 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing and Understanding Energy Footprint and Efficiency of Small Language Model on Edges
Nov 07, 2025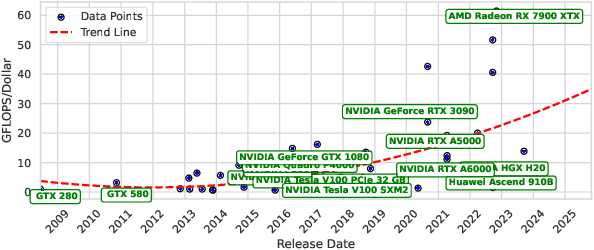
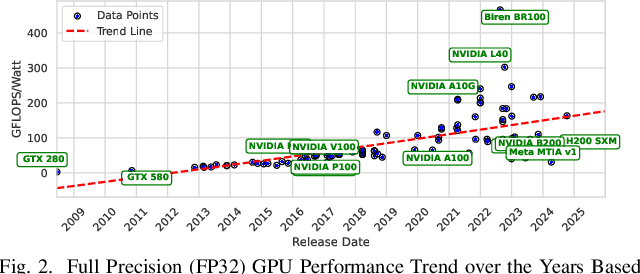

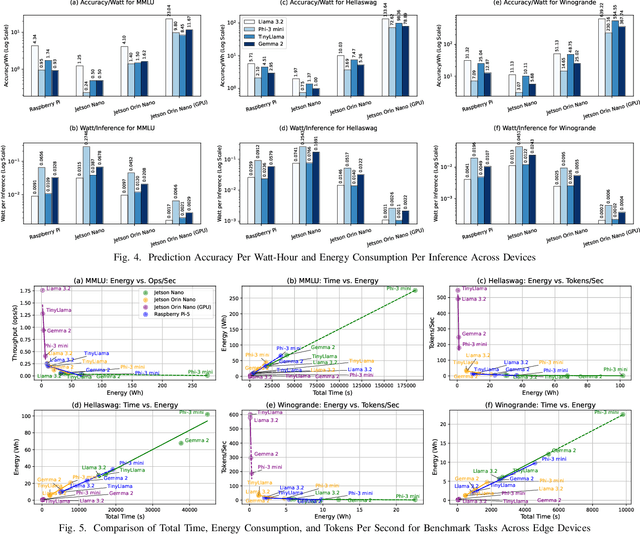
Cloud-based large language models (LLMs) and their variants have significantly influenced real-world applications. Deploying smaller models (i.e., small language models (SLMs)) on edge devices offers additional advantages, such as reduced latency and independence from network connectivity. However, edge devices' limited computing resources and constrained energy budgets challenge efficient deployment. This study evaluates the power efficiency of five representative SLMs - Llama 3.2, Phi-3 Mini, TinyLlama, and Gemma 2 on Raspberry Pi 5, Jetson Nano, and Jetson Orin Nano (CPU and GPU configurations). Results show that Jetson Orin Nano with GPU acceleration achieves the highest energy-to-performance ratio, significantly outperforming CPU-based setups. Llama 3.2 provides the best balance of accuracy and power efficiency, while TinyLlama is well-suited for low-power environments at the cost of reduced accuracy. In contrast, Phi-3 Mini consumes the most energy despite its high accuracy. In addition, GPU acceleration, memory bandwidth, and model architecture are key in optimizing inference energy efficiency. Our empirical analysis offers practical insights for AI, smart systems, and mobile ad-hoc platforms to leverage tradeoffs from accuracy, inference latency, and power efficiency in energy-constrained environments.
Towards Training Reproducible Deep Learning Models
Feb 04, 2022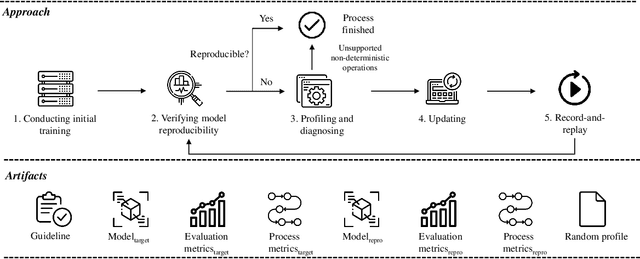
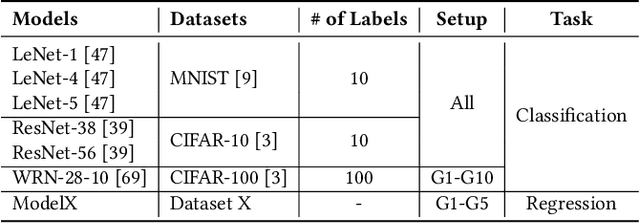

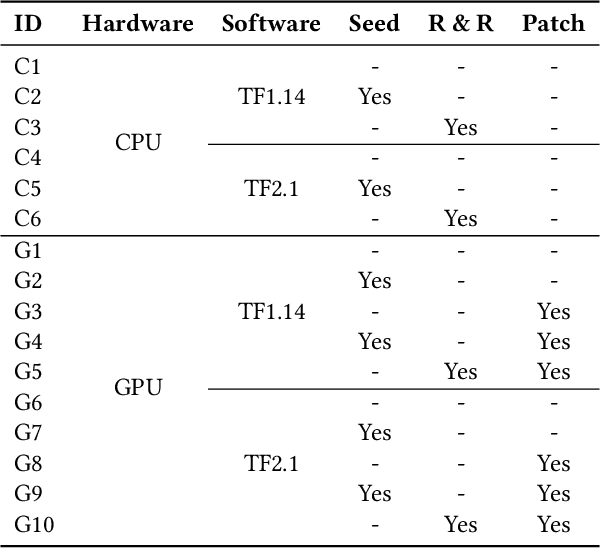
Reproducibility is an increasing concern in Artificial Intelligence (AI), particularly in the area of Deep Learning (DL). Being able to reproduce DL models is crucial for AI-based systems, as it is closely tied to various tasks like training, testing, debugging, and auditing. However, DL models are challenging to be reproduced due to issues like randomness in the software (e.g., DL algorithms) and non-determinism in the hardware (e.g., GPU). There are various practices to mitigate some of the aforementioned issues. However, many of them are either too intrusive or can only work for a specific usage context. In this paper, we propose a systematic approach to training reproducible DL models. Our approach includes three main parts: (1) a set of general criteria to thoroughly evaluate the reproducibility of DL models for two different domains, (2) a unified framework which leverages a record-and-replay technique to mitigate software-related randomness and a profile-and-patch technique to control hardware-related non-determinism, and (3) a reproducibility guideline which explains the rationales and the mitigation strategies on conducting a reproducible training process for DL models. Case study results show our approach can successfully reproduce six open source and one commercial DL models.
Latent Network Embedding via Adversarial Auto-encoders
Sep 30, 2021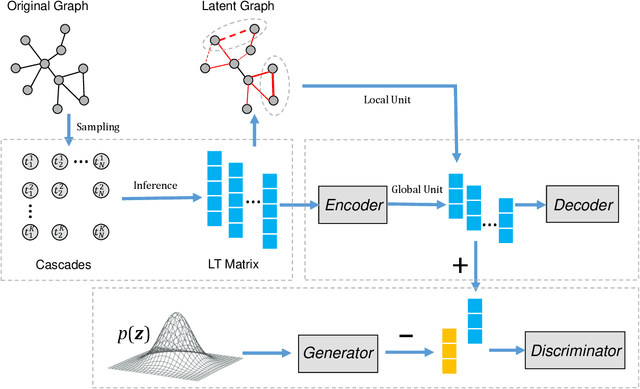
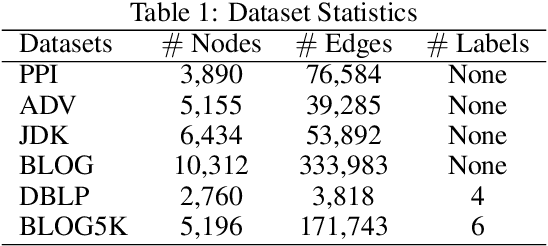
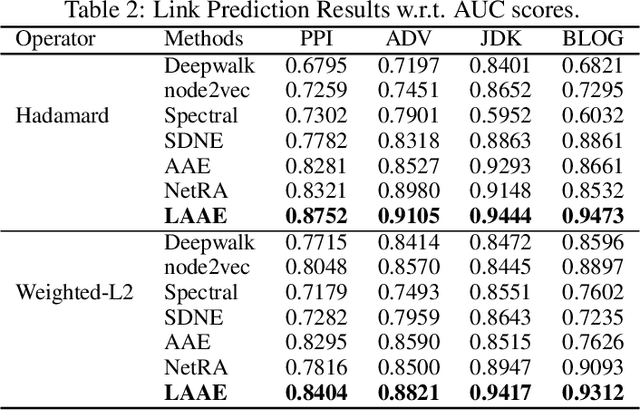
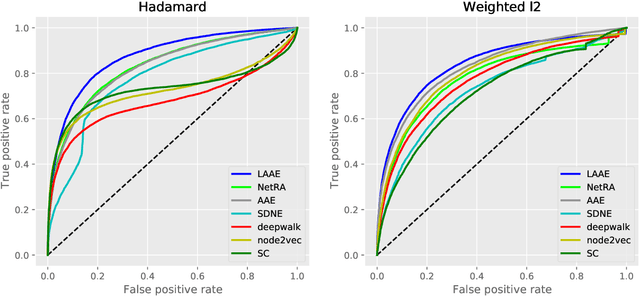
Graph auto-encoders have proved to be useful in network embedding task. However, current models only consider explicit structures and fail to explore the informative latent structures cohered in networks. To address this issue, we propose a latent network embedding model based on adversarial graph auto-encoders. Under this framework, the problem of discovering latent structures is formulated as inferring the latent ties from partial observations. A latent transmission matrix that describes the strengths of existing edges and latent ties is derived based on influence cascades sampled by simulating diffusion processes over networks. Besides, since the inference process may bring extra noises, we introduce an adversarial training that works as regularization to dislodge noises and improve the model robustness. Extensive experiments on link prediction and node classification tasks show that the proposed model achieves superior results compared with baseline models.
Visual Anomaly Detection for Images: A Survey
Sep 27, 2021Visual anomaly detection is an important and challenging problem in the field of machine learning and computer vision. This problem has attracted a considerable amount of attention in relevant research communities. Especially in recent years, the development of deep learning has sparked an increasing interest in the visual anomaly detection problem and brought a great variety of novel methods. In this paper, we provide a comprehensive survey of the classical and deep learning-based approaches for visual anomaly detection in the literature. We group the relevant approaches in view of their underlying principles and discuss their assumptions, advantages, and disadvantages carefully. We aim to help the researchers to understand the common principles of visual anomaly detection approaches and identify promising research directions in this field.
DFR: Deep Feature Reconstruction for Unsupervised Anomaly Segmentation
Dec 13, 2020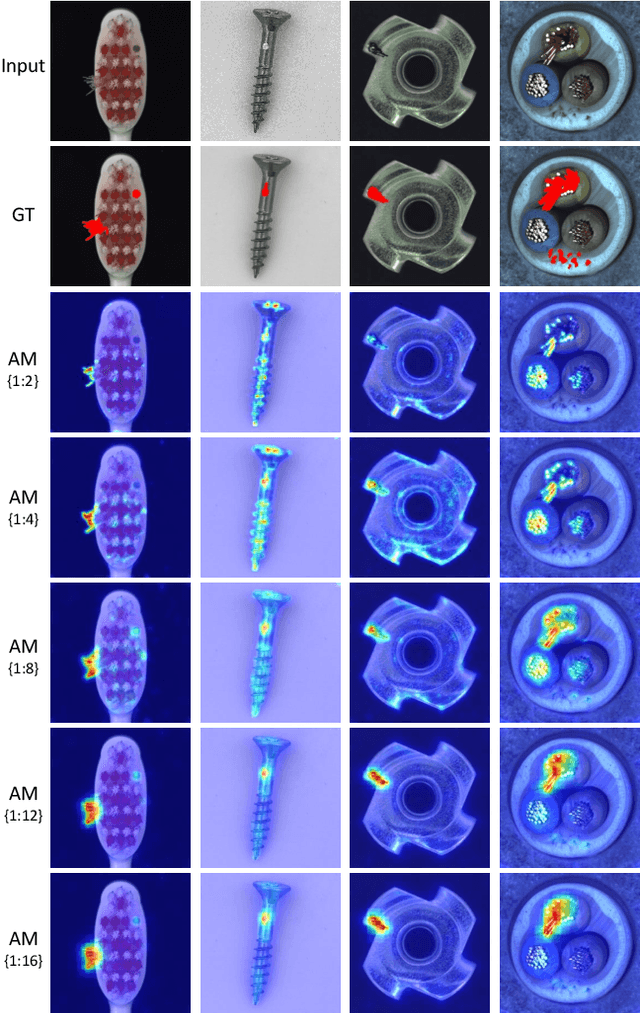
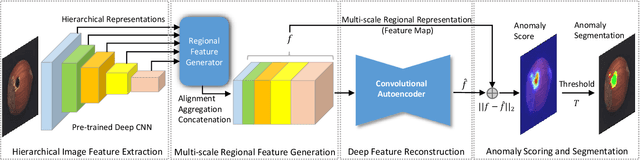
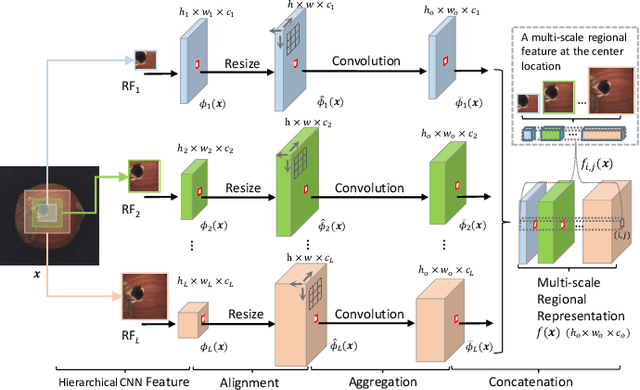
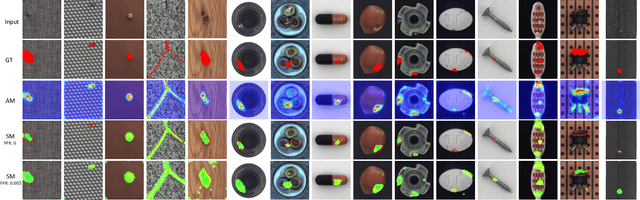
Automatic detecting anomalous regions in images of objects or textures without priors of the anomalies is challenging, especially when the anomalies appear in very small areas of the images, making difficult-to-detect visual variations, such as defects on manufacturing products. This paper proposes an effective unsupervised anomaly segmentation approach that can detect and segment out the anomalies in small and confined regions of images. Concretely, we develop a multi-scale regional feature generator that can generate multiple spatial context-aware representations from pre-trained deep convolutional networks for every subregion of an image. The regional representations not only describe the local characteristics of corresponding regions but also encode their multiple spatial context information, making them discriminative and very beneficial for anomaly detection. Leveraging these descriptive regional features, we then design a deep yet efficient convolutional autoencoder and detect anomalous regions within images via fast feature reconstruction. Our method is simple yet effective and efficient. It advances the state-of-the-art performances on several benchmark datasets and shows great potential for real applications.
Learning to Incorporate Structure Knowledge for Image Inpainting
Feb 12, 2020
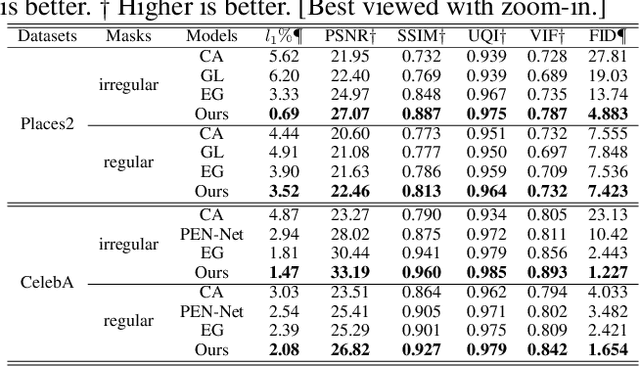
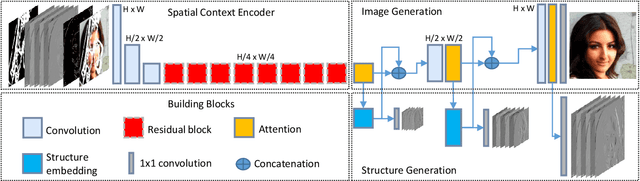
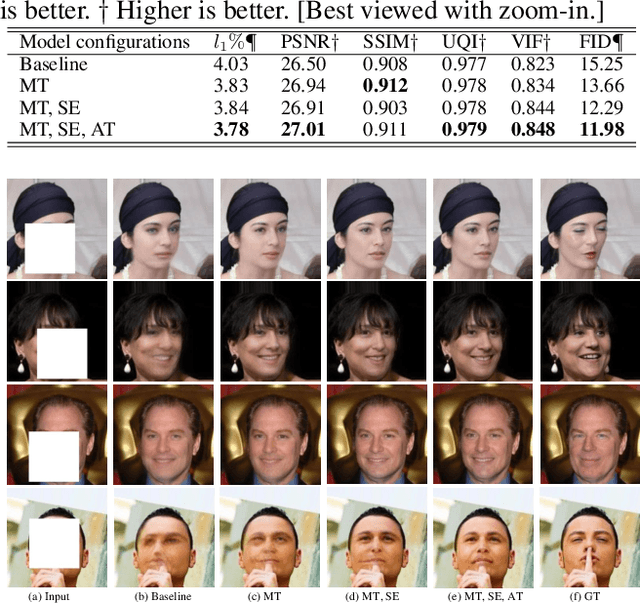
This paper develops a multi-task learning framework that attempts to incorporate the image structure knowledge to assist image inpainting, which is not well explored in previous works. The primary idea is to train a shared generator to simultaneously complete the corrupted image and corresponding structures --- edge and gradient, thus implicitly encouraging the generator to exploit relevant structure knowledge while inpainting. In the meantime, we also introduce a structure embedding scheme to explicitly embed the learned structure features into the inpainting process, thus to provide possible preconditions for image completion. Specifically, a novel pyramid structure loss is proposed to supervise structure learning and embedding. Moreover, an attention mechanism is developed to further exploit the recurrent structures and patterns in the image to refine the generated structures and contents. Through multi-task learning, structure embedding besides with attention, our framework takes advantage of the structure knowledge and outperforms several state-of-the-art methods on benchmark datasets quantitatively and qualitatively.
s-LWSR: Super Lightweight Super-Resolution Network
Sep 24, 2019
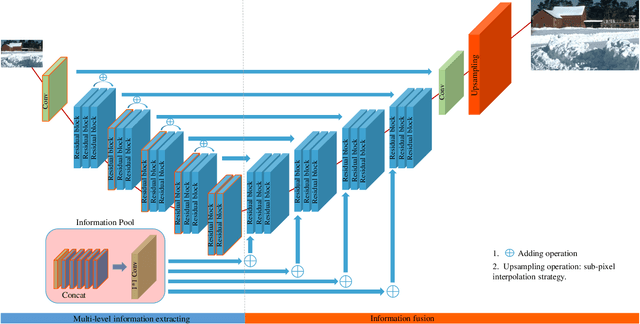
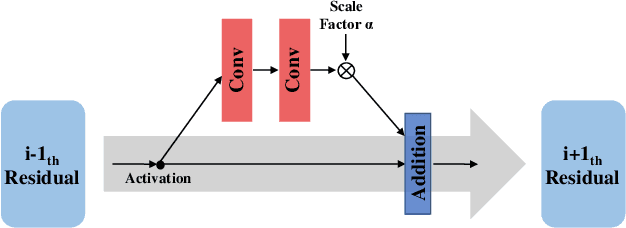
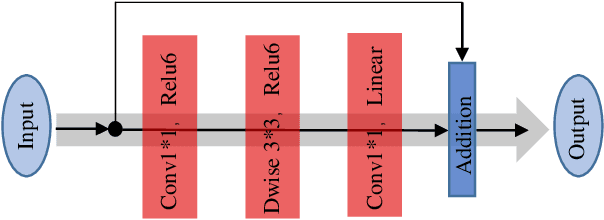
Deep learning (DL) architectures for superresolution (SR) normally contain tremendous parameters, which has been regarded as the crucial advantage for obtaining satisfying performance. However, with the widespread use of mobile phones for taking and retouching photos, this character greatly hampers the deployment of DL-SR models on the mobile devices. To address this problem, in this paper, we propose a super lightweight SR network: s-LWSR. There are mainly three contributions in our work. Firstly, in order to efficiently abstract features from the low resolution image, we build an information pool to mix multi-level information from the first half part of the pipeline. Accordingly, the information pool feeds the second half part with the combination of hierarchical features from the previous layers. Secondly, we employ a compression module to further decrease the size of parameters. Intensive analysis confirms its capacity of trade-off between model complexity and accuracy. Thirdly, by revealing the specific role of activation in deep models, we remove several activation layers in our SR model to retain more information for performance improvement. Extensive experiments show that our s-LWSR, with limited parameters and operations, can achieve similar performance to other cumbersome DL-SR methods.
Learning from Label Proportions with Generative Adversarial Networks
Sep 05, 2019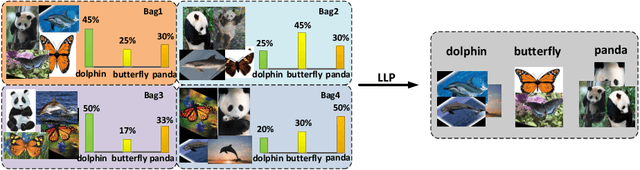
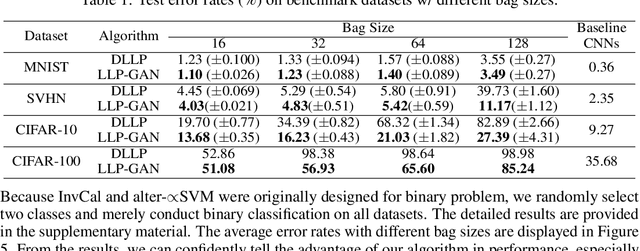
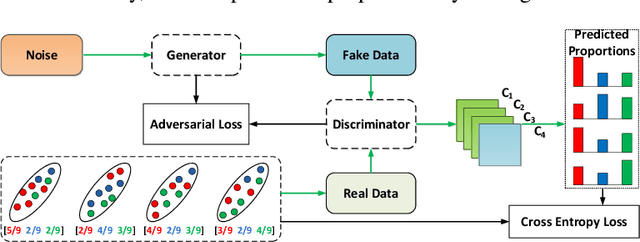
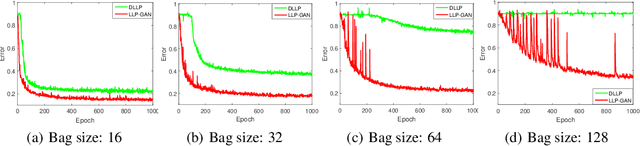
In this paper, we leverage generative adversarial networks (GANs) to derive an effective algorithm LLP-GAN for learning from label proportions (LLP), where only the bag-level proportional information in labels is available. Endowed with end-to-end structure, LLP-GAN performs approximation in the light of an adversarial learning mechanism, without imposing restricted assumptions on distribution. Accordingly, we can directly induce the final instance-level classifier upon the discriminator. Under mild assumptions, we give the explicit generative representation and prove the global optimality for LLP-GAN. Additionally, compared with existing methods, our work empowers LLP solver with capable scalability inheriting from deep models. Several experiments on benchmark datasets demonstrate vivid advantages of the proposed approach.
A Novel Large-scale Ordinal Regression Model
Dec 19, 2018
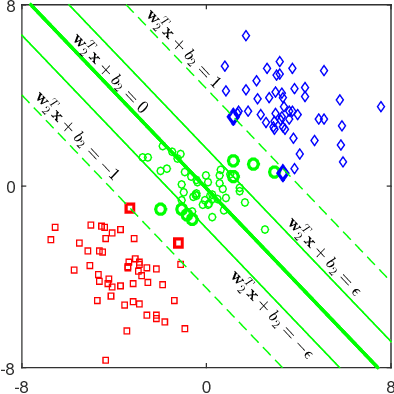
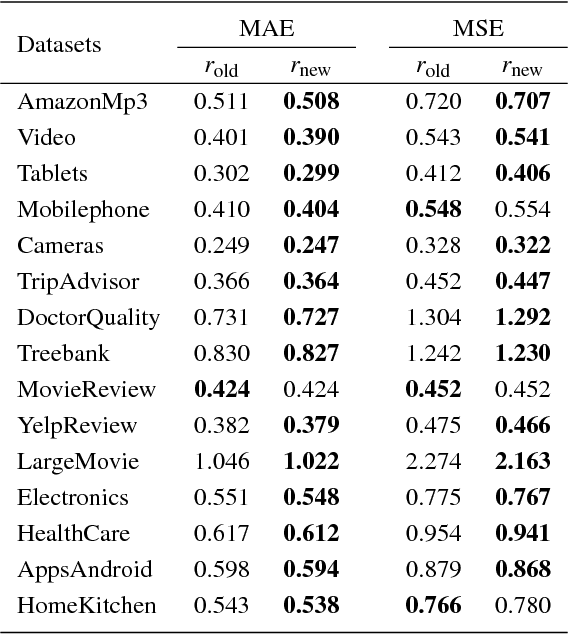
Ordinal regression (OR) is a special multiclass classification problem where an order relation exists among the labels. Recent years, people share their opinions and sentimental judgments conveniently with social networks and E-Commerce so that plentiful large-scale OR problems arise. However, few studies have focused on this kind of problems. Nonparallel Support Vector Ordinal Regression (NPSVOR) is a SVM-based OR model, which learns a hyperplane for each rank by solving a series of independent sub-optimization problems and then ensembles those learned hyperplanes to predict. The previous studies are focused on its nonlinear case and got a competitive testing performance, but its training is time consuming, particularly for large-scale data. In this paper, we consider NPSVOR's linear case and design an efficient training method based on the dual coordinate descent method (DCD). To utilize the order information among labels in prediction, a new prediction function is also proposed. Extensive contrast experiments on the text OR datasets indicate that the carefully implemented DCD is very suitable for training large data.
Research on Artificial Intelligence Ethics Based on the Evolution of Population Knowledge Base
Nov 18, 2018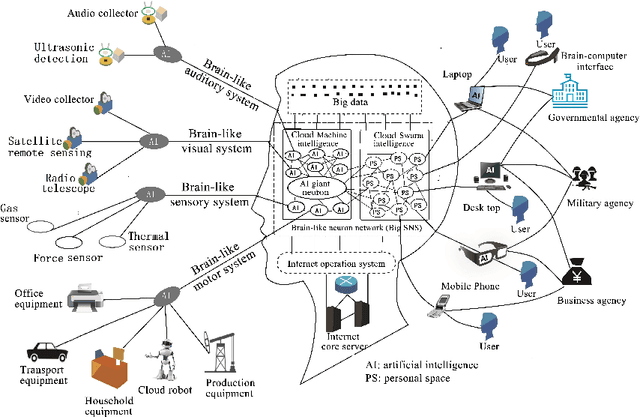

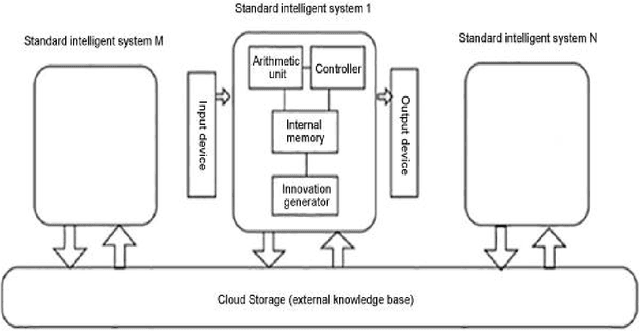
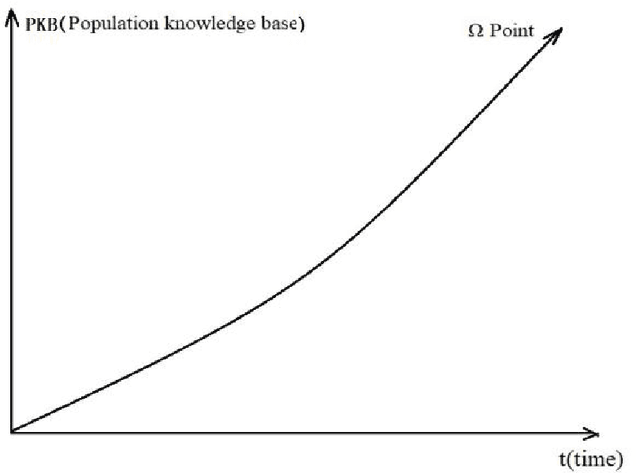
The unclear development direction of human society is a deep reason for that it is difficult to form a uniform ethical standard for human society and artificial intelligence. Since the 21st century, the latest advances in the Internet, brain science and artificial intelligence have brought new inspiration to the research on the development direction of human society. Through the study of the Internet brain model, AI IQ evaluation, and the evolution of the brain, this paper proposes that the evolution of population knowledge base is the key for judging the development direction of human society, thereby discussing the standards and norms for the construction of artificial intelligence ethics.
* 12 pages, 6 figures,1 table