 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMILD: Modeling the Instance Learning Dynamics for Learning with Noisy Labels
Jun 20, 2023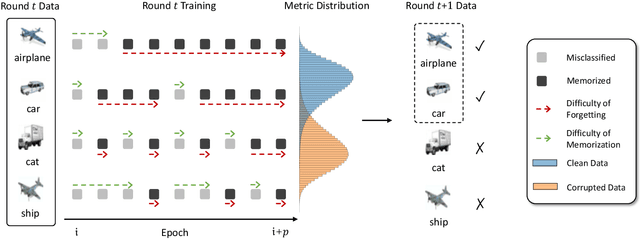
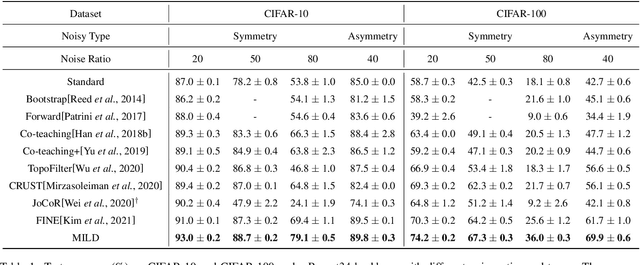

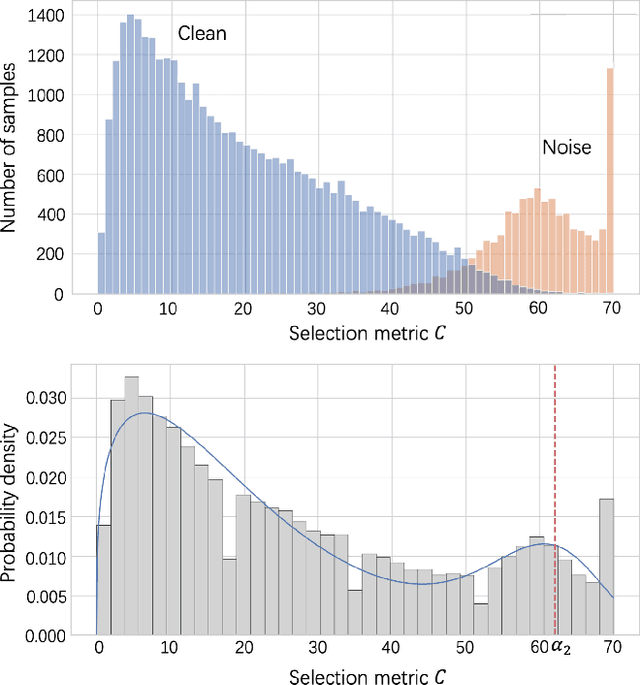
Despite deep learning has achieved great success, it often relies on a large amount of training data with accurate labels, which are expensive and time-consuming to collect. A prominent direction to reduce the cost is to learn with noisy labels, which are ubiquitous in the real-world applications. A critical challenge for such a learning task is to reduce the effect of network memorization on the falsely-labeled data. In this work, we propose an iterative selection approach based on the Weibull mixture model, which identifies clean data by considering the overall learning dynamics of each data instance. In contrast to the previous small-loss heuristics, we leverage the observation that deep network is easy to memorize and hard to forget clean data. In particular, we measure the difficulty of memorization and forgetting for each instance via the transition times between being misclassified and being memorized in training, and integrate them into a novel metric for selection. Based on the proposed metric, we retain a subset of identified clean data and repeat the selection procedure to iteratively refine the clean subset, which is finally used for model training. To validate our method, we perform extensive experiments on synthetic noisy datasets and real-world web data, and our strategy outperforms existing noisy-label learning methods.
Part-aware Prototypical Graph Network for One-shot Skeleton-based Action Recognition
Aug 19, 2022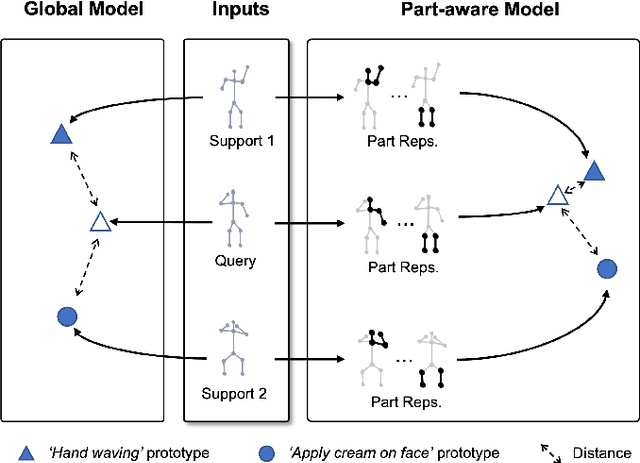
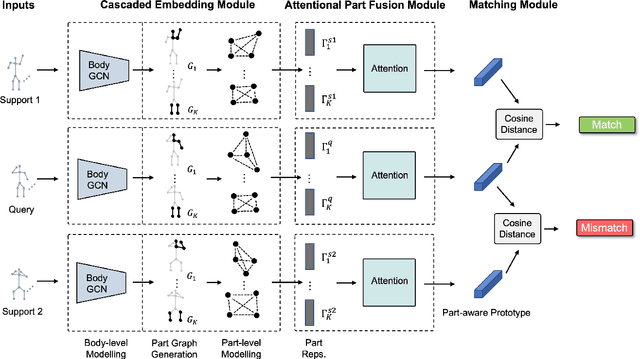
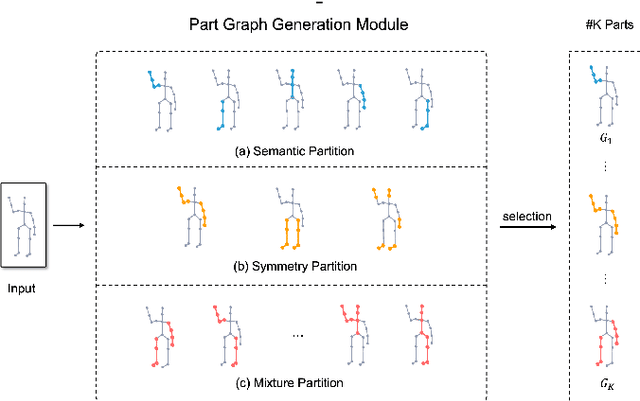
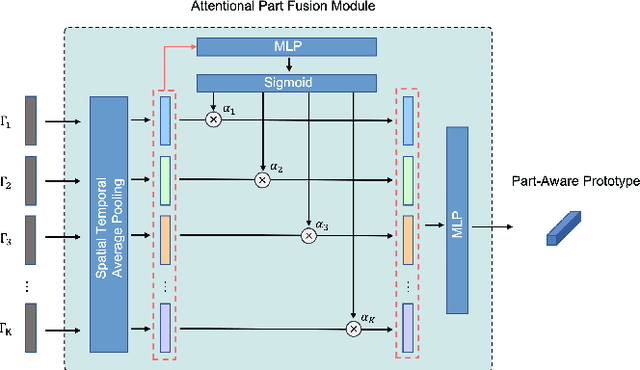
In this paper, we study the problem of one-shot skeleton-based action recognition, which poses unique challenges in learning transferable representation from base classes to novel classes, particularly for fine-grained actions. Existing meta-learning frameworks typically rely on the body-level representations in spatial dimension, which limits the generalisation to capture subtle visual differences in the fine-grained label space. To overcome the above limitation, we propose a part-aware prototypical representation for one-shot skeleton-based action recognition. Our method captures skeleton motion patterns at two distinctive spatial levels, one for global contexts among all body joints, referred to as body level, and the other attends to local spatial regions of body parts, referred to as the part level. We also devise a class-agnostic attention mechanism to highlight important parts for each action class. Specifically, we develop a part-aware prototypical graph network consisting of three modules: a cascaded embedding module for our dual-level modelling, an attention-based part fusion module to fuse parts and generate part-aware prototypes, and a matching module to perform classification with the part-aware representations. We demonstrate the effectiveness of our method on two public skeleton-based action recognition datasets: NTU RGB+D 120 and NW-UCLA.
Mutual Information-guided Knowledge Transfer for Novel Class Discovery
Jun 24, 2022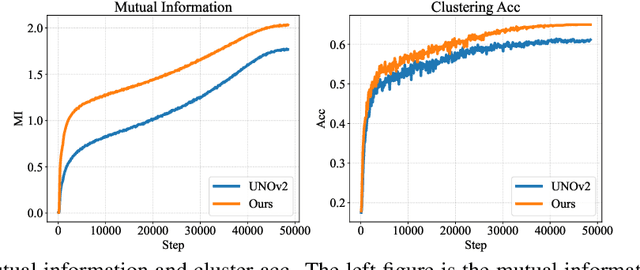
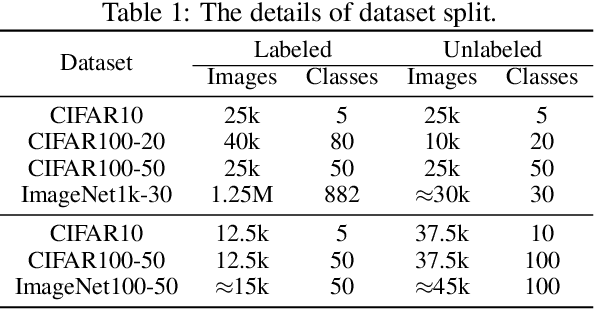
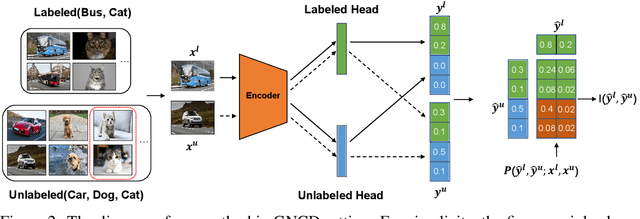
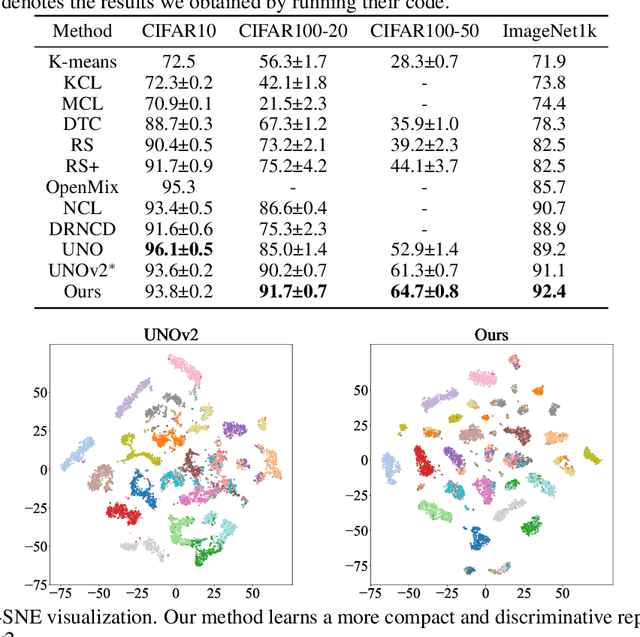
We tackle the novel class discovery problem, aiming to discover novel classes in unlabeled data based on labeled data from seen classes. The main challenge is to transfer knowledge contained in the seen classes to unseen ones. Previous methods mostly transfer knowledge through sharing representation space or joint label space. However, they tend to neglect the class relation between seen and unseen categories, and thus the learned representations are less effective for clustering unseen classes. In this paper, we propose a principle and general method to transfer semantic knowledge between seen and unseen classes. Our insight is to utilize mutual information to measure the relation between seen classes and unseen classes in a restricted label space and maximizing mutual information promotes transferring semantic knowledge. To validate the effectiveness and generalization of our method, we conduct extensive experiments both on novel class discovery and general novel class discovery settings. Our results show that the proposed method outperforms previous SOTA by a significant margin on several benchmarks.
Intention-aware Feature Propagation Network for Interactive Segmentation
Mar 10, 2022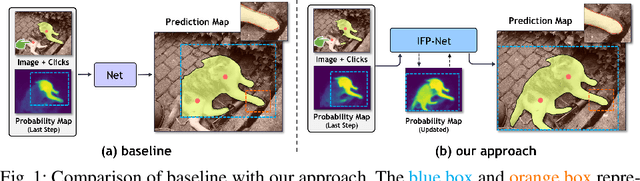
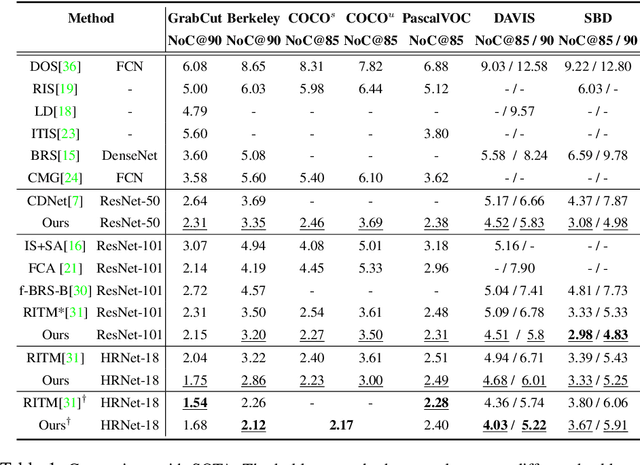
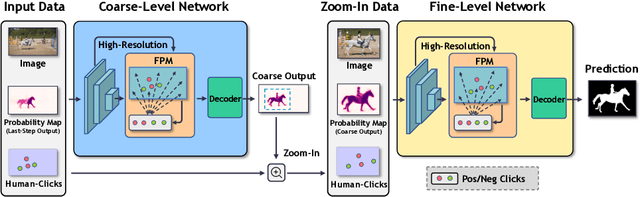
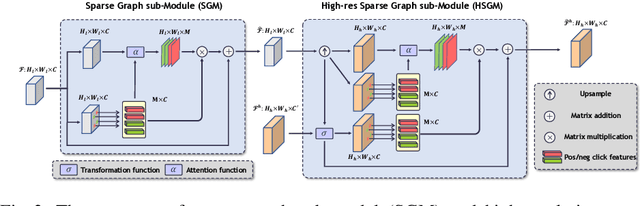
We aim to tackle the problem of point-based interactive segmentation, in which two key challenges are to infer user's intention correctly and to propagate the user-provided annotations to unlabeled regions efficiently. To address those challenges, we propose a novel intention-aware feature propagation strategy that performs explicit user intention estimation and learns an efficient click-augmented feature representation for high-resolution foreground segmentation. Specifically, we develop a coarse-to-fine sparse propagation network for each interactive segmentation step, which consists of a coarse-level network for more effective tracking of user's interest, and a fine-level network for zooming to the target object and performing fine-level segmentation. Moreover, we design a new sparse graph network module for both levels to enable efficient long-range propagation of click information. Extensive experiments show that our method surpasses the previous state-of-the-art methods on all popular benchmarks, demonstrating its efficacy.