 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehensive Benchmarking of Long-Form Speech Generation in Diverse Scenarios
May 27, 2026Recent advances in speech generation have enabled high-fidelity synthesis, yet systematic evaluation of models under long-context conditions remains largely underexplored. A comprehensive evaluation benchmark for long-form speech is indispensable for two reasons: 1) existing test scenarios are often confined to limited domains, creating a significant gap with the diverse downstream applications; 2) existing metrics overlook critical long-text factors such as consistency and coherence, failing to generalize reliably. To this end, we propose Swanbench-Speech, a comprehensive benchmark that decomposes long-form speech quality into specific, disentangled dimensions. SwanBench-Speech has three key properties. 1) Rich speech scenarios: Focusing on long-form speech generation and dialog generation, SwanBench-Speech covers acoustics, semantics, and expressiveness challenges, and consists of 1,101 samples spanning 17 common speech scenarios; 2) Comprehensive evaluation dimensions: Along the acoustics, semantics, and expressiveness axes, SwanBench-Speech defines an automated evaluation protocol with seven metrics to provide a comprehensive, accurate, and standardized assessment; 3) Valuable Insights: Through extensive experiments, we reveal that current models still struggle in highly expressive scenarios and exhibit a notable gap in consistency and hierarchy compared to real recordings.
Part-Aware Open-Vocabulary 3D Affordance Grounding via Prototypical Semantic and Geometric Alignment
Mar 18, 2026Grounding natural language questions to functionally relevant regions in 3D objects -- termed language-driven 3D affordance grounding -- is essential for embodied intelligence and human-AI interaction. Existing methods, while progressing from label-based to language-driven approaches, still face challenges in open-vocabulary generalization, fine-grained geometric alignment, and part-level semantic consistency. To address these issues, we propose a novel two-stage cross-modal framework that enhances both semantic and geometric representations for open-vocabulary 3D affordance grounding. In the first stage, large language models generate part-aware instructions to recover missing semantics, enabling the model to link semantically similar affordances. In the second stage, we introduce two key components: Affordance Prototype Aggregation (APA), which captures cross-object geometric consistency for each affordance, and Intra-Object Relational Modeling (IORM), which refines geometric differentiation within objects to support precise semantic alignment. We validate the effectiveness of our method through extensive experiments on a newly introduced benchmark, as well as two existing benchmarks, demonstrating superior performance in comparison with existing methods.
WikiCLIP: An Efficient Contrastive Baseline for Open-domain Visual Entity Recognition
Mar 10, 2026Open-domain visual entity recognition (VER) seeks to associate images with entities in encyclopedic knowledge bases such as Wikipedia. Recent generative methods tailored for VER demonstrate strong performance but incur high computational costs, limiting their scalability and practical deployment. In this work, we revisit the contrastive paradigm for VER and introduce WikiCLIP, a simple yet effective framework that establishes a strong and efficient baseline for open-domain VER. WikiCLIP leverages large language model embeddings as knowledge-rich entity representations and enhances them with a Vision-Guided Knowledge Adaptor (VGKA) that aligns textual semantics with visual cues at the patch level. To further encourage fine-grained discrimination, a Hard Negative Synthesis Mechanism generates visually similar but semantically distinct negatives during training. Experimental results on popular open-domain VER benchmarks, such as OVEN, demonstrate that WikiCLIP significantly outperforms strong baselines. Specifically, WikiCLIP achieves a 16% improvement on the challenging OVEN unseen set, while reducing inference latency by nearly 100 times compared with the leading generative model, AutoVER. The project page is available at https://artanic30.github.io/project_pages/WikiCLIP/
AffordGrasp: Cross-Modal Diffusion for Affordance-Aware Grasp Synthesis
Mar 09, 2026Generating human grasping poses that accurately reflect both object geometry and user-specified interaction semantics is essential for natural hand-object interactions in AR/VR and embodied AI. However, existing semantic grasping approaches struggle with the large modality gap between 3D object representations and textual instructions, and often lack explicit spatial or semantic constraints, leading to physically invalid or semantically inconsistent grasps. In this work, we present AffordGrasp, a diffusion-based framework that produces physically stable and semantically faithful human grasps with high precision. We first introduce a scalable annotation pipeline that automatically enriches hand-object interaction datasets with fine-grained structured language labels capturing interaction intent. Building upon these annotations, AffordGrasp integrates an affordance-aware latent representation of hand poses with a dual-conditioning diffusion process, enabling the model to jointly reason over object geometry, spatial affordances, and instruction semantics. A distribution adjustment module further enforces physical contact consistency and semantic alignment. We evaluate AffordGrasp across four instruction-augmented benchmarks derived from HO-3D, OakInk, GRAB, and AffordPose, and observe substantial improvements over state-of-the-art methods in grasp quality, semantic accuracy, and diversity.
Wiki-R1: Incentivizing Multimodal Reasoning for Knowledge-based VQA via Data and Sampling Curriculum
Mar 05, 2026Knowledge-Based Visual Question Answering (KB-VQA) requires models to answer questions about an image by integrating external knowledge, posing significant challenges due to noisy retrieval and the structured, encyclopedic nature of the knowledge base. These characteristics create a distributional gap from pretrained multimodal large language models (MLLMs), making effective reasoning and domain adaptation difficult in the post-training stage. In this work, we propose \textit{Wiki-R1}, a data-generation-based curriculum reinforcement learning framework that systematically incentivizes reasoning in MLLMs for KB-VQA. Wiki-R1 constructs a sequence of training distributions aligned with the model's evolving capability, bridging the gap from pretraining to the KB-VQA target distribution. We introduce \textit{controllable curriculum data generation}, which manipulates the retriever to produce samples at desired difficulty levels, and a \textit{curriculum sampling strategy} that selects informative samples likely to yield non-zero advantages during RL updates. Sample difficulty is estimated using observed rewards and propagated to unobserved samples to guide learning. Experiments on two KB-VQA benchmarks, Encyclopedic VQA and InfoSeek, demonstrate that Wiki-R1 achieves new state-of-the-art results, improving accuracy from 35.5\% to 37.1\% on Encyclopedic VQA and from 40.1\% to 44.1\% on InfoSeek. The project page is available at https://artanic30.github.io/project_pages/WikiR1/.
DA-DPO: Cost-efficient Difficulty-aware Preference Optimization for Reducing MLLM Hallucinations
Jan 02, 2026Direct Preference Optimization (DPO) has shown strong potential for mitigating hallucinations in Multimodal Large Language Models (MLLMs). However, existing multimodal DPO approaches often suffer from overfitting due to the difficulty imbalance in preference data. Our analysis shows that MLLMs tend to overemphasize easily distinguishable preference pairs, which hinders fine-grained hallucination suppression and degrades overall performance. To address this issue, we propose Difficulty-Aware Direct Preference Optimization (DA-DPO), a cost-effective framework designed to balance the learning process. DA-DPO consists of two main components: (1) Difficulty Estimation leverages pre-trained vision--language models with complementary generative and contrastive objectives, whose outputs are integrated via a distribution-aware voting strategy to produce robust difficulty scores without additional training; and (2) Difficulty-Aware Training reweights preference pairs based on their estimated difficulty, down-weighting easy samples while emphasizing harder ones to alleviate overfitting. This framework enables more effective preference optimization by prioritizing challenging examples, without requiring new data or extra fine-tuning stages. Extensive experiments demonstrate that DA-DPO consistently improves multimodal preference optimization, yielding stronger robustness to hallucinations and better generalization across standard benchmarks, while remaining computationally efficient. The project page is available at https://artanic30.github.io/project_pages/DA-DPO/.
Omni-Weather: Unified Multimodal Foundation Model for Weather Generation and Understanding
Dec 25, 2025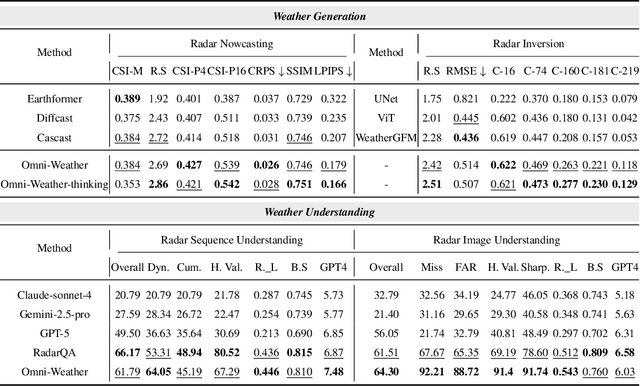
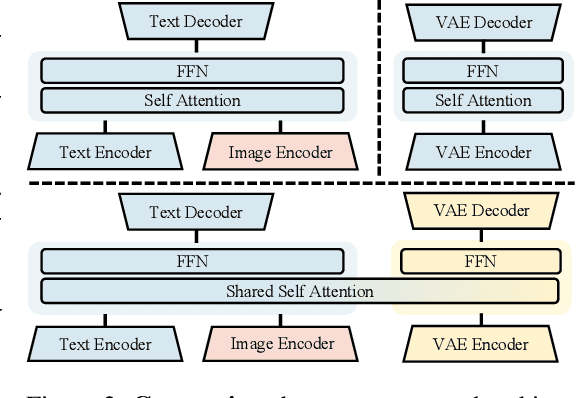
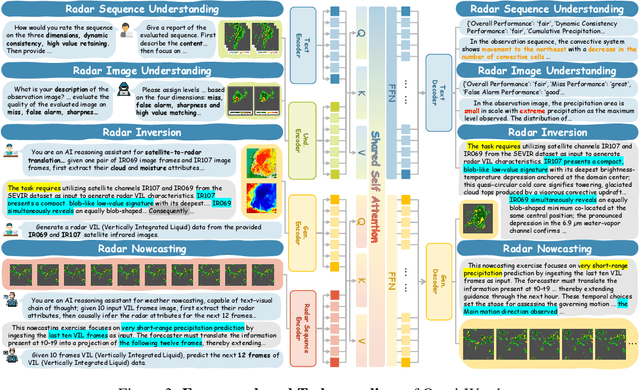

Weather modeling requires both accurate prediction and mechanistic interpretation, yet existing methods treat these goals in isolation, separating generation from understanding. To address this gap, we present Omni-Weather, the first multimodal foundation model that unifies weather generation and understanding within a single architecture. Omni-Weather integrates a radar encoder for weather generation tasks, followed by unified processing using a shared self-attention mechanism. Moreover, we construct a Chain-of-Thought dataset for causal reasoning in weather generation, enabling interpretable outputs and improved perceptual quality. Extensive experiments show Omni-Weather achieves state-of-the-art performance in both weather generation and understanding. Our findings further indicate that generative and understanding tasks in the weather domain can mutually enhance each other. Omni-Weather also demonstrates the feasibility and value of unifying weather generation and understanding.
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
GUI-Rise: Structured Reasoning and History Summarization for GUI Navigation
Oct 31, 2025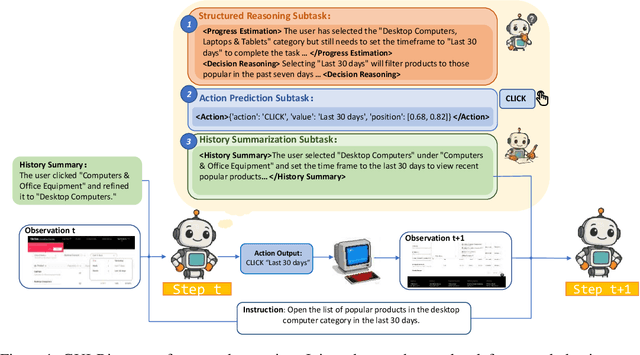
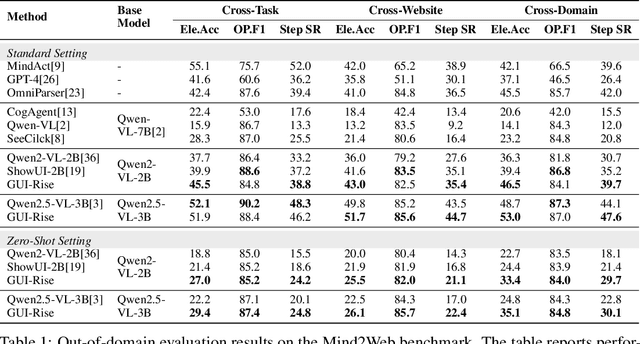
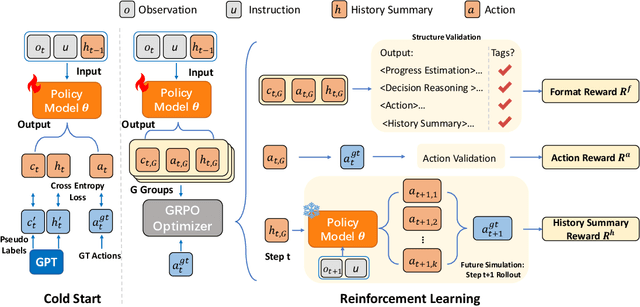
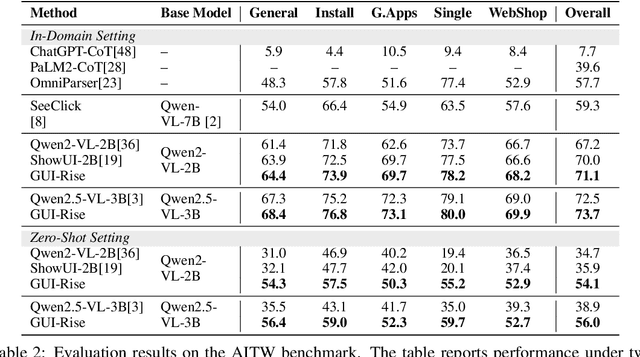
While Multimodal Large Language Models (MLLMs) have advanced GUI navigation agents, current approaches face limitations in cross-domain generalization and effective history utilization. We present a reasoning-enhanced framework that systematically integrates structured reasoning, action prediction, and history summarization. The structured reasoning component generates coherent Chain-of-Thought analyses combining progress estimation and decision reasoning, which inform both immediate action predictions and compact history summaries for future steps. Based on this framework, we train a GUI agent, \textbf{GUI-Rise}, through supervised fine-tuning on pseudo-labeled trajectories and reinforcement learning with Group Relative Policy Optimization (GRPO). This framework employs specialized rewards, including a history-aware objective, directly linking summary quality to subsequent action performance. Comprehensive evaluations on standard benchmarks demonstrate state-of-the-art results under identical training data conditions, with particularly strong performance in out-of-domain scenarios. These findings validate our framework's ability to maintain robust reasoning and generalization across diverse GUI navigation tasks. Code is available at https://leon022.github.io/GUI-Rise.
Incremental Human-Object Interaction Detection with Invariant Relation Representation Learning
Oct 30, 2025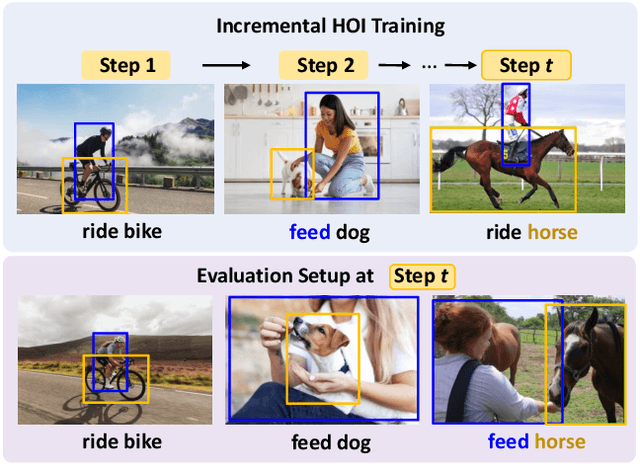
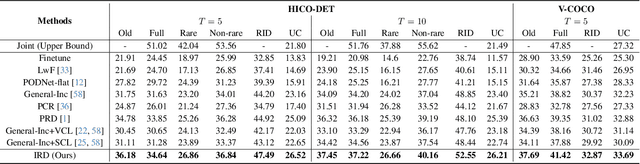
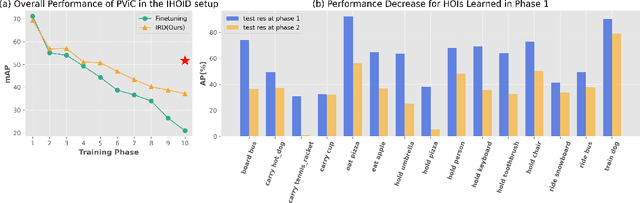
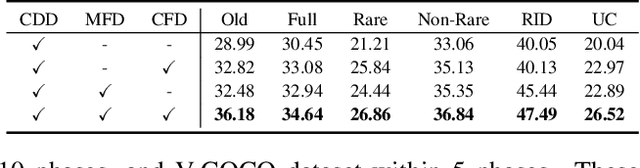
In open-world environments, human-object interactions (HOIs) evolve continuously, challenging conventional closed-world HOI detection models. Inspired by humans' ability to progressively acquire knowledge, we explore incremental HOI detection (IHOID) to develop agents capable of discerning human-object relations in such dynamic environments. This setup confronts not only the common issue of catastrophic forgetting in incremental learning but also distinct challenges posed by interaction drift and detecting zero-shot HOI combinations with sequentially arriving data. Therefore, we propose a novel exemplar-free incremental relation distillation (IRD) framework. IRD decouples the learning of objects and relations, and introduces two unique distillation losses for learning invariant relation features across different HOI combinations that share the same relation. Extensive experiments on HICO-DET and V-COCO datasets demonstrate the superiority of our method over state-of-the-art baselines in mitigating forgetting, strengthening robustness against interaction drift, and generalization on zero-shot HOIs. Code is available at \href{https://github.com/weiyana/ContinualHOI}{this HTTP URL}