 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUI-Rise: Structured Reasoning and History Summarization for GUI Navigation
Oct 31, 2025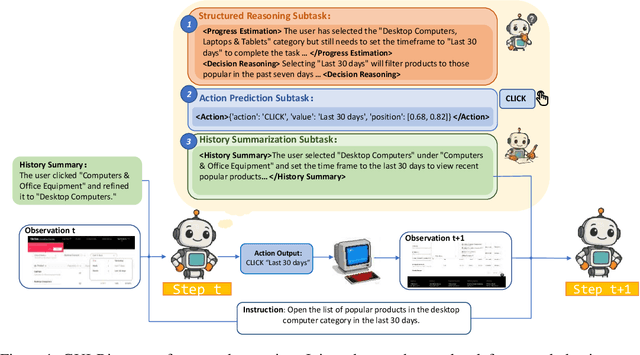
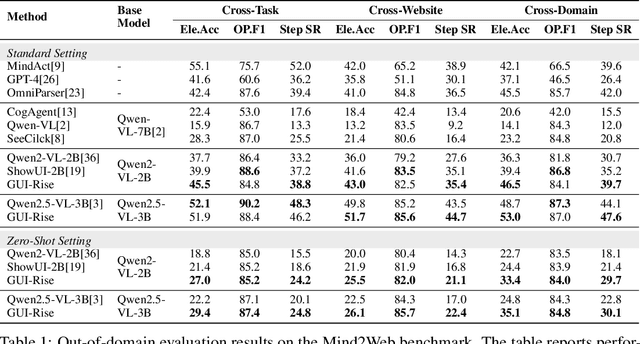
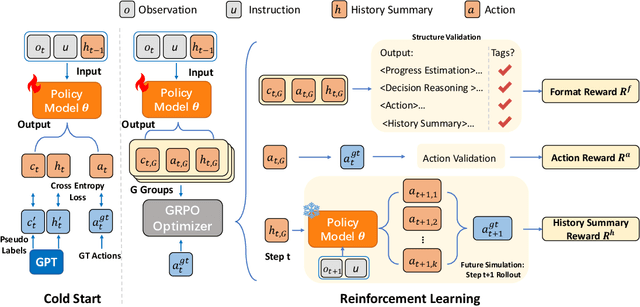
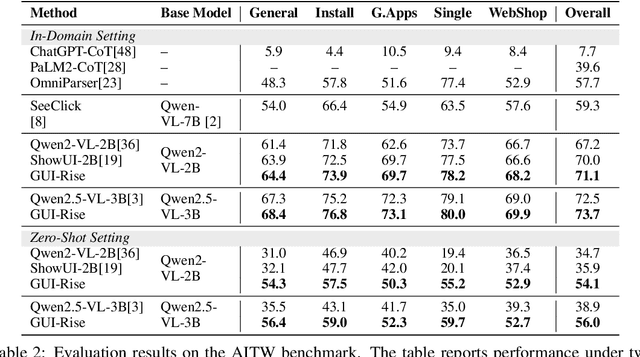
While Multimodal Large Language Models (MLLMs) have advanced GUI navigation agents, current approaches face limitations in cross-domain generalization and effective history utilization. We present a reasoning-enhanced framework that systematically integrates structured reasoning, action prediction, and history summarization. The structured reasoning component generates coherent Chain-of-Thought analyses combining progress estimation and decision reasoning, which inform both immediate action predictions and compact history summaries for future steps. Based on this framework, we train a GUI agent, \textbf{GUI-Rise}, through supervised fine-tuning on pseudo-labeled trajectories and reinforcement learning with Group Relative Policy Optimization (GRPO). This framework employs specialized rewards, including a history-aware objective, directly linking summary quality to subsequent action performance. Comprehensive evaluations on standard benchmarks demonstrate state-of-the-art results under identical training data conditions, with particularly strong performance in out-of-domain scenarios. These findings validate our framework's ability to maintain robust reasoning and generalization across diverse GUI navigation tasks. Code is available at https://leon022.github.io/GUI-Rise.
Relation-aware Hierarchical Prompt for Open-vocabulary Scene Graph Generation
Dec 26, 2024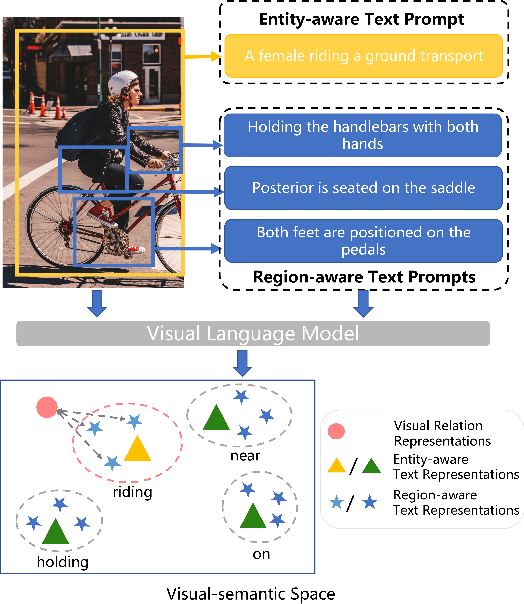
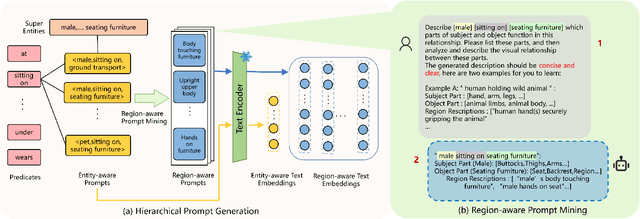

Open-vocabulary Scene Graph Generation (OV-SGG) overcomes the limitations of the closed-set assumption by aligning visual relationship representations with open-vocabulary textual representations. This enables the identification of novel visual relationships, making it applicable to real-world scenarios with diverse relationships. However, existing OV-SGG methods are constrained by fixed text representations, limiting diversity and accuracy in image-text alignment. To address these challenges, we propose the Relation-Aware Hierarchical Prompting (RAHP) framework, which enhances text representation by integrating subject-object and region-specific relation information. Our approach utilizes entity clustering to address the complexity of relation triplet categories, enabling the effective integration of subject-object information. Additionally, we utilize a large language model (LLM) to generate detailed region-aware prompts, capturing fine-grained visual interactions and improving alignment between visual and textual modalities. RAHP also introduces a dynamic selection mechanism within Vision-Language Models (VLMs), which adaptively selects relevant text prompts based on the visual content, reducing noise from irrelevant prompts. Extensive experiments on the Visual Genome and Open Images v6 datasets demonstrate that our framework consistently achieves state-of-the-art performance, demonstrating its effectiveness in addressing the challenges of open-vocabulary scene graph generation.
From Pixels to Graphs: Open-Vocabulary Scene Graph Generation with Vision-Language Models
Apr 06, 2024Scene graph generation (SGG) aims to parse a visual scene into an intermediate graph representation for downstream reasoning tasks. Despite recent advancements, existing methods struggle to generate scene graphs with novel visual relation concepts. To address this challenge, we introduce a new open-vocabulary SGG framework based on sequence generation. Our framework leverages vision-language pre-trained models (VLM) by incorporating an image-to-graph generation paradigm. Specifically, we generate scene graph sequences via image-to-text generation with VLM and then construct scene graphs from these sequences. By doing so, we harness the strong capabilities of VLM for open-vocabulary SGG and seamlessly integrate explicit relational modeling for enhancing the VL tasks. Experimental results demonstrate that our design not only achieves superior performance with an open vocabulary but also enhances downstream vision-language task performance through explicit relation modeling knowledge.
Learning by Correction: Efficient Tuning Task for Zero-Shot Generative Vision-Language Reasoning
Apr 01, 2024Generative vision-language models (VLMs) have shown impressive performance in zero-shot vision-language tasks like image captioning and visual question answering. However, improving their zero-shot reasoning typically requires second-stage instruction tuning, which relies heavily on human-labeled or large language model-generated annotation, incurring high labeling costs. To tackle this challenge, we introduce Image-Conditioned Caption Correction (ICCC), a novel pre-training task designed to enhance VLMs' zero-shot performance without the need for labeled task-aware data. The ICCC task compels VLMs to rectify mismatches between visual and language concepts, thereby enhancing instruction following and text generation conditioned on visual inputs. Leveraging language structure and a lightweight dependency parser, we construct data samples of ICCC task from image-text datasets with low labeling and computation costs. Experimental results on BLIP-2 and InstructBLIP demonstrate significant improvements in zero-shot image-text generation-based VL tasks through ICCC instruction tuning.
SGTR+: End-to-end Scene Graph Generation with Transformer
Jan 23, 2024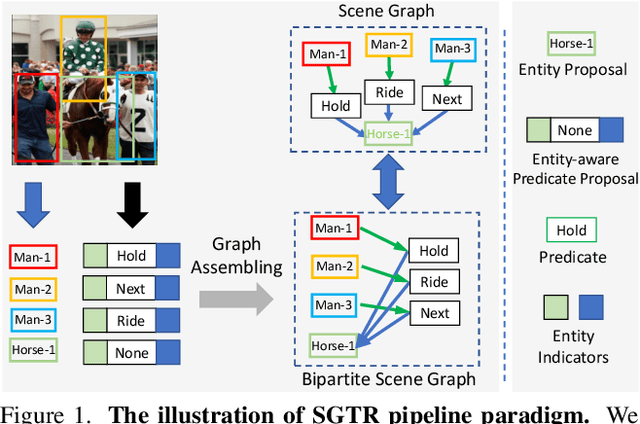
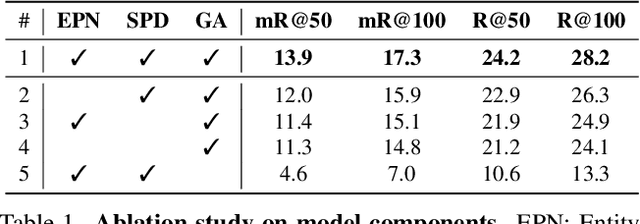
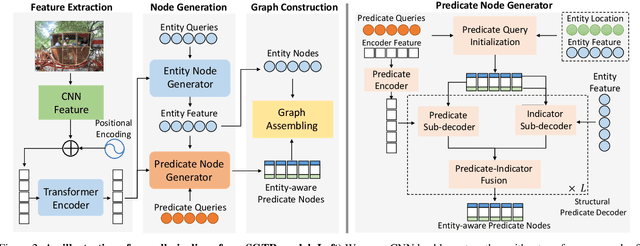

Scene Graph Generation (SGG) remains a challenging visual understanding task due to its compositional property. Most previous works adopt a bottom-up, two-stage or point-based, one-stage approach, which often suffers from high time complexity or suboptimal designs. In this work, we propose a novel SGG method to address the aforementioned issues, formulating the task as a bipartite graph construction problem. To address the issues above, we create a transformer-based end-to-end framework to generate the entity and entity-aware predicate proposal set, and infer directed edges to form relation triplets. Moreover, we design a graph assembling module to infer the connectivity of the bipartite scene graph based on our entity-aware structure, enabling us to generate the scene graph in an end-to-end manner. Based on bipartite graph assembling paradigm, we further propose a new technical design to address the efficacy of entity-aware modeling and optimization stability of graph assembling. Equipped with the enhanced entity-aware design, our method achieves optimal performance and time-complexity. Extensive experimental results show that our design is able to achieve the state-of-the-art or comparable performance on three challenging benchmarks, surpassing most of the existing approaches and enjoying higher efficiency in inference. Code is available: https://github.com/Scarecrow0/SGTR
SGTR: End-to-end Scene Graph Generation with Transformer
Dec 30, 2021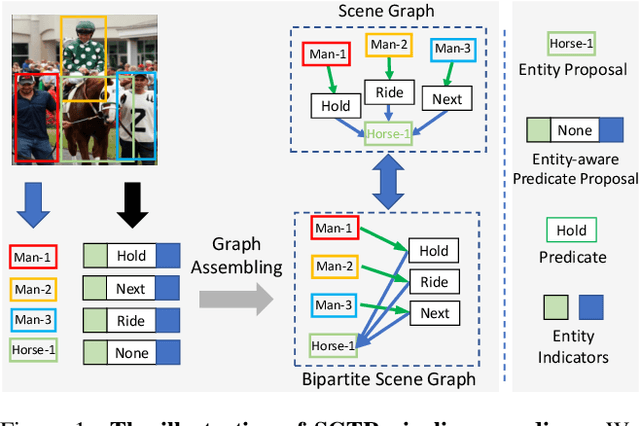
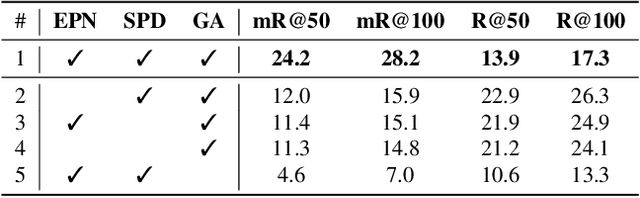
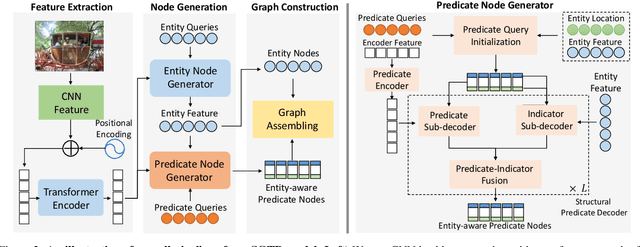

Scene Graph Generation (SGG) remains a challenging visual understanding task due to its complex compositional property. Most previous works adopt a bottom-up two-stage or a point-based one-stage approach, which often suffers from overhead time complexity or sub-optimal design assumption. In this work, we propose a novel SGG method to address the aforementioned issues, which formulates the task as a bipartite graph construction problem. To solve the problem, we develop a transformer-based end-to-end framework that first generates the entity and predicate proposal set, followed by inferring directed edges to form the relation triplets. In particular, we develop a new entity-aware predicate representation based on a structural predicate generator to leverage the compositional property of relationships. Moreover, we design a graph assembling module to infer the connectivity of the bipartite scene graph based on our entity-aware structure, enabling us to generate the scene graph in an end-to-end manner. Extensive experimental results show that our design is able to achieve the state-of-the-art or comparable performance on two challenging benchmarks, surpassing most of the existing approaches and enjoying higher efficiency in inference. We hope our model can serve as a strong baseline for the Transformer-based scene graph generation.
Bipartite Graph Network with Adaptive Message Passing for Unbiased Scene Graph Generation
Apr 29, 2021
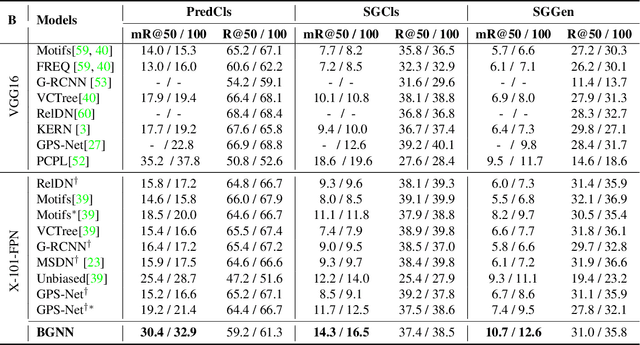
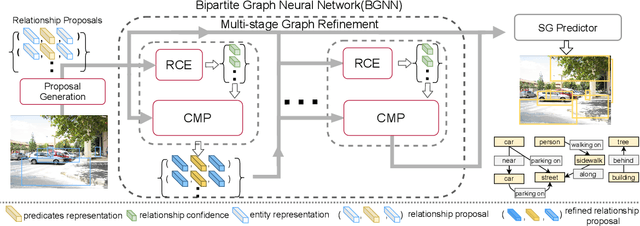
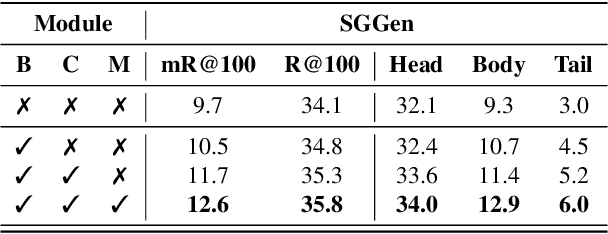
Scene graph generation is an important visual understanding task with a broad range of vision applications. Despite recent tremendous progress, it remains challenging due to the intrinsic long-tailed class distribution and large intra-class variation. To address these issues, we introduce a novel confidence-aware bipartite graph neural network with adaptive message propagation mechanism for unbiased scene graph generation. In addition, we propose an efficient bi-level data resampling strategy to alleviate the imbalanced data distribution problem in training our graph network. Our approach achieves superior or competitive performance over previous methods on several challenging datasets, including Visual Genome, Open Images V4/V6, demonstrating its effectiveness and generality.
Pose-aware Multi-level Feature Network for Human Object Interaction Detection
Sep 18, 2019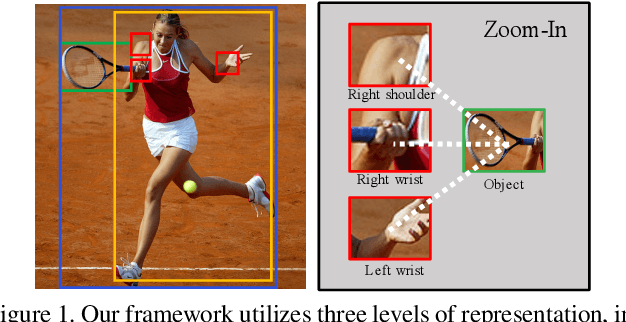
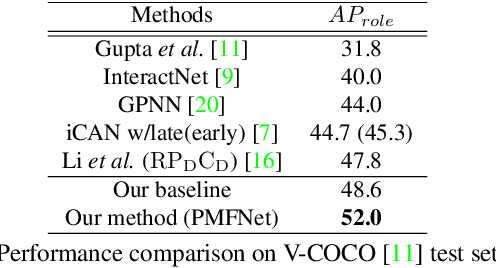
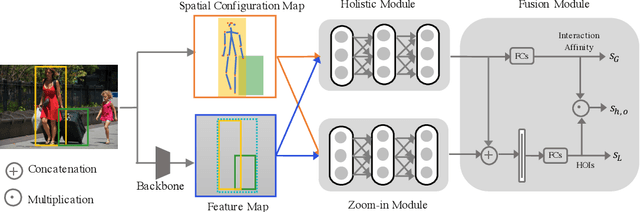
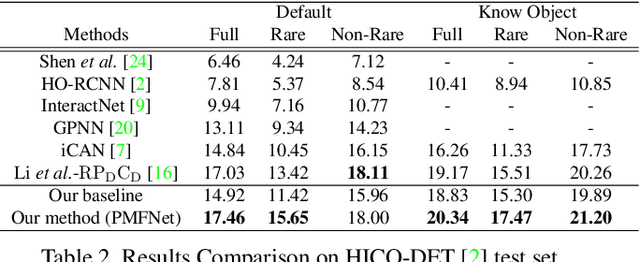
Reasoning human object interactions is a core problem in human-centric scene understanding and detecting such relations poses a unique challenge to vision systems due to large variations in human-object configurations, multiple co-occurring relation instances and subtle visual difference between relation categories. To address those challenges, we propose a multi-level relation detection strategy that utilizes human pose cues to capture global spatial configurations of relations and as an attention mechanism to dynamically zoom into relevant regions at human part level. Specifically, we develop a multi-branch deep network to learn a pose-augmented relation representation at three semantic levels, incorporating interaction context, object features and detailed semantic part cues. As a result, our approach is capable of generating robust predictions on fine-grained human object interactions with interpretable outputs. Extensive experimental evaluations on public benchmarks show that our model outperforms prior methods by a considerable margin, demonstrating its efficacy in handling complex scenes.