LLMs with Foresight Minds
Nov 30, 2023Humans possess the remarkable ability to foresee the future to a certain extent based on present observations, a skill we term as foresight minds. However, this capability remains largely under explored within existing Multimodal Large Language Models (MLLMs), hindering their capacity to learn the fundamental principles of how things operate and the intentions behind the observed subjects. To address this issue, we introduce the integration of future modeling into the existing learning frameworks of MLLMs. By utilizing the subject trajectory, a highly structured representation of a consecutive frame sequence, as a learning objective, we aim to bridge the gap between the past and the future. We propose two innovative methods to empower MLLMs with foresight minds, Foresight Pre-Training (FPT) and Foresight Instruction-Tuning (FIT), which are inspired by the modern learning paradigm of LLMs. Specifically, FPT jointly training various tasks centered on trajectories, enabling MLLMs to learn how to attend and predict entire trajectories from a given initial observation. Then, FIT requires MLLMs to first predict trajectories of related objects and then reason about potential future events based on them. Aided by FPT and FIT, we build a novel and unified MLLM named Merlin that supports multi-images input and analysis about potential actions of multiple objects for the future reasoning. Experimental results show Merlin powerful foresight minds with impressive performance on both future reasoning and visual comprehension tasks.
Grounded Image Text Matching with Mismatched Relation Reasoning
Aug 04, 2023


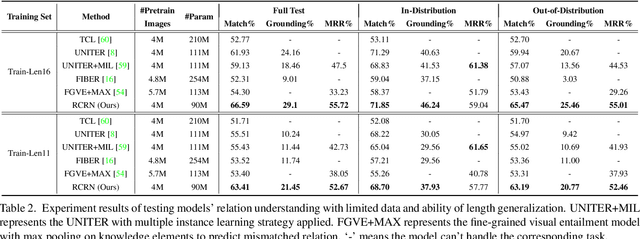
This paper introduces Grounded Image Text Matching with Mismatched Relation (GITM-MR), a novel visual-linguistic joint task that evaluates the relation understanding capabilities of transformer-based pre-trained models. GITM-MR requires a model to first determine if an expression describes an image, then localize referred objects or ground the mismatched parts of the text. We provide a benchmark for evaluating pre-trained models on this task, with a focus on the challenging settings of limited data and out-of-distribution sentence lengths. Our evaluation demonstrates that pre-trained models lack data efficiency and length generalization ability. To address this, we propose the Relation-sensitive Correspondence Reasoning Network (RCRN), which incorporates relation-aware reasoning via bi-directional message propagation guided by language structure. RCRN can be interpreted as a modular program and delivers strong performance in both length generalization and data efficiency.