 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Pre-training and Adaptation Framework for Combinatorial Optimization on Graphs
Dec 16, 2023



Combinatorial optimization (CO) on graphs is a classic topic that has been extensively studied across many scientific and industrial fields. Recently, solving CO problems on graphs through learning methods has attracted great attention. Advanced deep learning methods, e.g., graph neural networks (GNNs), have been used to effectively assist the process of solving COs. However, current frameworks based on GNNs are mainly designed for certain CO problems, thereby failing to consider their transferable and generalizable abilities among different COs on graphs. Moreover, simply using original graphs to model COs only captures the direct correlations among objects, which does not consider the mathematical logicality and properties of COs. In this paper, we propose a unified pre-training and adaptation framework for COs on graphs with the help of the maximum satisfiability (Max-SAT) problem. We first use Max-SAT to bridge different COs on graphs since they can be converted to Max-SAT problems represented by standard formulas and clauses with logical information. Then, we further design a pre-training and domain adaptation framework to extract the transferable and generalizable features so that different COs can benefit from them. In the pre-training stage, Max-SAT instances are generated to initialize the parameters of the model. In the fine-tuning stage, instances from CO and Max-SAT problems are used for adaptation so that the transferable ability can be further improved. Numerical experiments on several datasets show that features extracted by our framework exhibit superior transferability and Max-SAT can boost the ability to solve COs on graphs.
Supervised Contrastive Learning with Structure Inference for Graph Classification
Mar 15, 2022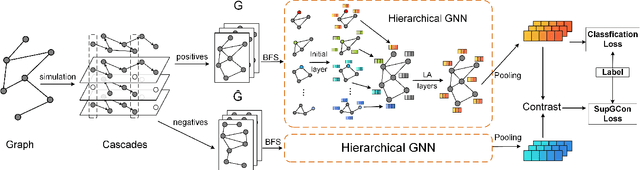
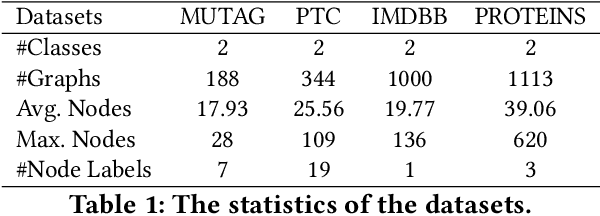
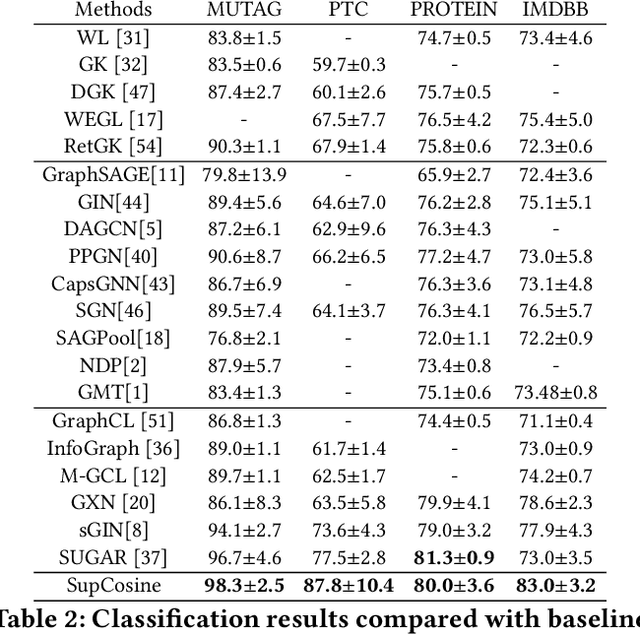
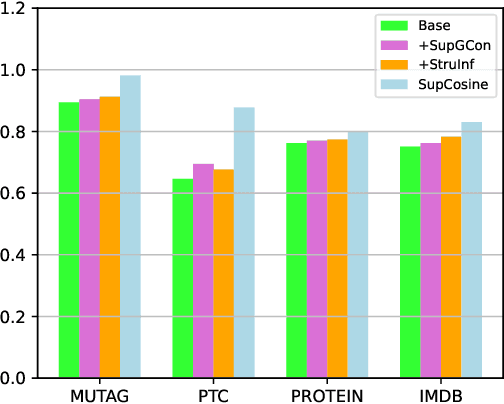
Advanced graph neural networks have shown great potentials in graph classification tasks recently. Different from node classification where node embeddings aggregated from local neighbors can be directly used to learn node labels, graph classification requires a hierarchical accumulation of different levels of topological information to generate discriminative graph embeddings. Still, how to fully explore graph structures and formulate an effective graph classification pipeline remains rudimentary. In this paper, we propose a novel graph neural network based on supervised contrastive learning with structure inference for graph classification. First, we propose a data-driven graph augmentation strategy that can discover additional connections to enhance the existing edge set. Concretely, we resort to a structure inference stage based on diffusion cascades to recover possible connections with high node similarities. Second, to improve the contrastive power of graph neural networks, we propose to use a supervised contrastive loss for graph classification. With the integration of label information, the one-vs-many contrastive learning can be extended to a many-vs-many setting, so that the graph-level embeddings with higher topological similarities will be pulled closer. The supervised contrastive loss and structure inference can be naturally incorporated within the hierarchical graph neural networks where the topological patterns can be fully explored to produce discriminative graph embeddings. Experiment results show the effectiveness of the proposed method compared with recent state-of-the-art methods.
Multi-task Self-distillation for Graph-based Semi-Supervised Learning
Dec 02, 2021



Graph convolutional networks have made great progress in graph-based semi-supervised learning. Existing methods mainly assume that nodes connected by graph edges are prone to have similar attributes and labels, so that the features smoothed by local graph structures can reveal the class similarities. However, there often exist mismatches between graph structures and labels in many real-world scenarios, where the structures may propagate misleading features or labels that eventually affect the model performance. In this paper, we propose a multi-task self-distillation framework that injects self-supervised learning and self-distillation into graph convolutional networks to separately address the mismatch problem from the structure side and the label side. First, we formulate a self-supervision pipeline based on pre-text tasks to capture different levels of similarities in graphs. The feature extraction process is encouraged to capture more complex proximity by jointly optimizing the pre-text task and the target task. Consequently, the local feature aggregations are improved from the structure side. Second, self-distillation uses soft labels of the model itself as additional supervision, which has similar effects as label smoothing. The knowledge from the classification pipeline and the self-supervision pipeline is collectively distilled to improve the generalization ability of the model from the label side. Experiment results show that the proposed method obtains remarkable performance gains under several classic graph convolutional architectures.
Latent Network Embedding via Adversarial Auto-encoders
Sep 30, 2021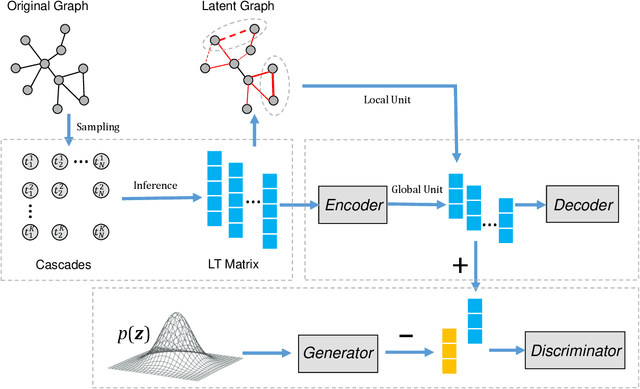
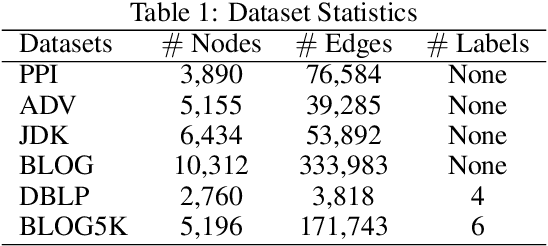
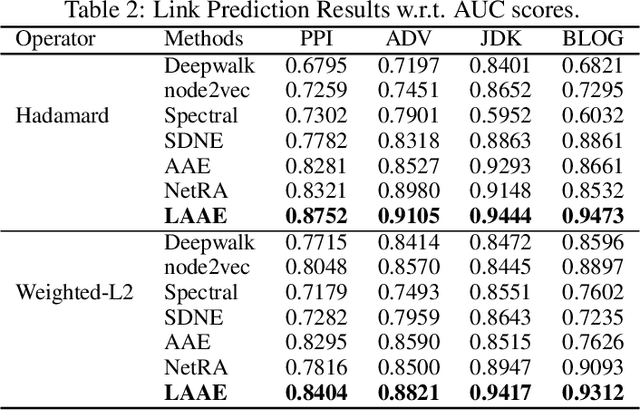
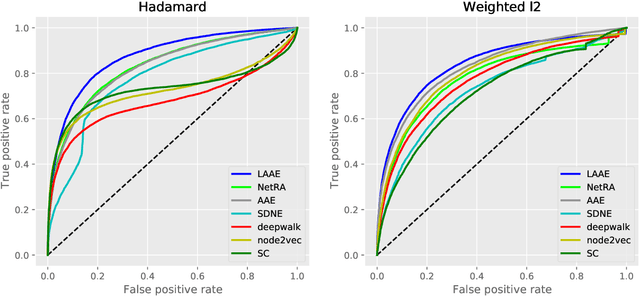
Graph auto-encoders have proved to be useful in network embedding task. However, current models only consider explicit structures and fail to explore the informative latent structures cohered in networks. To address this issue, we propose a latent network embedding model based on adversarial graph auto-encoders. Under this framework, the problem of discovering latent structures is formulated as inferring the latent ties from partial observations. A latent transmission matrix that describes the strengths of existing edges and latent ties is derived based on influence cascades sampled by simulating diffusion processes over networks. Besides, since the inference process may bring extra noises, we introduce an adversarial training that works as regularization to dislodge noises and improve the model robustness. Extensive experiments on link prediction and node classification tasks show that the proposed model achieves superior results compared with baseline models.
Diffusion Based Network Embedding
May 11, 2018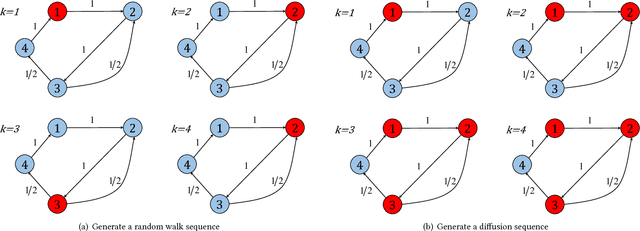
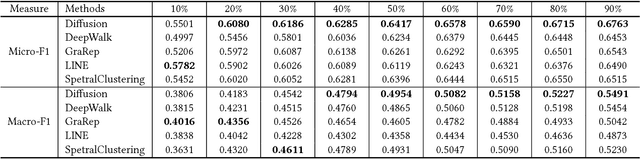
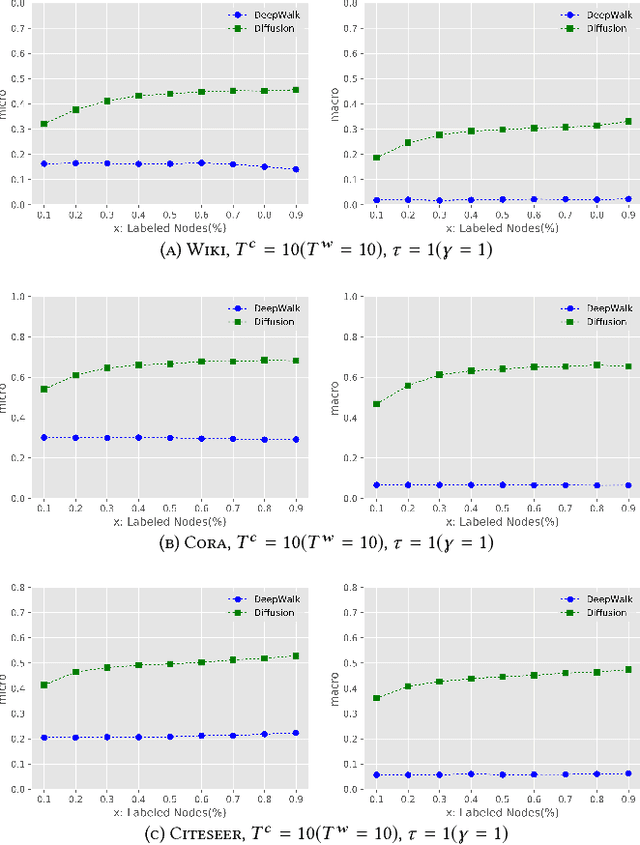
In network embedding, random walks play a fundamental role in preserving network structures. However, random walk based embedding methods have two limitations. First, random walk methods are fragile when the sampling frequency or the number of node sequences changes. Second, in disequilibrium networks such as highly biases networks, random walk methods often perform poorly due to the lack of global network information. In order to solve the limitations, we propose in this paper a network diffusion based embedding method. To solve the first limitation, our method employs a diffusion driven process to capture both depth information and breadth information. The time dimension is also attached to node sequences that can strengthen information preserving. To solve the second limitation, our method uses the network inference technique based on cascades to capture the global network information. To verify the performance, we conduct experiments on node classification tasks using the learned representations. Results show that compared with random walk based methods, diffusion based models are more robust when samplings under each node is rare. We also conduct experiments on a highly imbalanced network. Results shows that the proposed model are more robust under the biased network structure.