 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-supervised HOI Detection via Prior-guided Bi-level Representation Learning
Mar 02, 2023



Human object interaction (HOI) detection plays a crucial role in human-centric scene understanding and serves as a fundamental building-block for many vision tasks. One generalizable and scalable strategy for HOI detection is to use weak supervision, learning from image-level annotations only. This is inherently challenging due to ambiguous human-object associations, large search space of detecting HOIs and highly noisy training signal. A promising strategy to address those challenges is to exploit knowledge from large-scale pretrained models (e.g., CLIP), but a direct knowledge distillation strategy~\citep{liao2022gen} does not perform well on the weakly-supervised setting. In contrast, we develop a CLIP-guided HOI representation capable of incorporating the prior knowledge at both image level and HOI instance level, and adopt a self-taught mechanism to prune incorrect human-object associations. Experimental results on HICO-DET and V-COCO show that our method outperforms the previous works by a sizable margin, showing the efficacy of our HOI representation.
Temporal Segment Transformer for Action Segmentation
Feb 25, 2023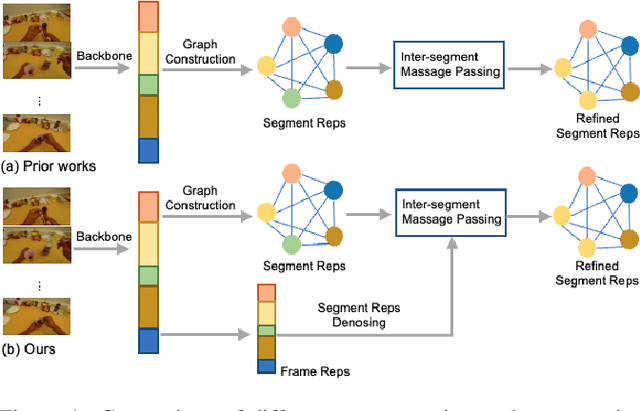



Recognizing human actions from untrimmed videos is an important task in activity understanding, and poses unique challenges in modeling long-range temporal relations. Recent works adopt a predict-and-refine strategy which converts an initial prediction to action segments for global context modeling. However, the generated segment representations are often noisy and exhibit inaccurate segment boundaries, over-segmentation and other problems. To deal with these issues, we propose an attention based approach which we call \textit{temporal segment transformer}, for joint segment relation modeling and denoising. The main idea is to denoise segment representations using attention between segment and frame representations, and also use inter-segment attention to capture temporal correlations between segments. The refined segment representations are used to predict action labels and adjust segment boundaries, and a final action segmentation is produced based on voting from segment masks. We show that this novel architecture achieves state-of-the-art accuracy on the popular 50Salads, GTEA and Breakfast benchmarks. We also conduct extensive ablations to demonstrate the effectiveness of different components of our design.
Part-aware Prototypical Graph Network for One-shot Skeleton-based Action Recognition
Aug 19, 2022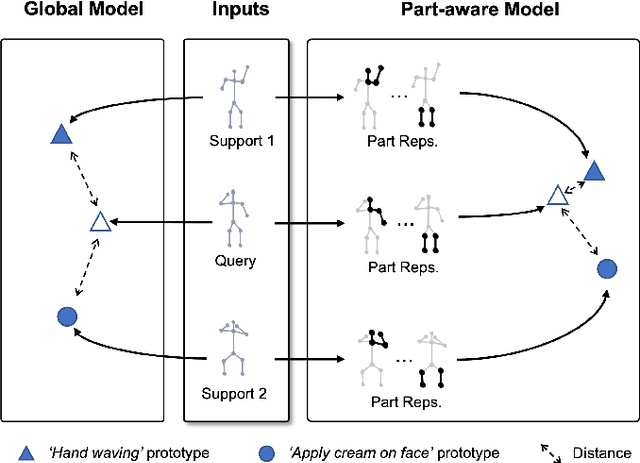
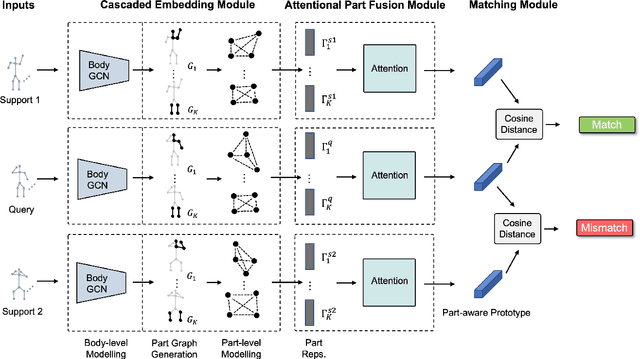
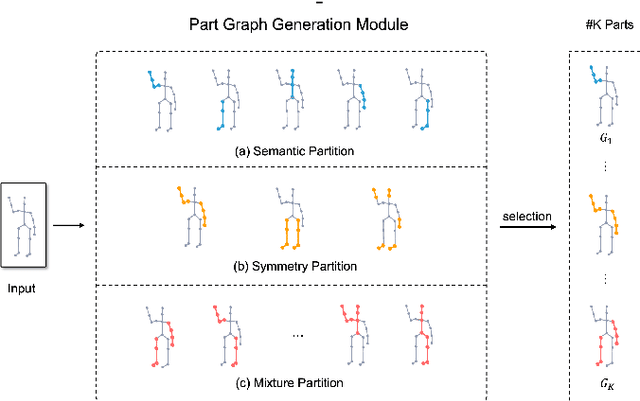
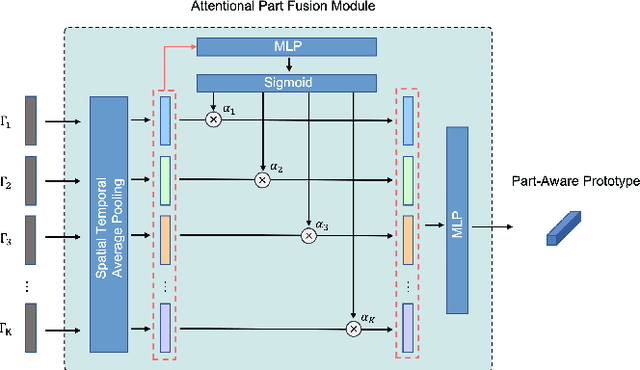
In this paper, we study the problem of one-shot skeleton-based action recognition, which poses unique challenges in learning transferable representation from base classes to novel classes, particularly for fine-grained actions. Existing meta-learning frameworks typically rely on the body-level representations in spatial dimension, which limits the generalisation to capture subtle visual differences in the fine-grained label space. To overcome the above limitation, we propose a part-aware prototypical representation for one-shot skeleton-based action recognition. Our method captures skeleton motion patterns at two distinctive spatial levels, one for global contexts among all body joints, referred to as body level, and the other attends to local spatial regions of body parts, referred to as the part level. We also devise a class-agnostic attention mechanism to highlight important parts for each action class. Specifically, we develop a part-aware prototypical graph network consisting of three modules: a cascaded embedding module for our dual-level modelling, an attention-based part fusion module to fuse parts and generate part-aware prototypes, and a matching module to perform classification with the part-aware representations. We demonstrate the effectiveness of our method on two public skeleton-based action recognition datasets: NTU RGB+D 120 and NW-UCLA.
Action Quality Assessment with Temporal Parsing Transformer
Jul 19, 2022
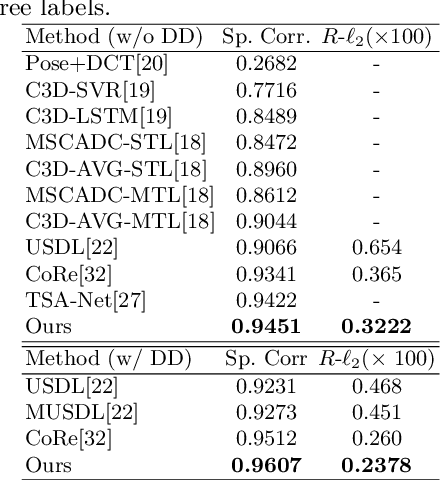
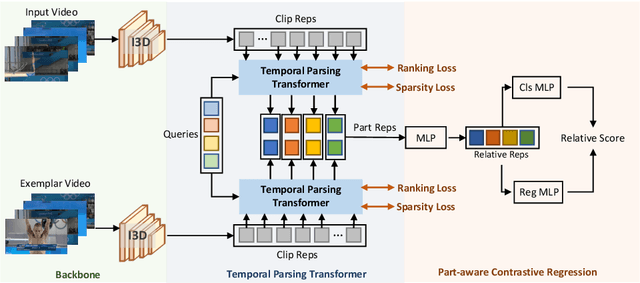

Action Quality Assessment(AQA) is important for action understanding and resolving the task poses unique challenges due to subtle visual differences. Existing state-of-the-art methods typically rely on the holistic video representations for score regression or ranking, which limits the generalization to capture fine-grained intra-class variation. To overcome the above limitation, we propose a temporal parsing transformer to decompose the holistic feature into temporal part-level representations. Specifically, we utilize a set of learnable queries to represent the atomic temporal patterns for a specific action. Our decoding process converts the frame representations to a fixed number of temporally ordered part representations. To obtain the quality score, we adopt the state-of-the-art contrastive regression based on the part representations. Since existing AQA datasets do not provide temporal part-level labels or partitions, we propose two novel loss functions on the cross attention responses of the decoder: a ranking loss to ensure the learnable queries to satisfy the temporal order in cross attention and a sparsity loss to encourage the part representations to be more discriminative. Extensive experiments show that our proposed method outperforms prior work on three public AQA benchmarks by a considerable margin.
Automatic spinal curvature measurement on ultrasound spine images using Faster R-CNN
Apr 20, 2022
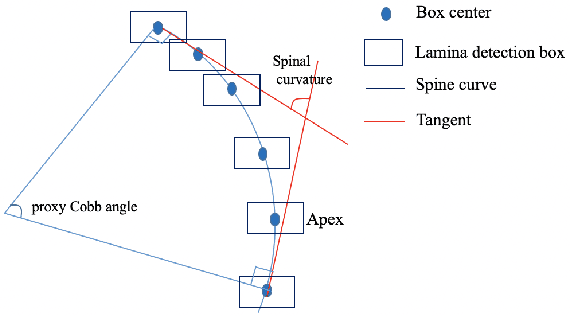

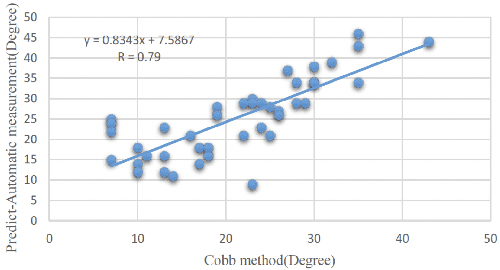
Ultrasound spine imaging technique has been applied to the assessment of spine deformity. However, manual measurements of scoliotic angles on ultrasound images are time-consuming and heavily rely on raters experience. The objectives of this study are to construct a fully automatic framework based on Faster R-CNN for detecting vertebral lamina and to measure the fitting spinal curves from the detected lamina pairs. The framework consisted of two closely linked modules: 1) the lamina detector for identifying and locating each lamina pairs on ultrasound coronal images, and 2) the spinal curvature estimator for calculating the scoliotic angles based on the chain of detected lamina. Two hundred ultrasound images obtained from AIS patients were identified and used for the training and evaluation of the proposed method. The experimental results showed the 0.76 AP on the test set, and the Mean Absolute Difference (MAD) between automatic and manual measurement which was within the clinical acceptance error. Meanwhile the correlation between automatic measurement and Cobb angle from radiographs was 0.79. The results revealed that our proposed technique could provide accurate and reliable automatic curvature measurements on ultrasound spine images for spine deformities.
Human-Object Interaction Detection via Disentangled Transformer
Apr 20, 2022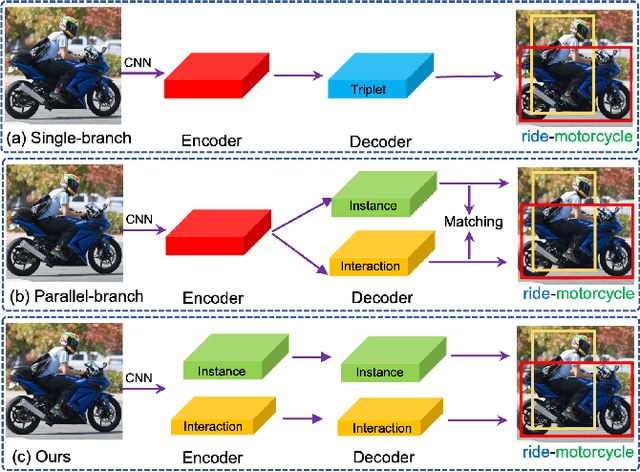



Human-Object Interaction Detection tackles the problem of joint localization and classification of human object interactions. Existing HOI transformers either adopt a single decoder for triplet prediction, or utilize two parallel decoders to detect individual objects and interactions separately, and compose triplets by a matching process. In contrast, we decouple the triplet prediction into human-object pair detection and interaction classification. Our main motivation is that detecting the human-object instances and classifying interactions accurately needs to learn representations that focus on different regions. To this end, we present Disentangled Transformer, where both encoder and decoder are disentangled to facilitate learning of two sub-tasks. To associate the predictions of disentangled decoders, we first generate a unified representation for HOI triplets with a base decoder, and then utilize it as input feature of each disentangled decoder. Extensive experiments show that our method outperforms prior work on two public HOI benchmarks by a sizeable margin. Code will be available.
LSTA-Net: Long short-term Spatio-Temporal Aggregation Network for Skeleton-based Action Recognition
Nov 01, 2021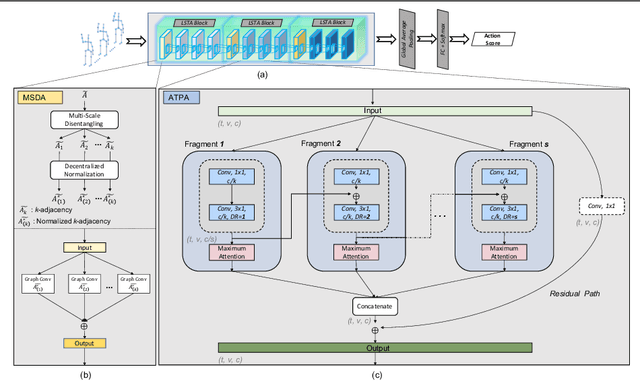
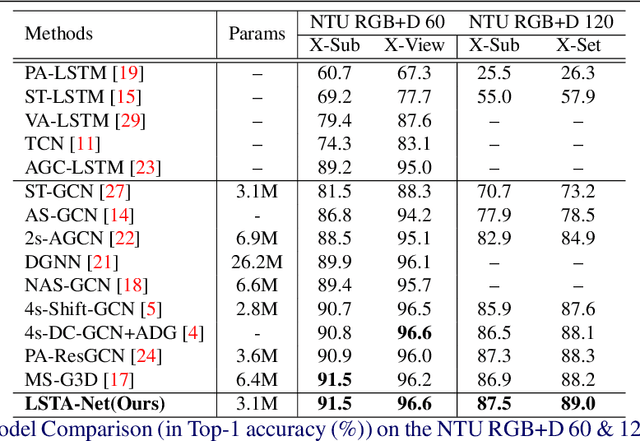
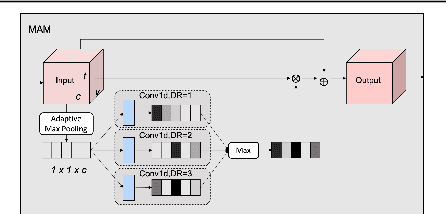
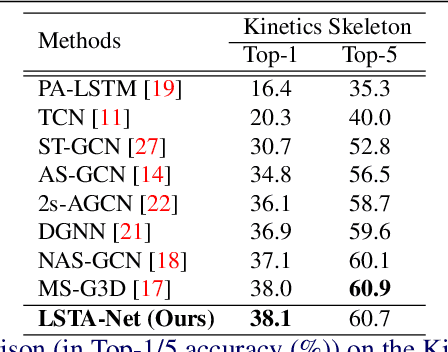
Modelling various spatio-temporal dependencies is the key to recognising human actions in skeleton sequences. Most existing methods excessively relied on the design of traversal rules or graph topologies to draw the dependencies of the dynamic joints, which is inadequate to reflect the relationships of the distant yet important joints. Furthermore, due to the locally adopted operations, the important long-range temporal information is therefore not well explored in existing works. To address this issue, in this work we propose LSTA-Net: a novel Long short-term Spatio-Temporal Aggregation Network, which can effectively capture the long/short-range dependencies in a spatio-temporal manner. We devise our model into a pure factorised architecture which can alternately perform spatial feature aggregation and temporal feature aggregation. To improve the feature aggregation effect, a channel-wise attention mechanism is also designed and employed. Extensive experiments were conducted on three public benchmark datasets, and the results suggest that our approach can capture both long-and-short range dependencies in the space and time domain, yielding higher results than other state-of-the-art methods. Code available at https://github.com/tailin1009/LSTA-Net.
Single Image 3D Object Estimation with Primitive Graph Networks
Sep 09, 2021
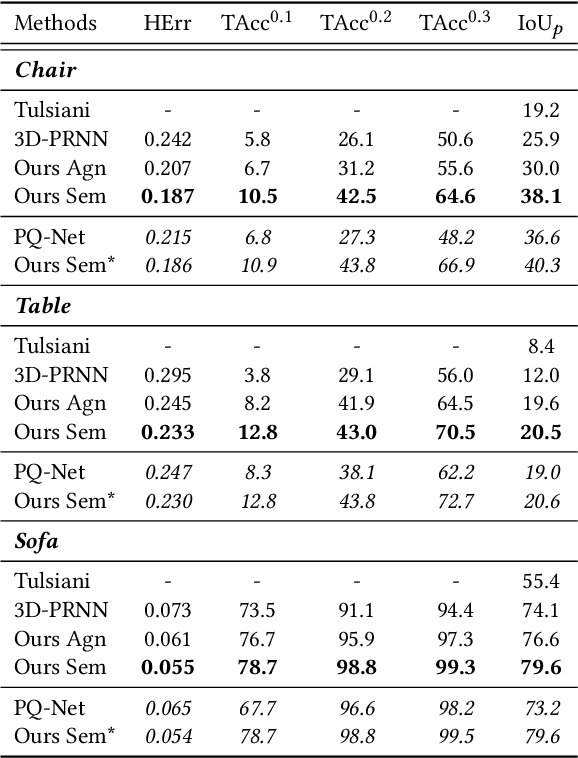
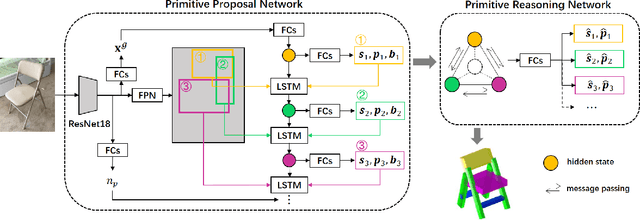
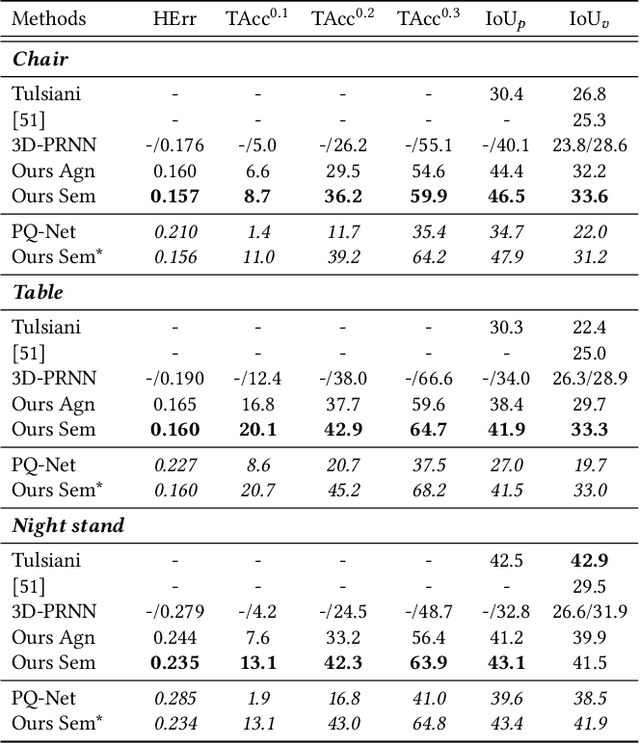
Reconstructing 3D object from a single image (RGB or depth) is a fundamental problem in visual scene understanding and yet remains challenging due to its ill-posed nature and complexity in real-world scenes. To address those challenges, we adopt a primitive-based representation for 3D object, and propose a two-stage graph network for primitive-based 3D object estimation, which consists of a sequential proposal module and a graph reasoning module. Given a 2D image, our proposal module first generates a sequence of 3D primitives from input image with local feature attention. Then the graph reasoning module performs joint reasoning on a primitive graph to capture the global shape context for each primitive. Such a framework is capable of taking into account rich geometry and semantic constraints during 3D structure recovery, producing 3D objects with more coherent structure even under challenging viewing conditions. We train the entire graph neural network in a stage-wise strategy and evaluate it on three benchmarks: Pix3D, ModelNet and NYU Depth V2. Extensive experiments show that our approach outperforms the previous state of the arts with a considerable margin.
Learning Multi-Granular Spatio-Temporal Graph Network for Skeleton-based Action Recognition
Aug 10, 2021
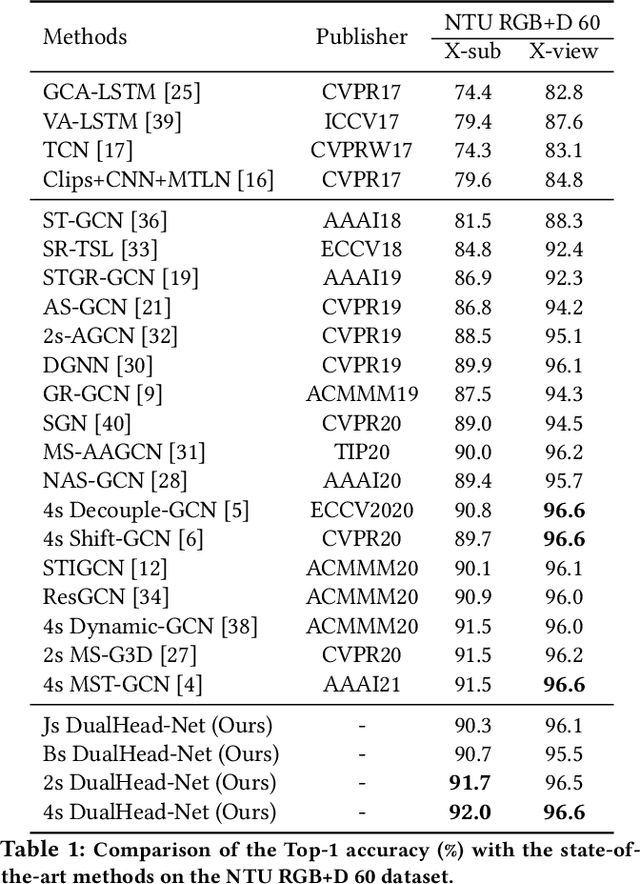

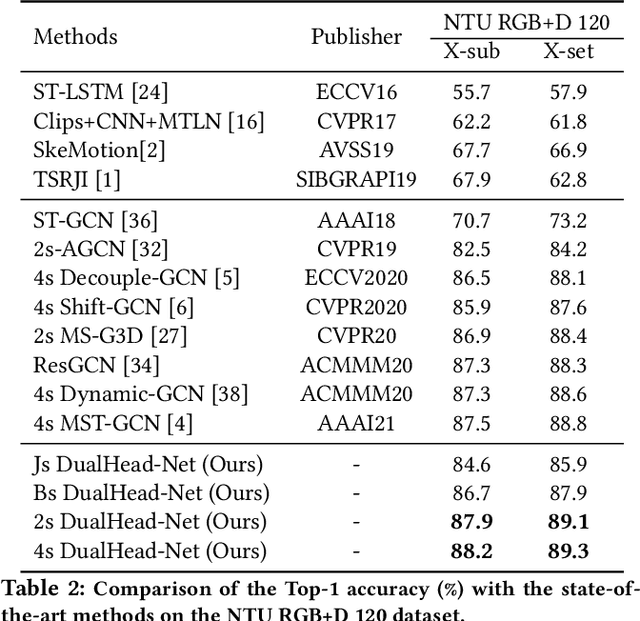
The task of skeleton-based action recognition remains a core challenge in human-centred scene understanding due to the multiple granularities and large variation in human motion. Existing approaches typically employ a single neural representation for different motion patterns, which has difficulty in capturing fine-grained action classes given limited training data. To address the aforementioned problems, we propose a novel multi-granular spatio-temporal graph network for skeleton-based action classification that jointly models the coarse- and fine-grained skeleton motion patterns. To this end, we develop a dual-head graph network consisting of two interleaved branches, which enables us to extract features at two spatio-temporal resolutions in an effective and efficient manner. Moreover, our network utilises a cross-head communication strategy to mutually enhance the representations of both heads. We conducted extensive experiments on three large-scale datasets, namely NTU RGB+D 60, NTU RGB+D 120, and Kinetics-Skeleton, and achieves the state-of-the-art performance on all the benchmarks, which validates the effectiveness of our method.
Pose-aware Multi-level Feature Network for Human Object Interaction Detection
Sep 18, 2019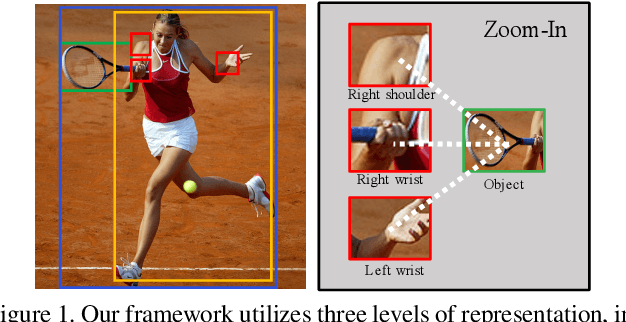
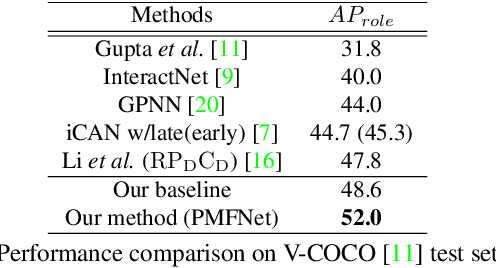
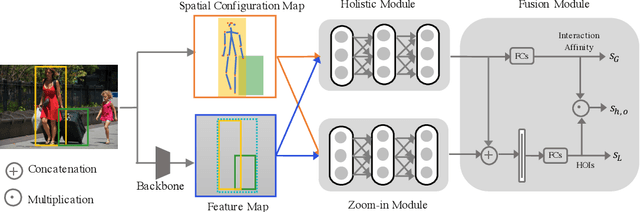
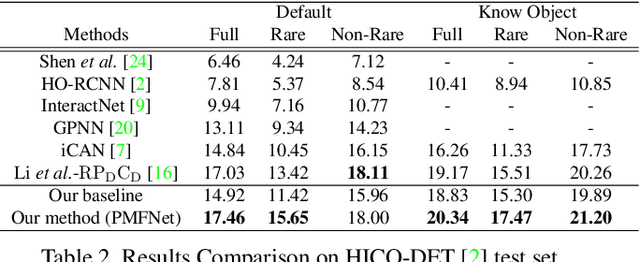
Reasoning human object interactions is a core problem in human-centric scene understanding and detecting such relations poses a unique challenge to vision systems due to large variations in human-object configurations, multiple co-occurring relation instances and subtle visual difference between relation categories. To address those challenges, we propose a multi-level relation detection strategy that utilizes human pose cues to capture global spatial configurations of relations and as an attention mechanism to dynamically zoom into relevant regions at human part level. Specifically, we develop a multi-branch deep network to learn a pose-augmented relation representation at three semantic levels, incorporating interaction context, object features and detailed semantic part cues. As a result, our approach is capable of generating robust predictions on fine-grained human object interactions with interpretable outputs. Extensive experimental evaluations on public benchmarks show that our model outperforms prior methods by a considerable margin, demonstrating its efficacy in handling complex scenes.