 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Training Reproducible Deep Learning Models
Feb 04, 2022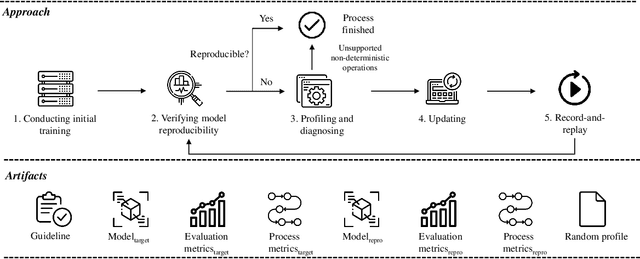
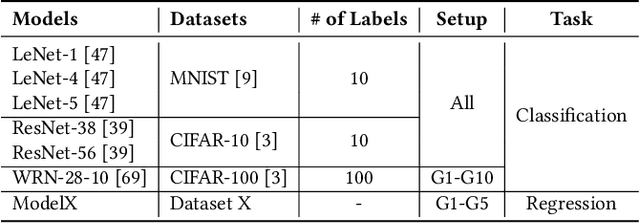

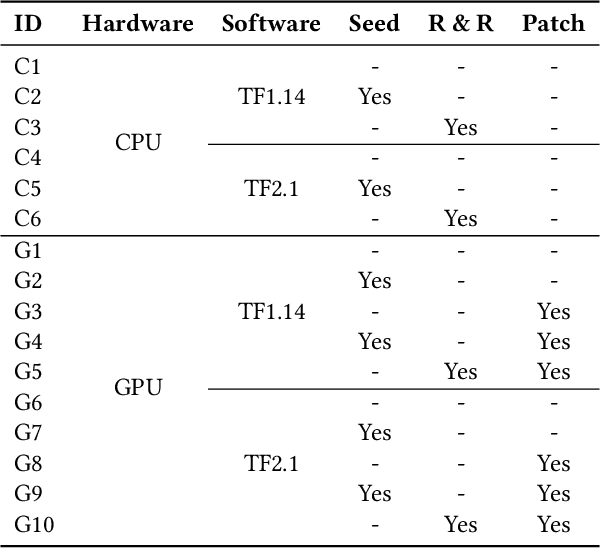
Reproducibility is an increasing concern in Artificial Intelligence (AI), particularly in the area of Deep Learning (DL). Being able to reproduce DL models is crucial for AI-based systems, as it is closely tied to various tasks like training, testing, debugging, and auditing. However, DL models are challenging to be reproduced due to issues like randomness in the software (e.g., DL algorithms) and non-determinism in the hardware (e.g., GPU). There are various practices to mitigate some of the aforementioned issues. However, many of them are either too intrusive or can only work for a specific usage context. In this paper, we propose a systematic approach to training reproducible DL models. Our approach includes three main parts: (1) a set of general criteria to thoroughly evaluate the reproducibility of DL models for two different domains, (2) a unified framework which leverages a record-and-replay technique to mitigate software-related randomness and a profile-and-patch technique to control hardware-related non-determinism, and (3) a reproducibility guideline which explains the rationales and the mitigation strategies on conducting a reproducible training process for DL models. Case study results show our approach can successfully reproduce six open source and one commercial DL models.