 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSE: Agentic 3D Scene Authoring via Memory-Grounded Incremental Requirement Satisfaction
Jun 12, 2026Text-driven 3D scene generation is a promising technique for digital content creation, embodied AI simulation, and interactive design, yet practical workflows often require refining, extending, or correcting existing scenes while preserving non-target content. Existing methods can produce realistic and structurally plausible scenes, but they generally lack editability with requirement-level state tracking, so part-level failures often lead to full-scene regeneration or manual intervention. To tackle this challenge, we formulate controllable 3D scene authoring as incremental requirement satisfaction, unifying construction and editing. In this paper, we present MUSE, a memory-grounded multi-agent framework in which an Architect compiles instructions into structured requirements, a Sculptor executes local scene operations, and an Inspector verifies each step while updating Working, Scene, and Skill Memory. To evaluate requirement-level controllability and preservation-aware editing, we introduce AuthorBench, offering 145 constrained construction cases and a 1,584-case preservation-aware editing pool paired with external structured checks. On full construction cases, MUSE improves All-Goal success from 37.9 to 80.7 and surface-constraint fulfillment from 35.0 to 92.6 over the strongest baseline. On a stratified 240-case editing test split, MUSE achieves 49.6 All-Goal success, 99.9 preservation rate, and only 0.6 unintended change rate. Beyond automated metrics, human evaluations on compared local-editing baselines support stronger alignment with user intent, and downstream navigation-proxy tests indicate stronger spatial stability. Combined with ablations validating our memory designs, these results establish MUSE as an effective framework for controllable 3D scene authoring.
JointEdit3D: Feed-Forward 3D Scene Editing in a Unified Latent Space
Jun 11, 2026Existing 3D scene editing methods typically rely on per-scene optimization over explicit 3D representations or cascaded edit-and-reconstruct pipelines, resulting in high test-time cost, limited 3D awareness, and structural inconsistencies. To couple appearance synthesis and geometry prediction during editing, we build on a unified RGB-geometry reconstruction-generation latent space and adapt it to feed-forward 3D scene editing. The resulting framework, \textbf{JointEdit3D}, performs asymmetric latent inpainting by observing only a single edited RGB reference latent and generating the remaining RGB views and edited geometry latent under source-scene anchoring. JointEdit3D introduces a dedicated SceneAnchor Branch to inject source-scene structure without forcing direct copying, and adopts edit/background-aware losses to balance edited-region fidelity with unedited-content preservation. To address the lack of paired resources for standardized 3D scene editing evaluation, we introduce SceneEdit3D-15K, a dataset with 15K paired editing samples and renderer-provided 3D annotations, together with SceneEdit3D-Bench, a curated 100-sample benchmark. Experiments show that JointEdit3D improves edited-region quality and 3D structural completeness over prior baselines while maintaining competitive background preservation.
Rethinking Data Mixing from the Perspective of Large Language Models
Apr 09, 2026Data mixing strategy is essential for large language model (LLM) training. Empirical evidence shows that inappropriate strategies can significantly reduce generalization. Although recent methods have improved empirical performance, several fundamental questions remain open: what constitutes a domain, whether human and model perceptions of domains are aligned, and how domain weighting influences generalization. We address these questions by establishing formal connections between gradient dynamics and domain distributions, offering a theoretical framework that clarifies the role of domains in training dynamics. Building on this analysis, we introduce DoGraph, a reweighting framework that formulates data scheduling as a graph-constrained optimization problem. Extensive experiments on GPT-2 models of varying scales demonstrate that DoGraph consistently achieves competitive performance.
TSHA: A Benchmark for Visual Language Models in Trustworthy Safety Hazard Assessment Scenarios
Mar 31, 2026Recent advances in vision-language models (VLMs) have accelerated their application to indoor safety hazards assessment. However, existing benchmarks suffer from three fundamental limitations: (1) heavy reliance on synthetic datasets constructed via simulation software, creating a significant domain gap with real-world environments; (2) oversimplified safety tasks with artificial constraints on hazard and scene types, thereby limiting model generalization; and (3) absence of rigorous evaluation protocols to thoroughly assess model capabilities in complex home safety scenarios. To address these challenges, we introduce TSHA (\textbf{T}rustworthy \textbf{S}afety \textbf{H}azards \textbf{A}ssessment), a comprehensive benchmark comprising 81,809 carefully curated training samples drawn from four complementary sources: existing indoor datasets, internet images, AIGC images, and newly captured images. This benchmark set also includes a highly challenging test set with 1707 samples, comprising not only a carefully selected subset from the training distribution but also newly added videos and panoramic images containing multiple safety hazards, used to evaluate the model's robustness in complex safety scenarios. Extensive experiments on 23 popular VLMs demonstrate that current VLMs lack robust capabilities for safety hazard assessment. Importantly, models trained on the TSHA training set not only achieve a significant performance improvement of up to +18.3 points on the TSHA test set but also exhibit enhanced generalizability across other benchmarks, underscoring the substantial contribution and importance of the TSHA benchmark.
SWE-Hub: A Unified Production System for Scalable, Executable Software Engineering Tasks
Feb 28, 2026Progress in software-engineering agents is increasingly constrained by the scarcity of executable, scalable, and realistic data for training and evaluation. This scarcity stems from three fundamental challenges in existing pipelines: environments are brittle and difficult to reproduce across languages; synthesizing realistic, system-level bugs at scale is computationally expensive; and existing data predominantly consists of short-horizon repairs, failing to capture long-horizon competencies like architectural consistency. We introduce \textbf{SWE-Hub}, an end-to-end system that operationalizes the data factory abstraction by unifying environment automation, scalable synthesis, and diverse task generation into a coherent production stack. At its foundation, the \textbf{Env Agent} establishes a shared execution substrate by automatically converting raw repository snapshots into reproducible, multi-language container environments with standardized interfaces. Built upon this substrate, \textbf{SWE-Scale} engine addresses the need for high-throughput generation, combining cross-language code analysis with cluster-scale validation to synthesize massive volumes of localized bug-fix instances. \textbf{Bug Agent} generates high-fidelity repair tasks by synthesizing system-level regressions involving cross-module dependencies, paired with user-like issue reports that describe observable symptoms rather than root causes. Finally, \textbf{SWE-Architect} expands the task scope from repair to creation by translating natural-language requirements into repository-scale build-a-repo tasks. By integrating these components, SWE-Hub establishes a unified production pipeline capable of continuously delivering executable tasks across the entire software engineering lifecycle.
Just say what you want: only-prompting self-rewarding online preference optimization
Sep 26, 2024



We address the challenge of online Reinforcement Learning from Human Feedback (RLHF) with a focus on self-rewarding alignment methods. In online RLHF, obtaining feedback requires interaction with the environment, which can be costly when using additional reward models or the GPT-4 API. Current self-rewarding approaches rely heavily on the discriminator's judgment capabilities, which are effective for large-scale models but challenging to transfer to smaller ones. To address these limitations, we propose a novel, only-prompting self-rewarding online algorithm that generates preference datasets without relying on judgment capabilities. Additionally, we employ fine-grained arithmetic control over the optimality gap between positive and negative examples, generating more hard negatives in the later stages of training to help the model better capture subtle human preferences. Finally, we conduct extensive experiments on two base models, Mistral-7B and Mistral-Instruct-7B, which significantly bootstrap the performance of the reference model, achieving 34.5% in the Length-controlled Win Rates of AlpacaEval 2.0.
Data Contamination Report from the 2024 CONDA Shared Task
Jul 31, 2024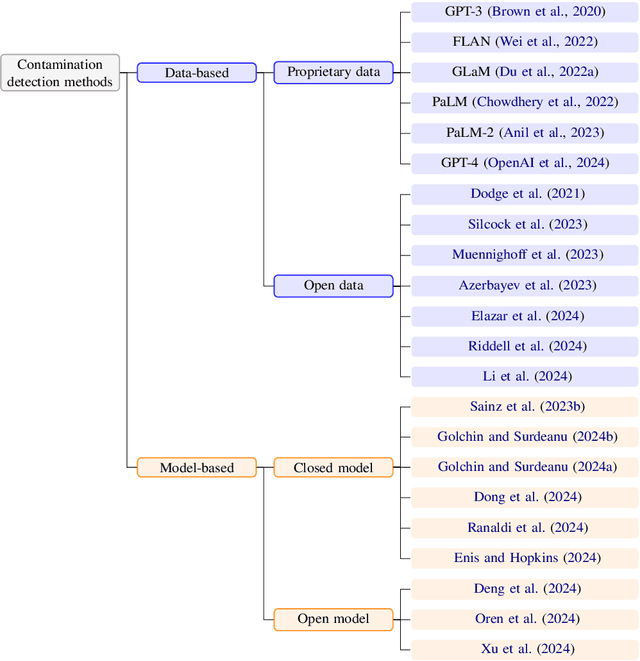
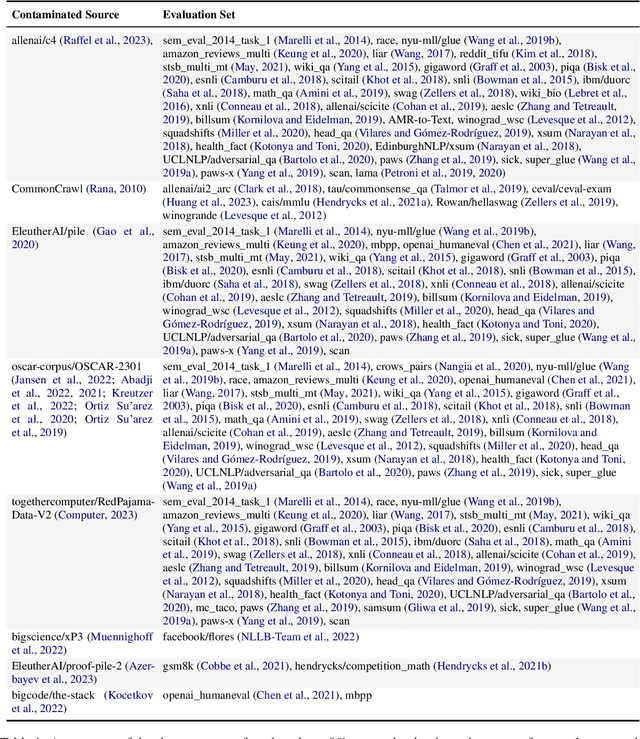
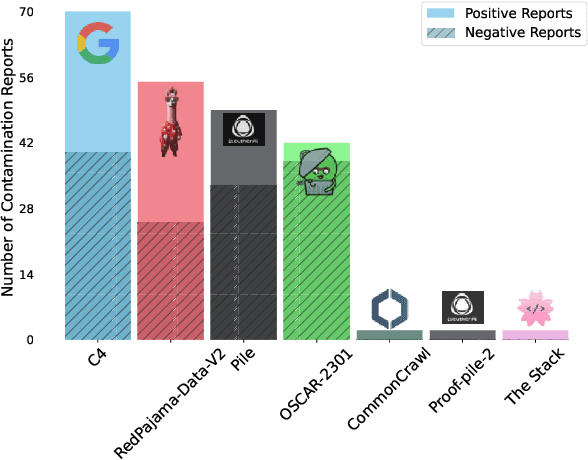
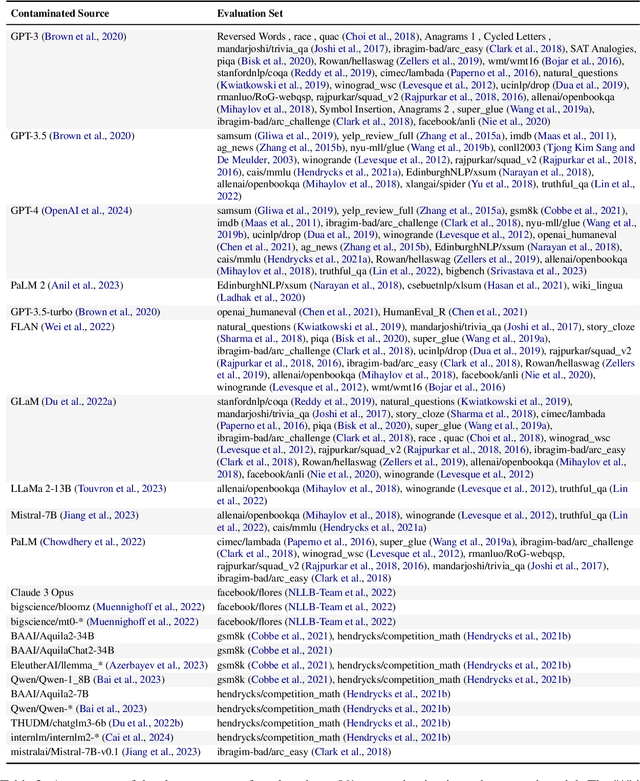
The 1st Workshop on Data Contamination (CONDA 2024) focuses on all relevant aspects of data contamination in natural language processing, where data contamination is understood as situations where evaluation data is included in pre-training corpora used to train large scale models, compromising evaluation results. The workshop fostered a shared task to collect evidence on data contamination in current available datasets and models. The goal of the shared task and associated database is to assist the community in understanding the extent of the problem and to assist researchers in avoiding reporting evaluation results on known contaminated resources. The shared task provides a structured, centralized public database for the collection of contamination evidence, open to contributions from the community via GitHub pool requests. This first compilation paper is based on 566 reported entries over 91 contaminated sources from a total of 23 contributors. The details of the individual contamination events are available in the platform. The platform continues to be online, open to contributions from the community.
Dual-level Adaptive Self-Labeling for Novel Class Discovery in Point Cloud Segmentation
Jul 17, 2024



We tackle the novel class discovery in point cloud segmentation, which discovers novel classes based on the semantic knowledge of seen classes. Existing work proposes an online point-wise clustering method with a simplified equal class-size constraint on the novel classes to avoid degenerate solutions. However, the inherent imbalanced distribution of novel classes in point clouds typically violates the equal class-size constraint. Moreover, point-wise clustering ignores the rich spatial context information of objects, which results in less expressive representation for semantic segmentation. To address the above challenges, we propose a novel self-labeling strategy that adaptively generates high-quality pseudo-labels for imbalanced classes during model training. In addition, we develop a dual-level representation that incorporates regional consistency into the point-level classifier learning, reducing noise in generated segmentation. Finally, we conduct extensive experiments on two widely used datasets, SemanticKITTI and SemanticPOSS, and the results show our method outperforms the state of the art by a large margin.
OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent AI
Jun 18, 2024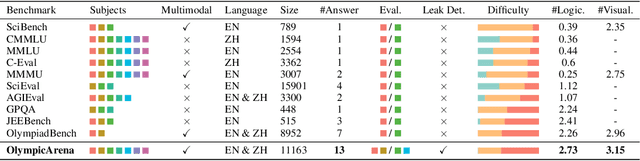
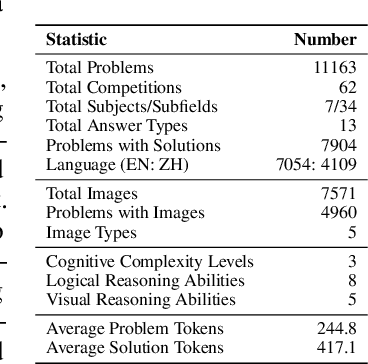
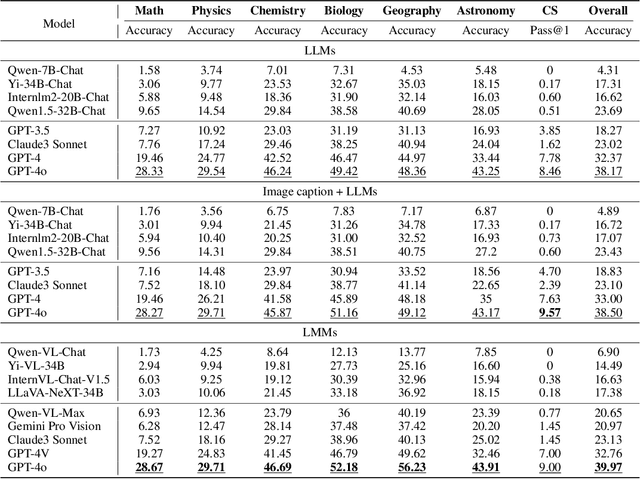
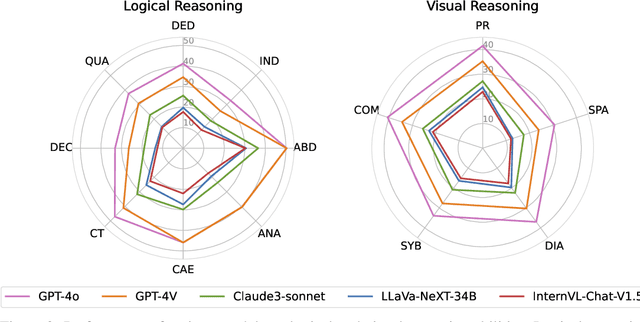
The evolution of Artificial Intelligence (AI) has been significantly accelerated by advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), gradually showcasing potential cognitive reasoning abilities in problem-solving and scientific discovery (i.e., AI4Science) once exclusive to human intellect. To comprehensively evaluate current models' performance in cognitive reasoning abilities, we introduce OlympicArena, which includes 11,163 bilingual problems across both text-only and interleaved text-image modalities. These challenges encompass a wide range of disciplines spanning seven fields and 62 international Olympic competitions, rigorously examined for data leakage. We argue that the challenges in Olympic competition problems are ideal for evaluating AI's cognitive reasoning due to their complexity and interdisciplinary nature, which are essential for tackling complex scientific challenges and facilitating discoveries. Beyond evaluating performance across various disciplines using answer-only criteria, we conduct detailed experiments and analyses from multiple perspectives. We delve into the models' cognitive reasoning abilities, their performance across different modalities, and their outcomes in process-level evaluations, which are vital for tasks requiring complex reasoning with lengthy solutions. Our extensive evaluations reveal that even advanced models like GPT-4o only achieve a 39.97% overall accuracy, illustrating current AI limitations in complex reasoning and multimodal integration. Through the OlympicArena, we aim to advance AI towards superintelligence, equipping it to address more complex challenges in science and beyond. We also provide a comprehensive set of resources to support AI research, including a benchmark dataset, an open-source annotation platform, a detailed evaluation tool, and a leaderboard with automatic submission features.
Benchmarking Benchmark Leakage in Large Language Models
Apr 29, 2024



Amid the expanding use of pre-training data, the phenomenon of benchmark dataset leakage has become increasingly prominent, exacerbated by opaque training processes and the often undisclosed inclusion of supervised data in contemporary Large Language Models (LLMs). This issue skews benchmark effectiveness and fosters potentially unfair comparisons, impeding the field's healthy development. To address this, we introduce a detection pipeline utilizing Perplexity and N-gram accuracy, two simple and scalable metrics that gauge a model's prediction precision on benchmark, to identify potential data leakages. By analyzing 31 LLMs under the context of mathematical reasoning, we reveal substantial instances of training even test set misuse, resulting in potentially unfair comparisons. These findings prompt us to offer several recommendations regarding model documentation, benchmark setup, and future evaluations. Notably, we propose the "Benchmark Transparency Card" to encourage clear documentation of benchmark utilization, promoting transparency and healthy developments of LLMs. we have made our leaderboard, pipeline implementation, and model predictions publicly available, fostering future research.